Exploring the Power of Python Libraries: A Deep Dive into Pandas
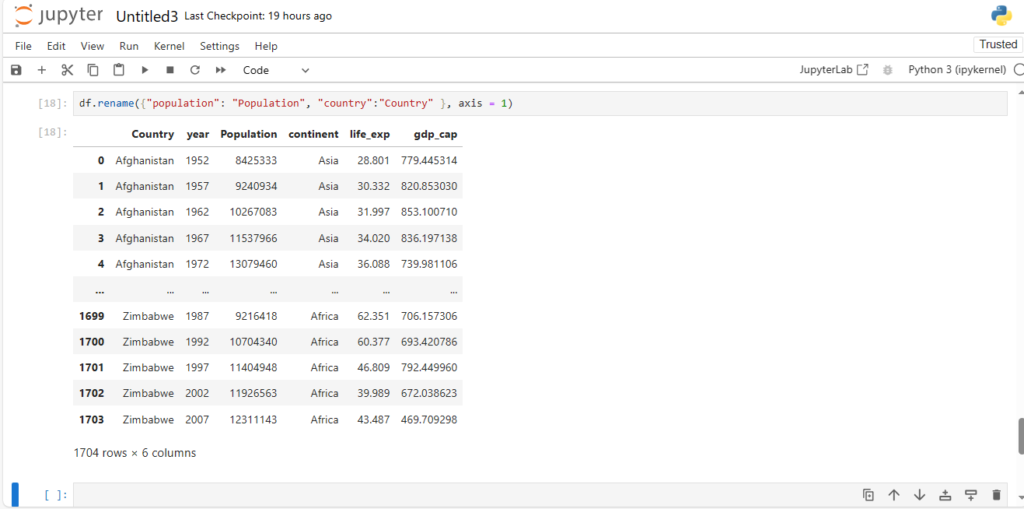
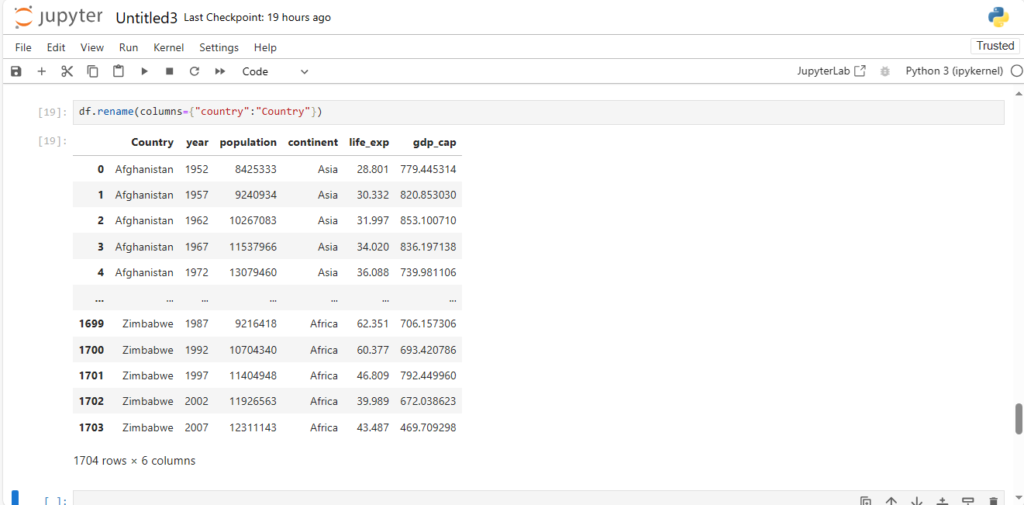
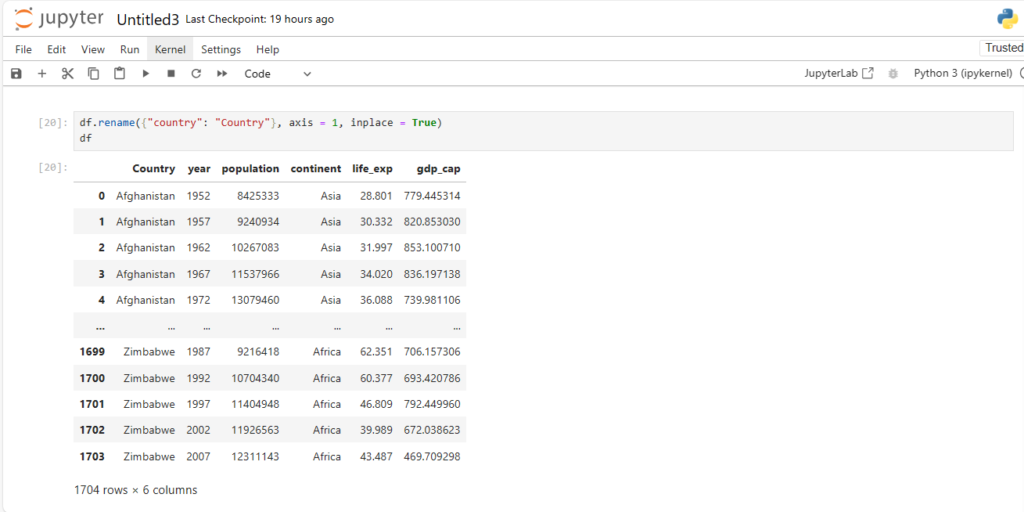
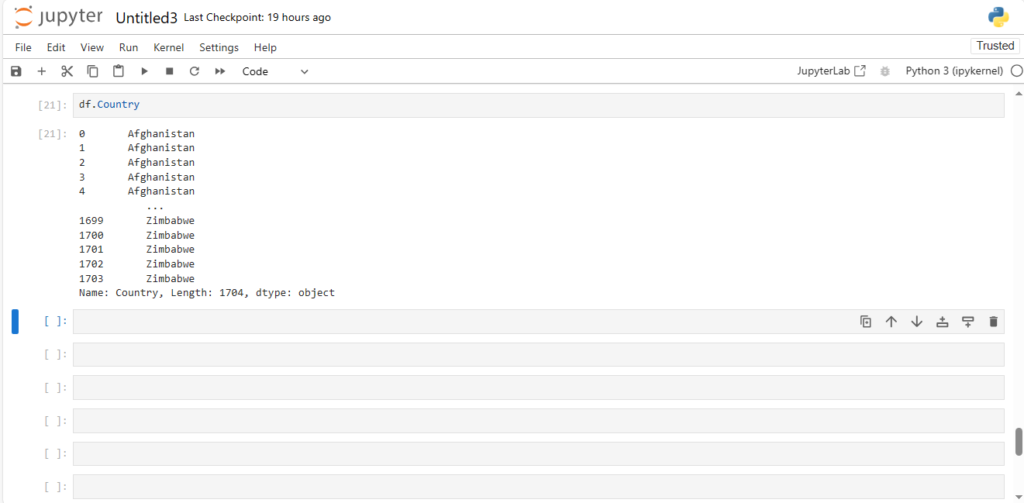
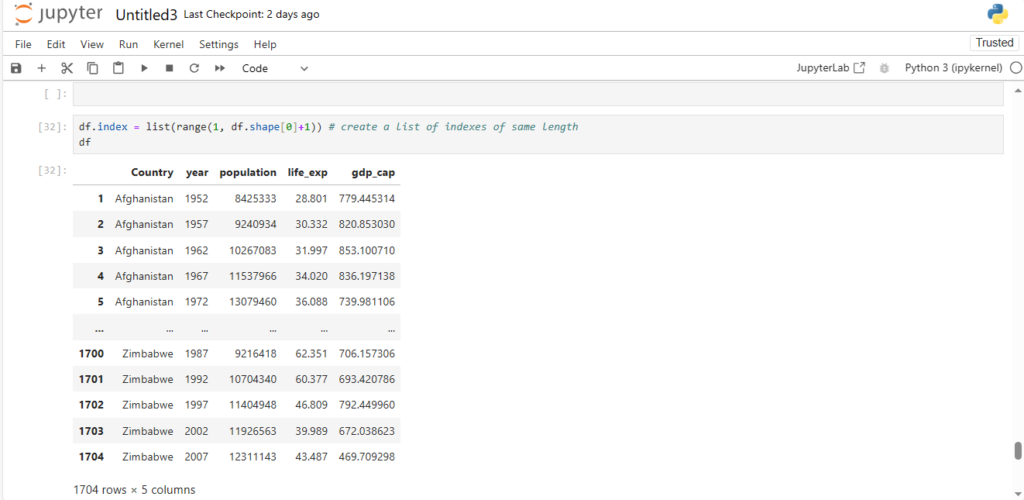
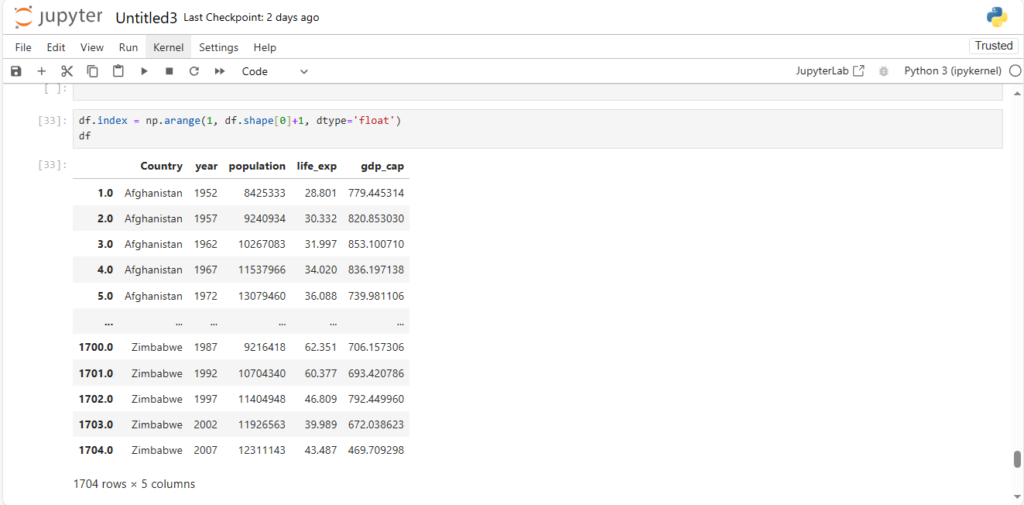
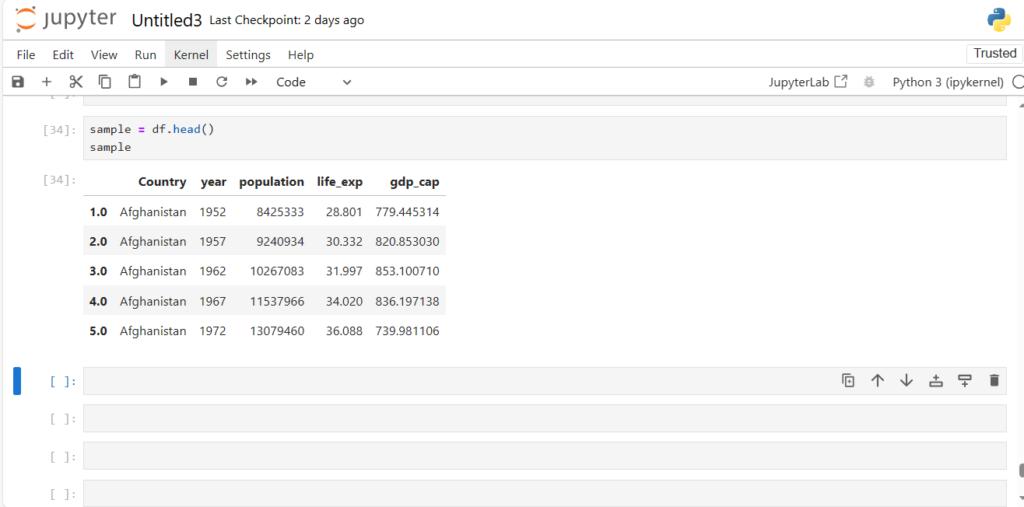
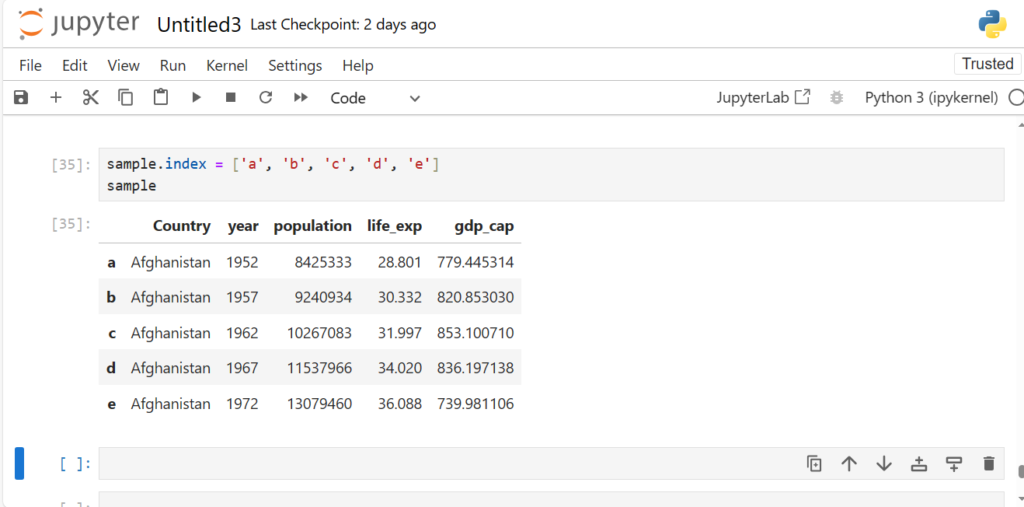
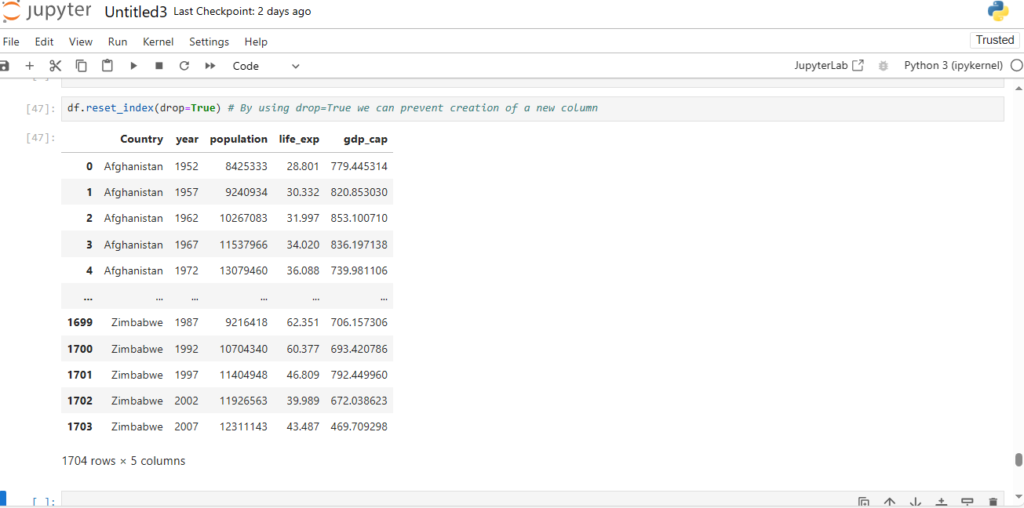
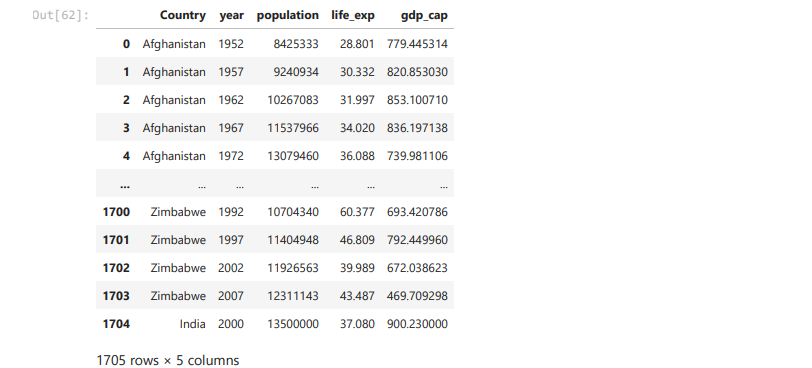
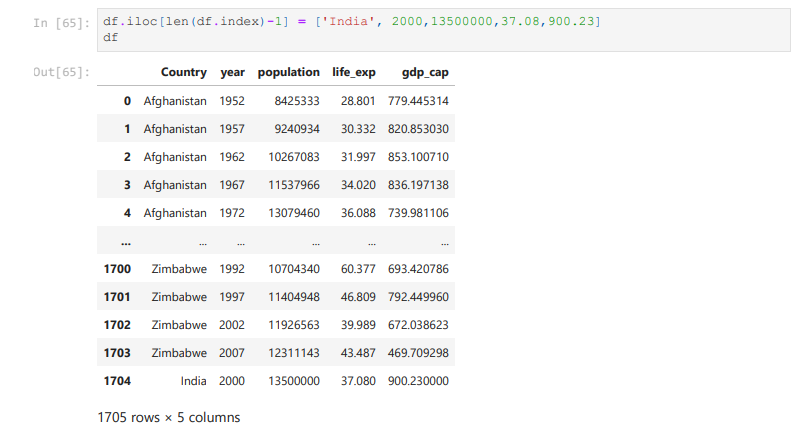
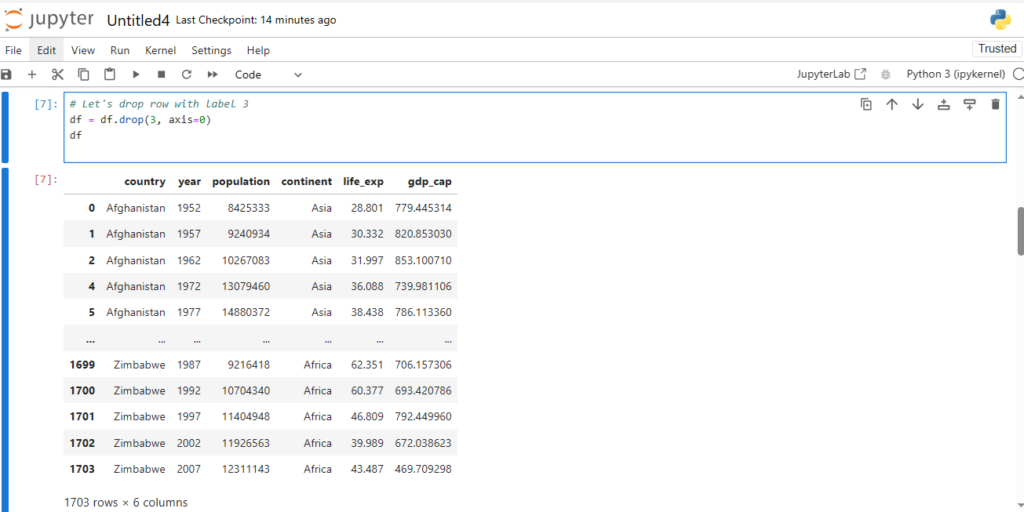
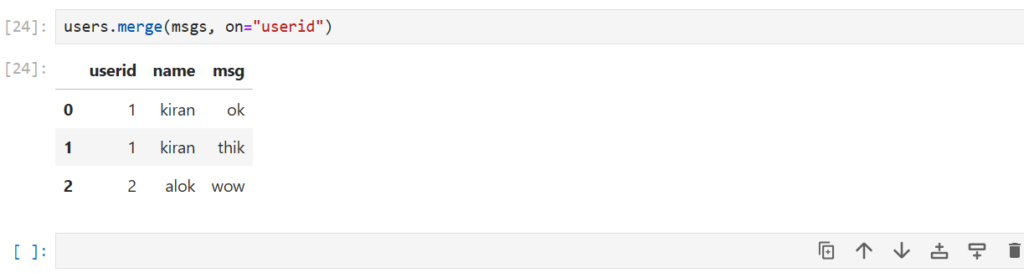
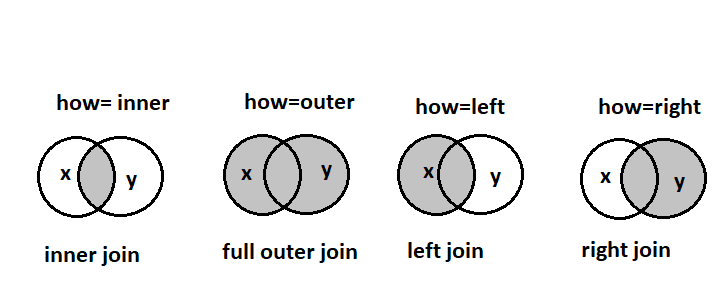
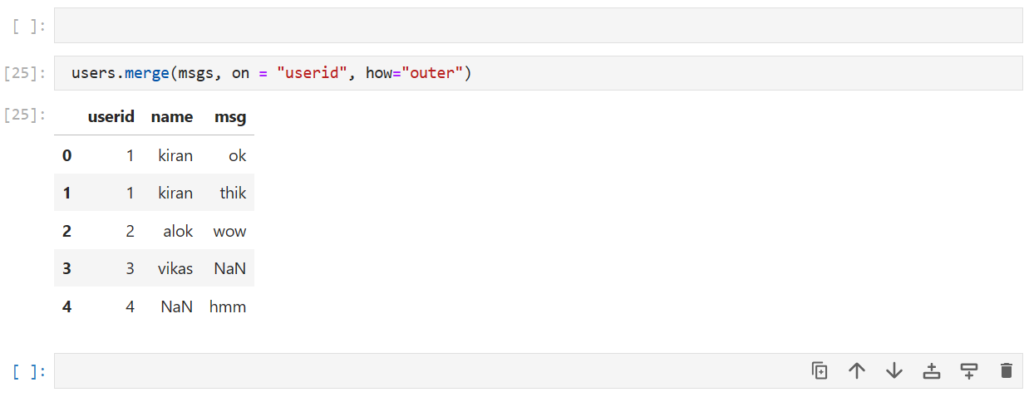
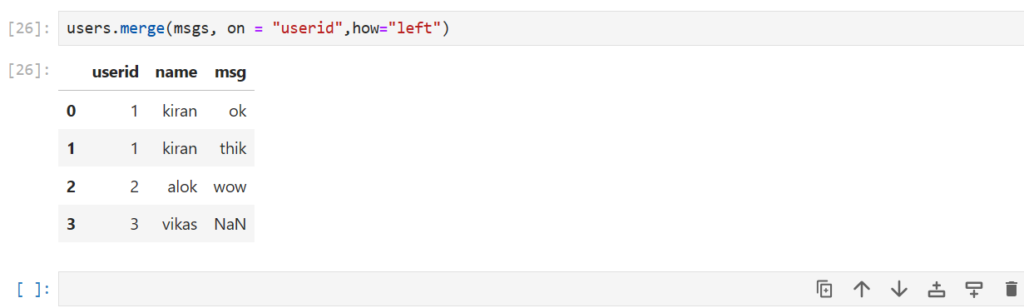
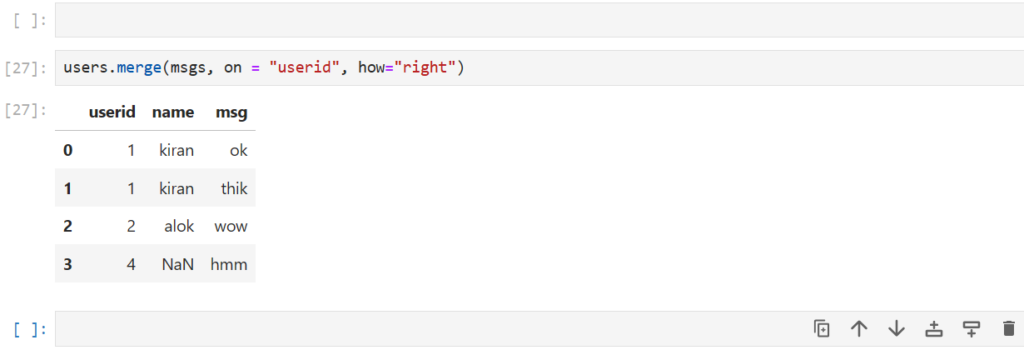
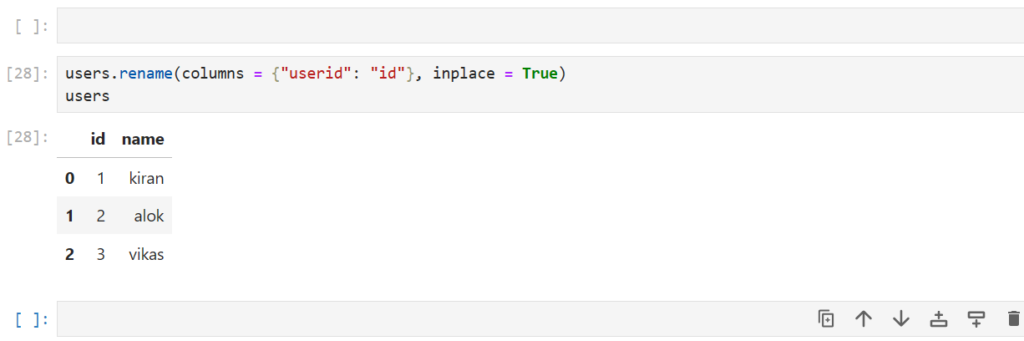
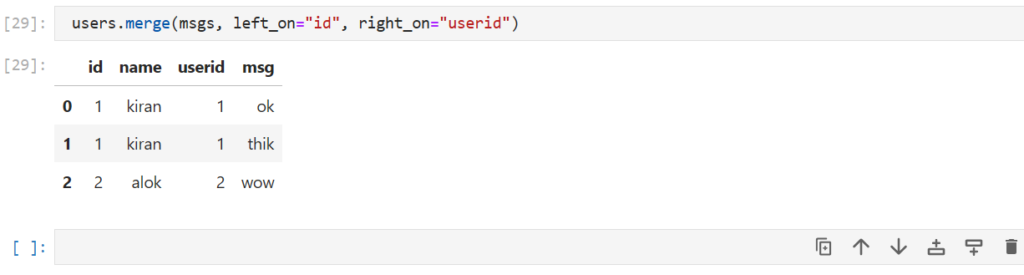
Data Analytics and Data Science institute in Dehradun Uttarakhand
Data Analytics and Data Science institute in Dehradun Uttarakhand