
Steps for Data Cleaning & Analysis in Data Analysis
Data cleaning, also known as data cleansing or data scrubbing, is the process of identifying and correcting or removing errors, inconsistencies, and inaccuracies in data. Effective data cleaning is a critical step in preparing data for analysis and training machine learning models. Data cleaning ensures that the data is accurate, complete, and consistent, which is essential for making informed decisions and producing reliable insights.
This blog will provide a comprehensive guide on how to effectively clean data for analysis and to train machine learning models. We will cover the following topics:
Table of Contents
Toggleunderstand the data you are working with
Before cleaning the data, it is important to understand the data you are working with. This includes understanding the data structure, the variables, and the values. Understanding the data will help you identify potential errors and inconsistencies, and determine the appropriate cleaning methods.
For example, let’s say you are working with a dataset that contains information on customer purchases. The dataset may include variables such as customer ID, purchase date, product name, price, and quantity. Before cleaning the data, you need to understand the structure of the data, such as the number of rows and columns, and the types of variables included.
You should also explore the data to identify any potential errors or inconsistencies. For example, you may notice that some of the purchase dates are in the future, indicating an error in the data. Additionally, you may notice that some of the product names are misspelled or inconsistent, which could impact the accuracy of the analysis.
Dealing with Missing Data
Missing data is a common problem in datasets, and can occur for a variety of reasons, such as data entry errors, system failures, or non-response. Missing data can impact the accuracy and reliability of analysis, and therefore, it is important to deal with missing data appropriately.
One way to deal with missing data is to remove the observations with missing data. However, this can result in a significant loss of information and can bias the analysis. Another approach is to impute the missing values, which involves replacing the missing values with estimated values.
There are several methods for imputing missing data, such as mean imputation, median imputation, and mode imputation. Mean imputation involves replacing missing values with the mean of the variable. Median imputation involves replacing missing values with the median of the variable. Mode imputation involves replacing missing values with the mode of the variable.
Handling Outliers
Outliers are observations that are significantly different from other observations in the dataset. Outliers can occur due to data entry errors, measurement errors, or unusual events. Outliers can impact the accuracy and reliability of analysis, and therefore, it is important to handle outliers appropriately.
One way to handle outliers is to remove the observations with outliers. However, this can result in a significant loss of information and can bias the analysis. Another approach is to transform the data, which involves converting the data to a different scale or distribution.
There are several methods for transforming data, such as log transformation, box-cox transformation, and z-score normalization. Log
Removing Duplicates
Duplicates can occur in a dataset due to data entry errors, system failures, or other reasons. Removing duplicates is essential to avoid bias in analysis and machine learning models. Identify duplicates by checking for identical observations and remove them using appropriate methods. For instance, you can use the drop_duplicates function in Python or the DISTINCT function in SQL.
Standardizing Data
Standardizing data involves scaling the data to have a mean of zero and a standard deviation of one. It’s crucial in analysis and machine learning models, especially when using distance-based algorithms.
Standardizing data helps to avoid variables with higher magnitudes dominating the analysis. Several methods for standardizing data exist, such as z- score normalization and min-max scaling.
Encoding Categorical Data
Categorical data refers to data that’s not numerical, such as colors or names. Machine learning algorithms require numerical data, and therefore, it’s essential to encode categorical data. There are several methods for encoding categorical data, such as one-hot encoding, label encoding, and binary encoding. Choose the most appropriate method for your dataset.
Feature Scaling
Feature scaling involves scaling features in the dataset to the same range or scale. It’s essential to avoid bias in analysis and machine learning models, especially when using distance-based algorithms. Several methods for feature scaling exist, such as z-score normalization, min-max scaling, and robust scaling.
Handling Imbalanced Data
Imbalanced data refers to a dataset with a disproportionate number of observations in different classes or categories. It can impact analysis accuracy and reliability, and therefore, it’s essential to handle it appropriately. Several methods for handling imbalanced data exist, such as oversampling, undersampling, and synthetic data generation. Choose the most appropriate method for your dataset.
Testing and Validating the Data
Testing and validating the data is essential to ensure that the cleaning process is successful. Testing involves splitting the dataset into training and testing datasets and applying the cleaning methods to both datasets.
Validating involves assessing the impact of the cleaning methods on analysis and machine learning models.
Choose appropriate validation methods, such as cross- validation or hold-out validation.
Conclusion
Effective data cleaning is a critical step in preparing data for analysis and training machine learning models.
Understanding
Example 1: Customer Purchase Dataset
Suppose you have a dataset containing customer purchases with missing values, outliers, and duplicates. Here’s how you can clean the data using the methodology outlined in the ebook:
Understanding the Data: Explore the dataset and identify potential errors and inconsistencies.
Dealing with Missing Data: Impute missing values using mean imputation for numerical variables and mode imputation for categorical variables.
Handling Outliers: Transform the data using log transformation for variables with highly skewed distributions.
Removing Duplicates: Identify duplicates by checking for identical observations and remove them using the drop_duplicates function in Python. Standardizing Data: Scale the data using z-score normalization to avoid variables with higher magnitudes dominating the analysis.
Encoding Categorical Data: Encode categorical variables using one-hot encoding.
Feature Scaling: Scale features in the dataset using min-max scaling to the same range or scale.
Handling Imbalanced Data: Handle imbalanced data using oversampling.
Testing and Validating the Data: Split the dataset into training and testing datasets and apply the cleaning methods to both datasets. Validate the impact of the cleaning methods on analysis and machine learning models using cross-validation.
Example Health Dataset
Suppose you have a health dataset containing missing values, outliers, and imbalanced data. Here’s how you can clean the data using the methodology outlined in the ebook:
Understanding the Data: Explore the dataset and identify potential errors and inconsistencies.
Dealing with Missing Data: Impute missing values using mean imputation for numerical variables and mode imputation for categorical variables.
Handling Outliers: Transform the data using z-score normalization for variables with highly skewed distributions.
Removing Duplicates: Identify duplicates by checking for identical observations and remove them using the DISTINCT function in SQL. Standardizing Data: Scale the data using min-max scaling to avoid variables with higher magnitudes dominating the analysis.
Encoding Categorical Data: Encode categorical variables using binary encoding.
Feature Scaling: Scale features in the dataset using robust scaling to handle outliers.
Handling Imbalanced Data: Handle imbalanced data using synthetic data generation.
Testing and Validating the Data: Split the dataset into training and testing datasets and apply the cleaning methods to both datasets. Validate the impact of the cleaning methods on analysis and machine learning models using hold-out validation.
By following these steps, you can effectively clean your data for analysis and training machine learning models. It’s important to note that the cleaning methods used will vary depending on the specific dataset and analysis goals. Therefore, it’s crucial to understand the data and choose appropriate cleaning methods accordingly.
Example with data set and python
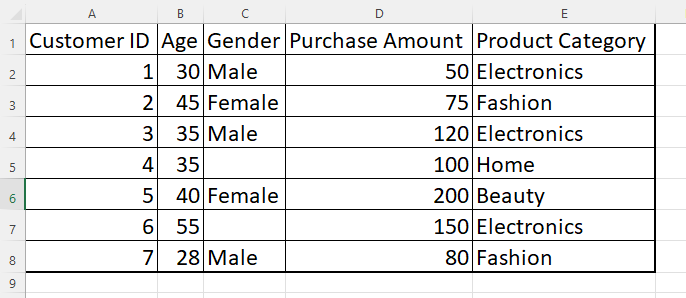
To perform data cleaning and analysis using Python, you can use various libraries such as Pandas, NumPy, and Matplotlib. Here’s an example of how you can apply the mentioned steps to the dataset using Python:
Step 1: Import the required libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Step 2: Load the dataset into a Pandas DataFrame:
df = pd.read_csv('dataset.csv') # Replace 'dataset.csv' with the actual file path Step 3: Dealing with Missing Data:
# Replace missing values in 'Age' column with the median age
median_age = df['Age'].median()
df['Age'].fillna(median_age, inplace=True)
# Replace missing values in 'Purchase Amount' column with the mean purchase amount
mean_purchase = df['Purchase Amount'].mean()
df['Purchase Amount'].fillna(mean_purchase, inplace=True)
Removing Duplicates:
df.drop_duplicates(subset='Customer ID', inplace=True)
Encoding Categorical Data
df = pd.get_dummies(df, columns=['Gender'])
Feature Scaling:
# Standardize 'Purchase Amount' using z-score
df['Purchase Amount'] = (df['Purchase Amount'] - df['Purchase Amount'].mean()) / df['Purchase Amount'].std()
Handling Imbalanced Data:
# Apply techniques like oversampling or undersampling to balance the data if necessary
# Example: Oversampling the minority class
from sklearn.utils import resample
df_majority = df[df['Product Category'] == 'Electronics']
df_minority = df[df['Product Category'] == 'Home']
df_minority_oversampled = resample(df_minority, replace=True, n_samples=len(df_majority), random_state=42)
df_balanced = pd.concat([df_majority, df_minority_oversampled])
Testing and Validating the Data
# Split the dataset into training and testing subsets
from sklearn.model_selection import train_test_split
X = df.drop(['Product Category'], axis=1)
y = df['Product Category']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)