Unlocking the Hidden Mysteries of Data with Seaborn’s Visual Storytelling

Seaborn is a powerful data visualization library built on top of Matplotlib, a widely used Python library for creating plots and graphs. It provides a high-level interface for creating beautiful and informative statistical graphics, making data visualization more accessible and intuitive for Python users.
Here are some of the key advantages of using Seaborn for data visualization:
- Simplified Plot Creation: Seaborn offers a concise and user-friendly interface for generating common statistical plots, reducing the amount of code required compared to Matplotlib.
- Seamless Matplotlib Integration: Seaborn seamlessly integrates with Matplotlib, allowing you to leverage Matplotlib’s extensive customization options while benefiting from Seaborn’s higher-level abstractions.
- Aesthetically Appealing Plots: Seaborn produces visually appealing plots with default styling guidelines that enhance data comprehension and readability.
- Statistical Functions and Tools: Seaborn incorporates statistical functions and tools, such as correlation analysis and linear regression, within the visualization context, facilitating data exploration and understanding.
- Thematic Styling and Consistency: Seaborn provides a variety of themes for consistent styling across plots, ensuring visual coherence and enhancing the overall presentation of your data.
- Faceting and Subplotting: Seaborn supports faceting and subplotting, enabling you to visualize data by subgroups or multiple plots within a single figure, providing a more comprehensive view of your data.
- Statistical Analysis Integration: Seaborn seamlessly integrates statistical analysis with visualization, allowing you to explore and understand data patterns simultaneously, facilitating a deeper understanding of your data.
In summary, Seaborn’s versatility, ease of use, and ability to produce aesthetically pleasing and informative statistical graphics make it an invaluable tool for data scientists, analysts, and anyone who wants to effectively communicate data insights through compelling visualizations.
Getting Started with Seaborn:
- Installation: Install Seaborn using pip: pip install seaborn
- Import Seaborn: Import Seaborn in your Python script: import seaborn as sns
- Explore Data and Create Plots: Use Seaborn functions to explore your data and generate plots:
# Load data data = ... # Create a histogram sns.histplot(data['column_name'])
Univariate Distribution Plots: Histograms, kernel density plots, violin plots
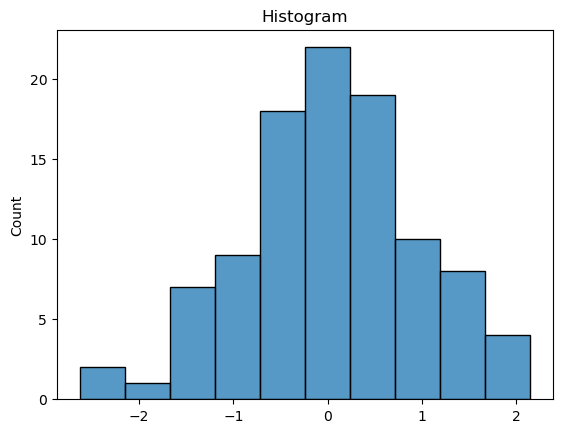
Histograms:
Histograms are bar charts that represent the frequency distribution of a quantitative variable. They divide the data into bins or intervals and count the number of data points that fall within each bin. Histograms provide a visual representation of the data’s distribution, revealing its shape, central tendency, and spread.Kernel Density Plots:
Kernel density plots, also known as density curves, provide a more continuous representation of the data’s distribution compared to histograms. They estimate the probability density function (PDF) of the data using a kernel function, which is a smooth bell-shaped curve. Kernel density plots effectively capture the underlying shape of the data, including its modes, skewness, and kurtosis.Violin Plots:
Violin plots combine box plots with kernel density estimates to provide a comprehensive overview of the distribution of a quantitative variable. They display the median, quartiles, and extreme values using a boxplot-like structure, while the kernel density estimate around the boxplot represents the distribution of the data within each quartile. Violin plots are particularly useful for comparing the distributions of a variable across different groups or categories. Choosing the Right Univariate Distribution Plot: The choice of univariate distribution plot depends on the specific characteristics of the data and the desired level of detail.- Histograms: Histograms are suitable for exploring the frequency distribution and identifying potential outliers.
- Kernel Density Plots: Kernel density plots are effective for capturing the overall shape and density of the data, revealing its underlying structure.
- Violin Plots: Violin plots are useful for comparing distributions across groups, providing a combined view of central tendency, spread, and density.
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# Generate some sample data
data = np.random.randn(100)
# Create a list of plot types
plot_types = ['histogram', 'kernel_density', 'violin']
# Iterate through the list of plot types and create the corresponding plots
for plot_type in plot_types:
if plot_type == 'histogram':
sns.histplot(data)
plt.title('Histogram')
plt.show()
elif plot_type == 'kernel_density':
sns.kdeplot(data)
plt.title('Kernel Density Plot')
plt.show()
elif plot_type == 'violin':
sns.violinplot(x=data)
plt.title('Violin Plot')
plt.show()
Bivariate Relationship Plots: Scatterplots, line plots, correlation matrices
Scatterplots:
Purpose:
A scatterplot is used to visualize the relationship between two continuous variables. It displays individual data points on a two-dimensional graph, where each point represents a pair of values for the two variables.
Representation:
Points are scattered on the graph, and the position of each point corresponds to the values of the two variables. The pattern of points can provide insights into the nature and strength of the relationship between the variables (e.g., positive correlation, negative correlation, or no correlation).
Seaborn Function:
In Seaborn, the scatterplot function is commonly used for creating scatterplots.
Line Plots:
Purpose:
Line plots (or line charts) are used to visualize the trend or pattern of a variable over a continuous interval or time. They are especially useful for displaying changes in a variable’s value over a sequential range.
Representation: A line is drawn connecting points corresponding to the variable’s values. This helps in identifying trends, patterns, or fluctuations in the data.
Seaborn Function:
In Seaborn, the lineplot function is commonly used for creating line plots.
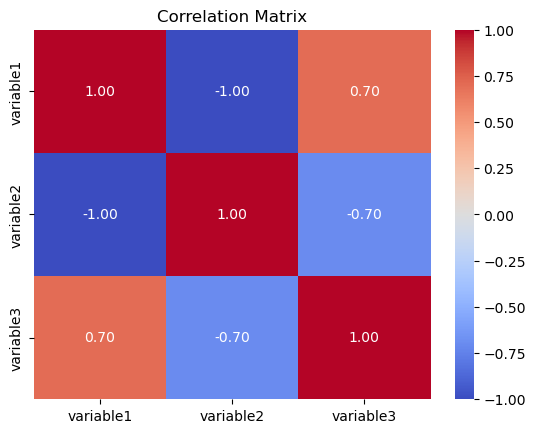
Correlation Matrices:
Purpose:
A correlation matrix is used to examine the strength and direction of the linear relationship between multiple variables. It shows pairwise correlations between variables, providing insights into how changes in one variable relate to changes in another.
Representation:
The matrix is a square grid where each cell represents the correlation coefficient between two variables. Values close to 1 indicate a strong positive correlation, values close to -1 indicate a strong negative correlation, and values close to 0 indicate a weak or no correlation.
Seaborn Function:
In Seaborn, the heatmap function is often used to create a visually appealing representation of the correlation matrix.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Example data
data = {‘variable1’: [1, 2, 3, 4, 5],
‘variable2’: [5, 4, 3, 2, 1],
‘variable3′: [2, 3, 1, 4, 5]}
df = pd.DataFrame(data)
# Scatterplot
sns.scatterplot(x=’variable1′, y=’variable2’, data=df)
plt.title(‘Scatterplot’)
plt.xlabel(‘Variable 1’)
plt.ylabel(‘Variable 2′)
plt.show()
# Line Plot
sns.lineplot(x=’variable1′, y=’variable2’, data=df)
plt.title(‘Line Plot’)
plt.xlabel(‘Variable 1’)
plt.ylabel(‘Variable 2′)
plt.show()
# Correlation Matrix
correlation_matrix = df.corr()
sns.heatmap(correlation_matrix, annot=True, cmap=’coolwarm’, fmt=”.2f”)
plt.title(‘Correlation Matrix’)
plt.show()
Categorical Data Plots: Bar charts, boxplots, boxenplots
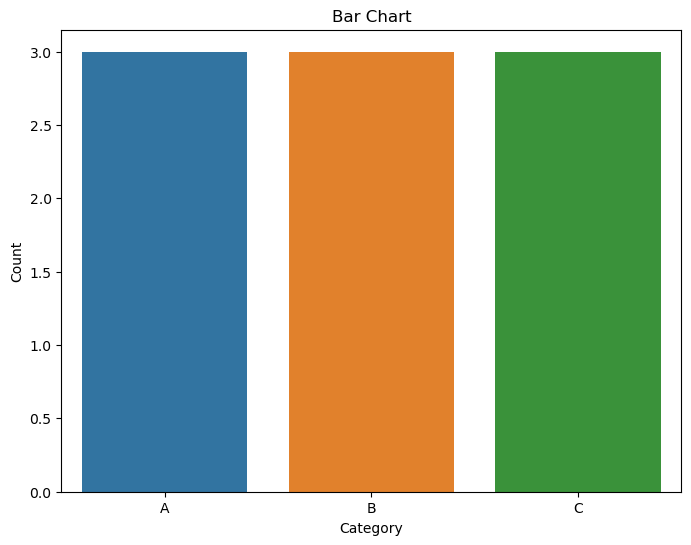
Bar Charts:
Purpose:
Bar charts are used to display the distribution of a categorical variable by representing the frequencies or proportions of each category.
Representation:
Categories are shown on one axis (usually the x-axis for vertical bars) and their corresponding frequencies or proportions on the other axis.
Seaborn Function:
The countplot function is commonly used for creating bar charts.
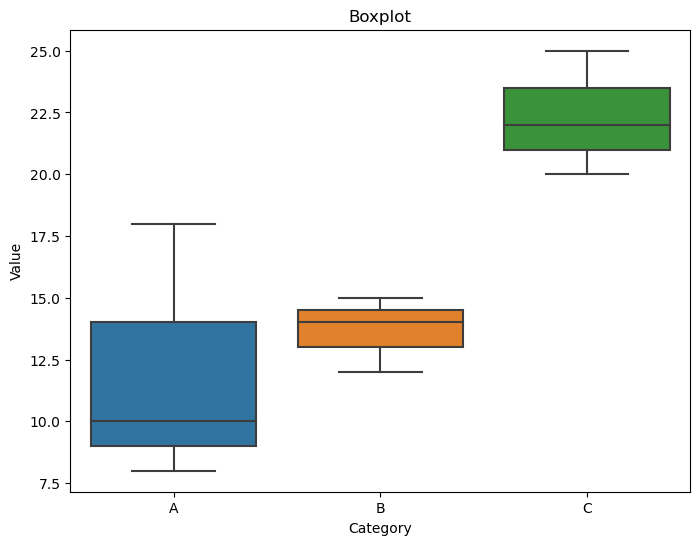
Boxplots:
Purpose:
Boxplots (or box-and-whisker plots) are useful for visualizing the distribution of a continuous variable within different categories. They show the median, quartiles, and potential outliers of the data.
Representation:
A box is drawn representing the interquartile range (IQR), with a line inside indicating the median. Whiskers extend to the minimum and maximum values within a certain range.
Seaborn Function:
The boxplot function can be used for creating boxplots.
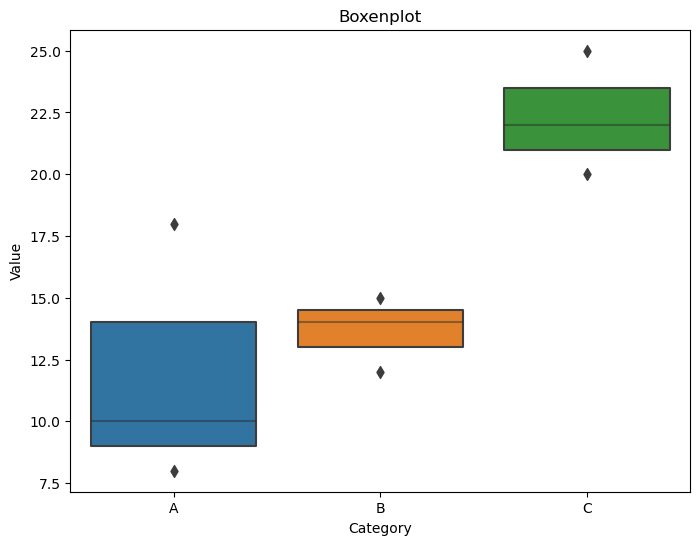
Boxenplots:
Purpose:
Boxenplots (or letter-value plots) are similar to boxplots but are more detailed, especially for larger datasets. They show additional information about the tails of the distribution.
Representation:
Similar to boxplots, but with more notches and detailed information about the tails of the distribution.
Seaborn Function:
The boxenplot function is used for creating boxenplots.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Example data
data = {'category': ['A', 'B', 'A', 'C', 'B', 'A', 'C', 'B', 'C'],
'value': [10, 15, 8, 20, 12, 18, 22, 14, 25]}
df = pd.DataFrame(data)
# Bar Chart
plt.figure(figsize=(8, 6))
sns.countplot(x='category', data=df)
plt.title('Bar Chart')
plt.xlabel('Category')
plt.ylabel('Count')
plt.show()
# Boxplot
plt.figure(figsize=(8, 6))
sns.boxplot(x='category', y='value', data=df)
plt.title('Boxplot')
plt.xlabel('Category')
plt.ylabel('Value')
plt.show()
# Boxenplot
plt.figure(figsize=(8, 6))
sns.boxenplot(x='category', y='value', data=df)
plt.title('Boxenplot')
plt.xlabel('Category')
plt.ylabel('Value')
plt.show()
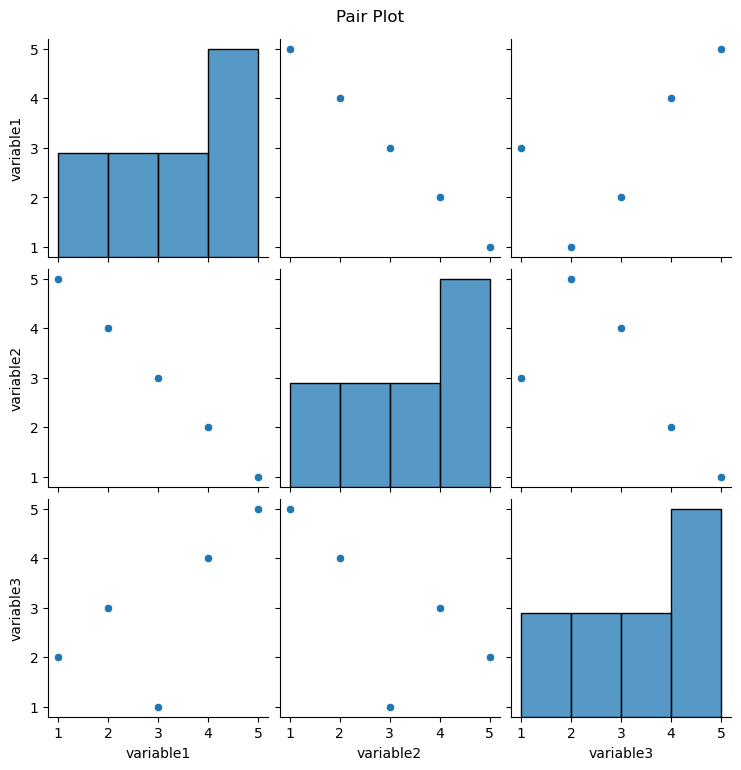
Pair plots, joint plots, clustermaps
Pair Plots:
Purpose:
Pair plots are used to visualize pairwise relationships between multiple variables in a dataset. It shows scatterplots for each pair of variables along the diagonal and histograms on the off-diagonal to represent the distribution of each variable.
Representation:
The diagonal shows the univariate distribution of each variable, and the scatterplots on the lower and upper triangles show bivariate relationships.
Seaborn Function: The pairplot function is commonly used for creating pair plots.
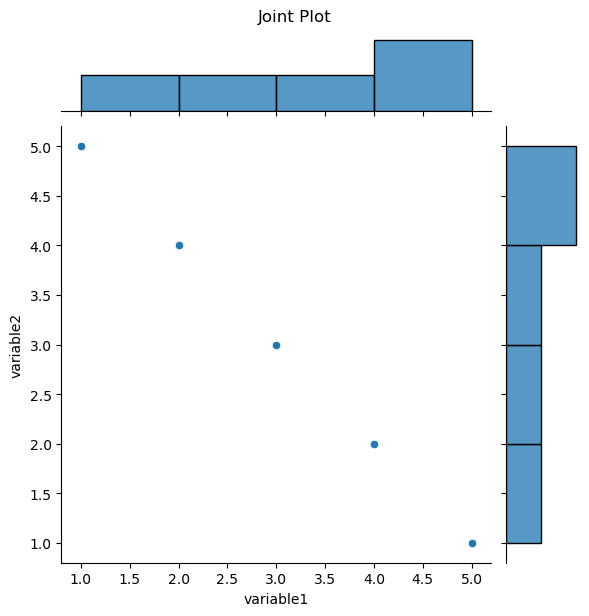
Joint Plots:
Purpose:
Joint plots are used to visualize the relationship between two variables, including the distribution of each variable and a scatterplot of the two variables.
Representation:
It combines a scatterplot with histograms along the axes, providing a comprehensive view of the relationship and marginal distributions.
Seaborn Function: The jointplot function is used for creating joint plots.
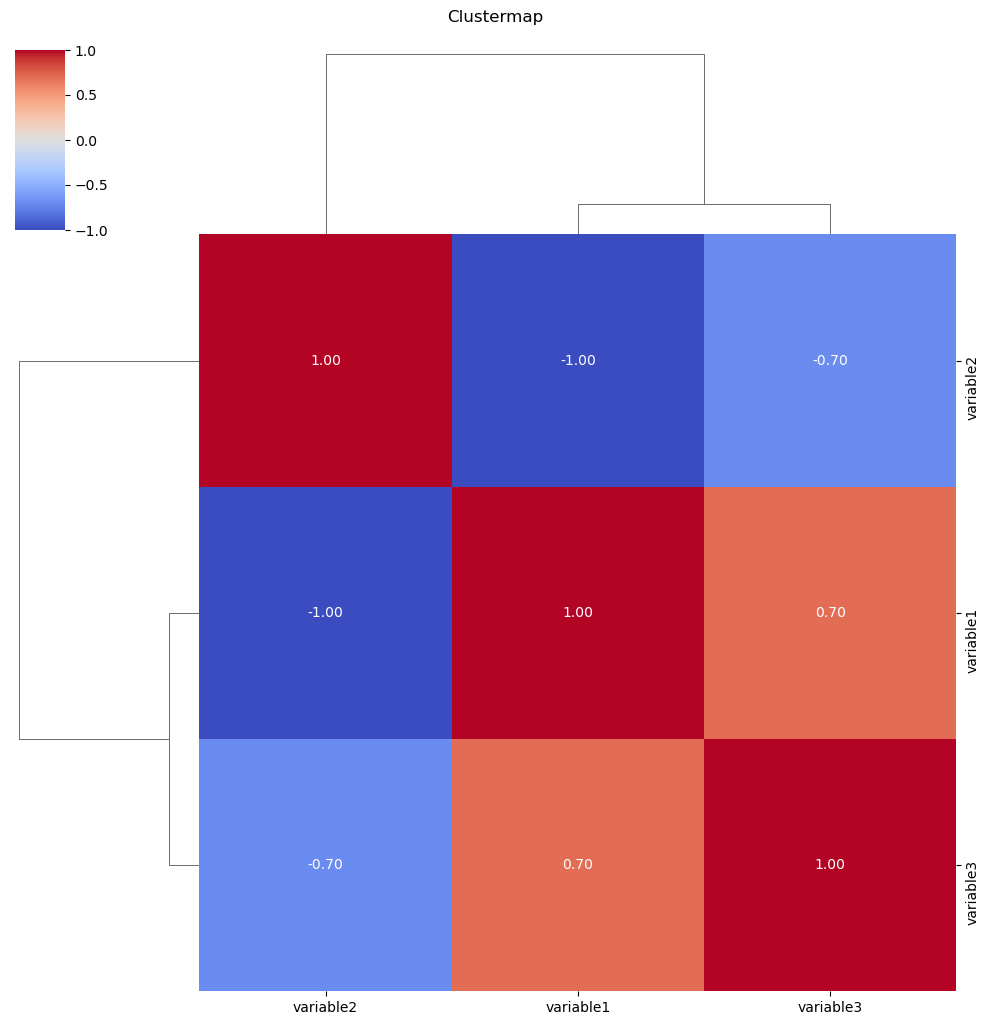
Clustermaps:
Purpose:
Clustermaps are used to visualize the relationships between variables and cluster them based on similarity. It’s particularly useful for exploring patterns in large datasets
.
Representation:
The clustermap arranges variables in rows and columns and colors cells based on the similarity of values. Hierarchical clustering is often applied to group similar variables together.
Seaborn Function:
The clustermap function is used for creating clustermaps.
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# Example data
data = {‘variable1’: [1, 2, 3, 4, 5],
‘variable2’: [5, 4, 3, 2, 1],
‘variable3’: [2, 3, 1, 4, 5]}
df = pd.DataFrame(data)
# Pair Plot
plt.figure(figsize=(10, 8))
sns.pairplot(df)
plt.suptitle(‘Pair Plot’, y=1.02)
plt.show()
# Joint Plot
plt.figure(figsize=(8, 6))
sns.jointplot(x=’variable1′, y=’variable2′, data=df, kind=’scatter’)
plt.suptitle(‘Joint Plot’, y=1.02)
plt.show()
# Clustermap
plt.figure(figsize=(8, 6))
sns.clustermap(df.corr(), annot=True, cmap=’coolwarm’, fmt=”.2f”)
plt.suptitle(‘Clustermap’, y=1.02)
plt.show()