Data Cleaning With pandas and NumPy in Python
Data cleaning is an essential step in any data analysis project. Pandas and NumPy are two popular Python libraries that provide powerful tools for cleaning and manipulating data.
To get started with data cleaning using pandas and NumPy, you first need to import these libraries into your Python environment. You can do this using the following code:
dataset link
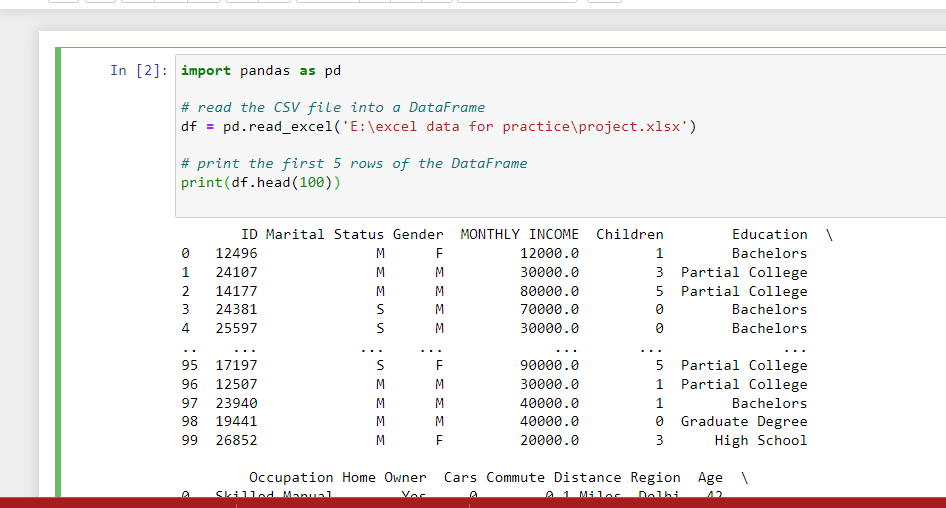
Table of Contents
ToggleImport CSV excel file
To import a CSV file in pandas Python, you can use the read_csv() function. This function is a part of the pandas library and is used to read a CSV file and create a pandas DataFrame object.
o import an Excel file in pandas, you can use the read_excel() function. This function is a part of the pandas library and is used to read an Excel file and create a pandas DataFrame object.
Here’s an example of how to import an Excel file using pandas:
head()
In pandas, head() is a method used to display the first few rows of a DataFrame. The method takes an optional argument n, which specifies the number of rows to be displayed. By default, n is set to 5, so calling head() without any arguments will display the first 5 rows of the DataFrame.
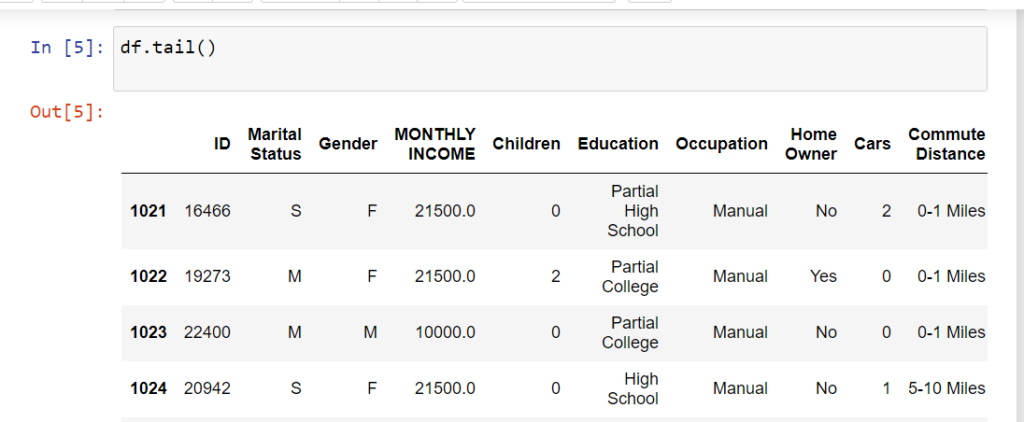
In pandas, tail() is a method used to display the last few rows of a DataFrame. The method takes an optional argument n, which specifies the number of rows to be displayed. By default, n is set to 5, so calling tail() without any arguments will display the last 5 rows of the DataFrame.
Selecting Particular rows in Pandas
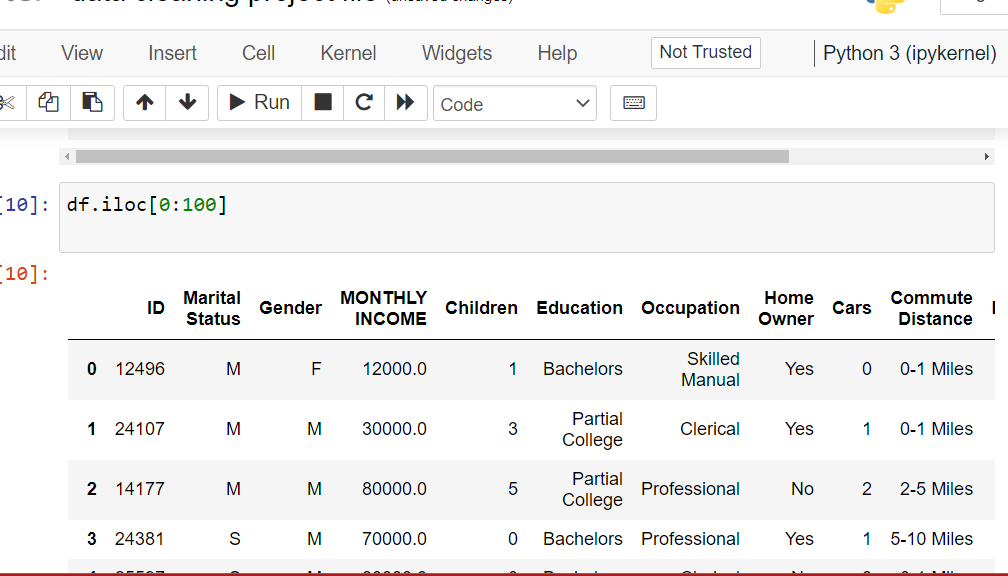
- Using integer indexing: You can use integer indexing to select a single row or a range of rows in a DataFrame. To select a single row, you can use the
ilocattribute and pass the row index as an integer. To select a range of rows, you can pass a slice object to theilocattribute.
How to get ascending and descending data in pandas
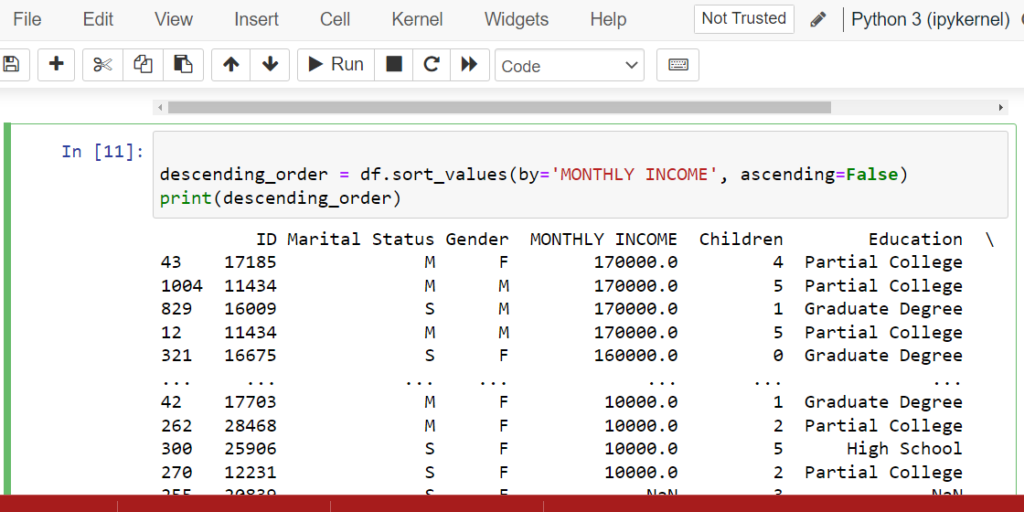
To sort data in ascending or descending order in Python, you can use the sort_values() method provided by pandas.
Here’s an example of how to sort data in ascending and descending order using pandas:
df.sort_index(axis=0,ascending=False)
descending_order = df.sort_values(by=’MONTHLY INCOME’, ascending=False)
print(descending_order)
isnull()
n Python, the isnull() function is a method provided by pandas library that checks if a value is missing or null. It returns a Boolean (True/False) value for each element in a pandas DataFrame or Series, indicating whether that element is null or not.
Here’s an example of how to use the isnull() method in pandas:
print(df.isnull())
second way to find data is
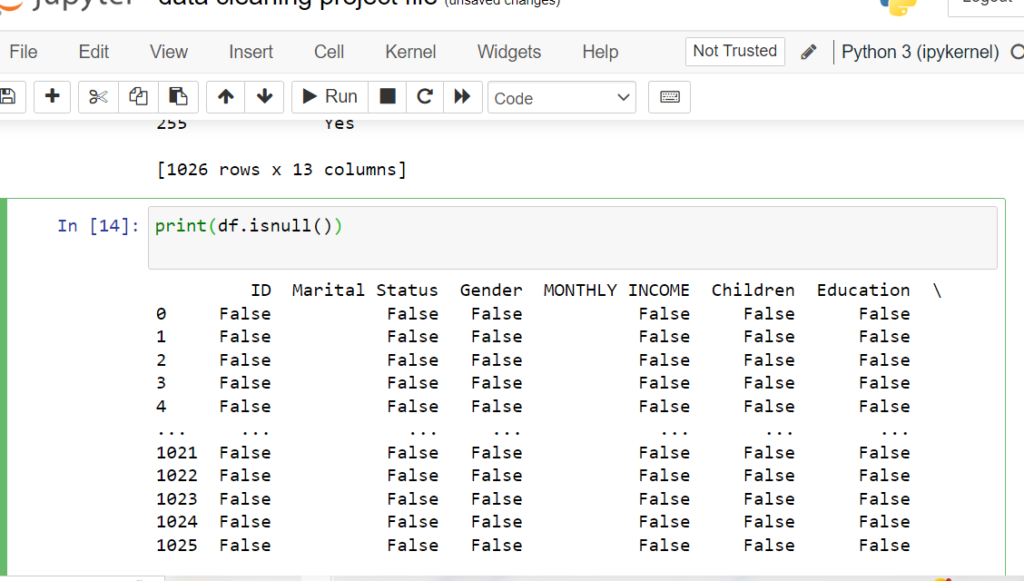
Find columns with missing values
To find columns with missing values in a dataset, you can follow these general steps:
- Load the dataset into a data structure (e.g., pandas DataFrame).
- Use the
isnull()function to create a boolean mask of the same shape as the dataset, where missing values are represented as True and non-missing values are represented as False. - Use the
any()function along the vertical axis (axis=0) to identify columns with at least one missing value, sinceTrueis interpreted as1andFalseas0. - Optionally, you can count the number of missing values per column by using the
sum()function along the vertical axis (axis=0) after step 2.
missing_rows = df[df.isnull().any(axis=1)]
# print the rows with missing values
print(missing_rows)
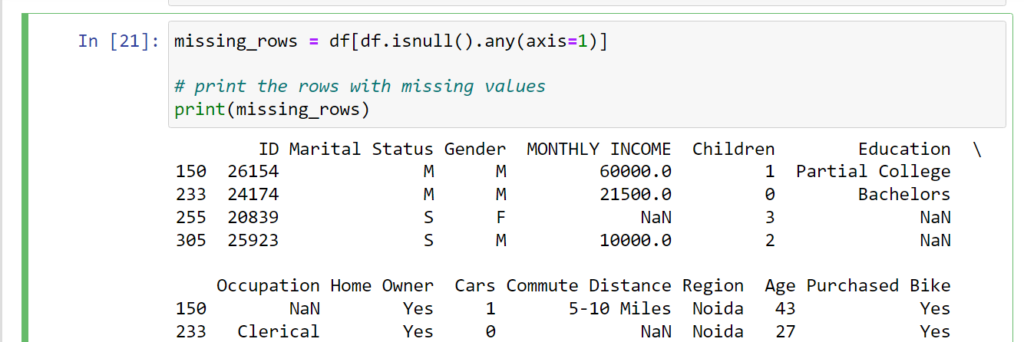
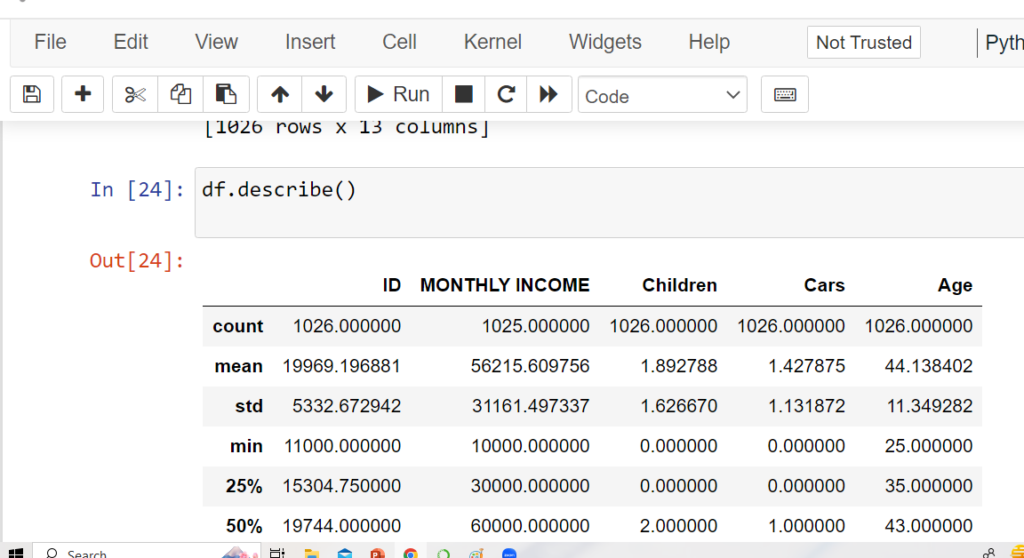
Describe in Pandas
The describe() method in pandas is used to generate descriptive statistics of a DataFrame or a Series. It returns a summary of the central tendency, dispersion, and shape of the distribution of a dataset. The output includes the following statistics:
- count: number of non-missing values
- mean: arithmetic mean
- std: standard deviation
- min: minimum value
- 25%: 25th percentile
- 50%: median or 50th percentile
- 75%: 75th percentile
- max: maximum value
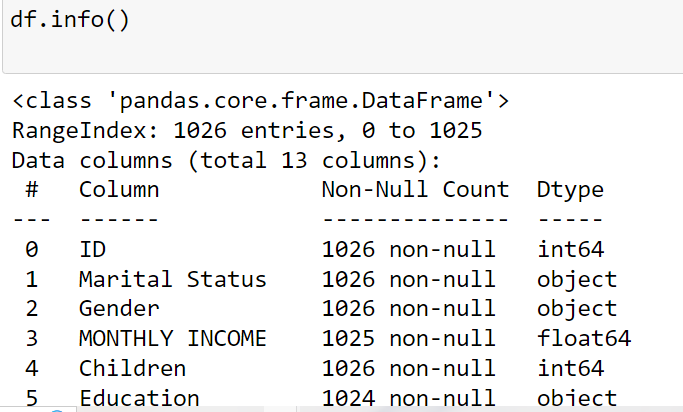
info()
In this example, we created a sample DataFrame with three columns: ‘Name’, ‘Age’, and ‘Country’. We then used the info() method on the DataFrame df to get a summary of its contents. The output includes the number of rows, number of columns, column names, data types of each column, memory usage, and the number of non-null values for each column. For example, the output might look like this
fillna function
The fillna() function in Pandas is used to fill missing values or NaN (Not a Number) values in a Pandas DataFrame or Series object. This function takes one or more arguments to specify how the missing values should be filled. Here are some common ways to use the fillna() function.
The fillna() function in Pandas is used to fill missing values or NaN (Not a Number) values in a Pandas DataFrame or Series object. This function takes one or more arguments to specify how the missing values should be filled. Here are some common ways to use the fillna() function:
Fill with a constant value: You can use the fillna() function to fill missing values with a constant value. For example, the following code will fill all missing values in the DataFrame df with the value 0:
python
code
df.fillna(0)
Forward or backward fill: You can use the fillna() function with the method argument to fill missing values with the previous or next value. For example, the following code will fill missing values in the DataFrame df with the previous value:
python
code
df.fillna(method=’ffill’)
Interpolate missing values: You can use the fillna() function with the method argument set to interpolate to fill missing values with interpolated values. For example, the following code will fill missing values in the DataFrame df with interpolated values:
python
code
df.interpolate()
Fill with mean or median: You can use the fillna() function with the value argument set to the mean or median value of the column to fill missing values with the mean or median value. For example, the following code will fill missing values in the DataFrame df with the mean value of the column:
python
Copy code
df.fillna(value=df.mean())
Fill using a custom function: You can also use a custom function with the fillna() function to fill missing values based on some condition. For example, the following code will fill missing values in the DataFrame df with the value returned by the custom function my_func():
python
code
df.fillna(value=my_func())
These are some common ways to use the fillna() function in Pandas. The fillna() function is a powerful tool for handling missing values in a Pandas DataFrame or Series object.
df[‘Education’] = df[‘Education’].fillna(value=’Partial College’, inplace=False)
Data cleaning, also known as data cleansing or data scrubbing, is the process of identifying and correcting or removing errors and inconsistencies in datasets to improve data quality and ensure it is suitable for analysis
Common data cleaning tasks include handling missing values, removing duplicates, correcting data types, standardizing formats, dealing with outliers, and handling inconsistencies in data.
Imputation is the process of filling in missing values with estimated or calculated values. You can use Pandas functions like fillna() or libraries like Scikit-Learn’s SimpleImputer for imputation.
You can handle missing values using libraries like Pandas by using functions like dropna() to remove rows with missing values, fillna() to fill missing values with a specified value, or by using techniques like interpolation or imputation.
You can remove duplicate rows in a Pandas DataFrame using the drop_duplicates() method.
Outliers are data points that deviate significantly from the rest of the data. You can detect and handle outliers using techniques such as Z-score, IQR (Interquartile Range), or visualization methods. Libraries like Scikit-Learn and Matplotlib can be helpful.