
Top Data Analytics Interview Question and Answer 2023
Table of Contents
ToggleCommon data analytics interview question
What do data analysts do?
A data analyst reviews data to identify key insights into a business’s customers and ways the data can be used to solve problems. They also communicate this information to company leadership and other stakeholders.
What is data wrangling?
Data Wrangling is the process of cleaning data from raw data so it can be converted into a structured and desirable format so it can be used for decision-making.
Large amounts of data that have been taken from several sources can be turned into a more usable format using this technique. The data is analyzed using methods like merging, grouping, concatenating, joining, and sorting. After that, it prepares to be utilised with a different dataset.
What is your process for cleaning data?
While the techniques used for data cleaning may vary according to the types of data your company stores, you can follow these basic steps
Step 1: Remove duplicate or irrelevant observations
Remove unwanted observations from your dataset, including duplicate observations or irrelevant observations
Step 2: Fix structural errors
When you measure or transfer data and find odd naming practises, mistakes, or wrong capitalization, such are structural faults. Mislabeled categories or classes may result from these inconsistencies. For instance, you might see both “N/A” and “Not Applicable” appear; nonetheless, they should be considered to be part of the same category.
Step 3: Filter unwanted outliers
Often, there will be one-off observations where, at a glance, they do not appear to fit within the data you are analyzing. If you have a legitimate reason to remove an outlier, like improper data-entry, doing so will help the performance of the data you are working with.
Step 4: Handle missing data
As a first option, you can drop observations that have missing values, but doing this will drop or lose information, so be mindful of this before you remove it.
As a second option, you can input missing values based on other observations; again, there is an opportunity to lose integrity of the data because you may be operating from assumptions and not actual observations.
As a third option, you might alter the way the data is used to effectively navigate null values.
What is the difference between Data Mining and Data Profiling?
Data Profiling
Data Profiling is a process of evaluating data from an existing source and analyzing and summarizing useful information about that data.
Data mining
Data mining refers to a process of analyzing the gathered information and collecting insights and statistics about the data. It is also called data archaeology.
What is the data analysis process?
Data Analytics is the process of collecting, cleaning, sorting, and processing raw data to extract relevant and valuable information to help businesses. An in-depth understanding of data can improve customer experience, retention, targeting, reducing operational costs, and problem-solving methods.
What do you mean by data visualization?
Data visualization is the graphical representation of information and data. By using visual elements like charts, graphs, and maps, data visualization tools provide an accessible way to see and understand trends, outliers, and patterns in data
What are some of the common problems Data analytics faces?
- Inability to define user requirements properly.
- Carrying out system changes without considering the impact on data of other departments.
- Lack of a unified corporate picture.
- Collecting meaningful data to the agreed standard
What is the significance of Exploratory Data Analysis (EDA)?
The main purpose of EDA is to help look at data before making any assumptions. It can help identify obvious errors, as well as better understand patterns within the data, detect outliers or anomalous events, find interesting relations among the variables.
What is the difference between descriptive, predictive, and prescriptive analytics?
Descriptive | Predictive | Prescriptive |
It answers the question “what has happened” by offering historical data. | knows what might happen in the future to provide insight | Suggest various courses of action to answer “what should you do” |
Uses data aggregation and data mining techniques | utilises forecasting methods and statistical models | advises potential outcomes using modeling techniques and optimization strategies. |
For instance, you could utilize descriptive analytics to identify the apparel categories that are selling well and those that are not, or to determine the locations with the highest sales. Descriptive analytics can also be used to understand consumer behavior, such as which client categories are purchasing particular goods. | Predictive analytics can be used, for instance, to forecast sales for the upcoming quarter or to identify the clients who are most likely to purchase a specific product. By revealing potential future outcomes, predictive analytics can assist you in making smarter business decisions. | The best inventory levels for each product at each location are suggested by a grocery store using data on sales, weather trends, and other variables. Making data-driven decisions about inventory management, cutting waste, and boosting earnings is done using this paradigm. |
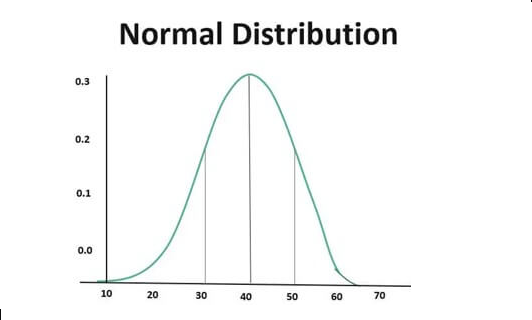
What is normal Distribution?
A normal distribution refers to a probability distribution where the values of a random variable are distributed symmetrically. These values are equally distributed on the left and the right side of the central tendency. Thus, a bell-shaped curve is formed.
What is Time Series Analysis ?
Time series analysis is a specific way of analyzing a sequence of data points collected over an interval of time. In time series analysis, analysts record data points at consistent intervals over a set period of time rather than just recording the data points intermittently or randomly.
Data Analyst Interview Questions: Excel
What is the difference between CountA, CountBlank, and CountIf in Excel?
COUNT function returns the count of numeric cells in a range
COUNTA function counts the non-blank cells in a range
COUNTBLANK function gives the count of blank cells in a range
COUNTIF function returns the count of values by checking a given condition
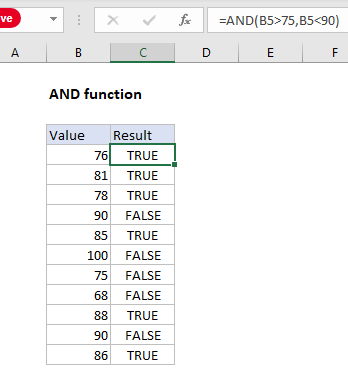
How do and functions work in Excel?
The AND function is used to check more than one logical condition at the same time.
The AND function returns TRUE if all its arguments evaluate to TRUE, and returns FALSE if one or more arguments evaluate to FALSE. One common use for the AND function is to expand the usefulness of other functions that perform logical tests.
What is a PivotTable on Excel used for?
A PivotTable is a powerful tool to calculate, summarize, and analyze data that lets you see comparisons, patterns, and trends in your data. PivotTables work a little bit differently depending on what platform you are using to run Exce
Which function in Excel to get the current date and time?
The NOW function and today function is useful when you need to display the current date and time on a worksheet or calculate a value based on the current date and time, and have that value updated each time you open the worksheet.
Can you tell what is a waterfall chart and when do we use it?
A waterfall chart shows a running total as values are added or subtracted. It’s useful for understanding how an initial value (for example, net income) is affected by a series of positive and negative values. The columns are color coded so you can quickly tell positive from negative numbers
What is a Pivot Table, and what are the different sections of a Pivot Table?
PivotTable areas are a part of PivotTable Fields Task Pane. By arranging the selected fields in the areas, you can arrive at different PivotTable layouts. As you can simply drag the fields across areas, you can quickly switch across the different layouts, summarizing the data, in a way you want.
A Pivot table is made up of four different sections:
- Values Area: Values are reported in this area
- Rows Area: The headings which are present on the left of the values.
- Column Area: The headings at the top of the values area makes the columns area.
- Filter Area: This is an optional filter used to drill down in the data set.
SQL Interview Question
Difference between Primary Key and Foreign Key in Database
A primary key uniquely identifies a row in a table, while a foreign key is used to link two tables together by referencing the primary key of the related table. The most important difference that you should note here is that a primary key cannot have a NULL value, whereas a foreign key can accept NULL values.
Key | Primary Key | Foreign Key |
Basic | It is used to uniquely identify data in the table. | It is used to maintain relationship between tables. |
Null | It can’t be NULL. | It can accept the NULL values. |
Duplicate | Two or more rows can’t have same primary key. | It can carry duplicate value for a foreign key attribute. |
Index | Primary has clustered index. | By default, It is not clustered index. |
Tables | Primary key constraint can be defined on temporary table. | It can’t be defined on temporary tables. |
How many subsets are there in SQL?
Subsets of SQLThere are three main subsets of the SQL language:. Data Control Language (DCL). Data Definition Language (DDL). Data Manipulation Language (DML)Each set of the SQL language has a special purpose:.
What are aggregate functions
Aggregate functions perform calculations on a set of values and return a single value. The common aggregate functions are:
- COUNT (counts the number of rows in the table)
- SUM (returns the sum of all values of a numeric column)
- AVG (returns the average of all values of a numeric column)
- MIN (returns the lowest value of a numeric column)
- MAX (returns the highest value of a numeric column).
What is Group by functions
The GROUP BY statement groups rows that have the same values into summary rows, like “find the number of customers in each country”.
The GROUP BY statement is often used with aggregate functions (COUNT(), MAX(), MIN(), SUM(), AVG()) to group the result-set by one or more columns.
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
Explain the different types of joins in SQL.
In SQL, the link clause is used to link rows from two or more tables based on a shared column. For table merging and data retrieval, use this clause. The most typical kinds of JOIN instructions consist of:
INNER JOIN-
An INNER JOIN is the most common type of JOIN command and is used to return all rows from two or more tables when the JOIN condition is met.
LEFT JOIN –
This type of JOIN command returns rows from the left table when a matching row from the right meets the JOIN condition.
RIGHT JOIN –
This JOIN command is similar to a LEFT JOIN, but rows are returned instead from the right table when the JOIN condition on the left is met.
FULL JOIN –
FULL JOIN returns all rows from the left and the right when there is a match in any of the tables.
What are constraints?
Rules that can be imposed to the kind of data in a table are known as constraints in SQL. They are utilised to restrict the kind of data that can be kept in a specific table column. Some typical restrictions include:
NOT NULL –
This constraint prevents null values from being stored in a column.
UNIQUE –
This constraint says that values in a column must be unique. PRIMARY KEY uses the UNIQUE constraint.
PRIMARY KEY –
This constraint is used to specify which field is the primary key.
FOREIGN KEY –
This constraint uniquely identifies a row in another table.
POWER BI INTERVIEW QUESTIONS
What is Power BI, and what are its components?
Power BI is a business analytics tool by Microsoft used for data visualization and business intelligence. Its components include Power Query, Power Pivot, Power View, and Power Map.
What is Power Query, and what is its purpose in Power BI?
Power Query is a data transformation and preparation tool in Power BI. It allows you to connect to various data sources, perform data transformations, and load data into Power BI for analysis.
Explain the difference between Power BI Desktop and Power BI Service.
Power BI Desktop is the desktop application used to create and design reports and dashboards, while Power BI Service is the cloud-based platform where you publish and share those reports with others.
What is DAX, and why is it important in Power BI?
DAX (Data Analysis Expressions) is a formula language used for creating custom calculations and aggregations in Power BI. It is essential for creating complex calculations and measures.
What is a Power BI Gateway, and when would you use it?
Power BI Gateway is a bridge between on-premises data sources and the Power BI Service in the cloud. It is used when you need to refresh data from on-premises sources in the cloud-based Power BI Service.
How do you create relationships between tables in Power BI, and why are relationships important?
Relationships are established by defining common fields between tables in the Power BI data model. Relationships are essential for creating accurate and meaningful visualizations and calculations across multiple tables.
Explain the concept of a calculated column in Power BI.
A calculated column is a column in a table that contains values calculated based on a DAX formula. These columns are precomputed during data refresh and can be used for various calculations and aggregations.
What is the purpose of a slicer in Power BI, and how does it work?
A slicer is a visual filter that allows users to interactively filter data in a report or dashboard. Users can select specific values from the slicer, and the visuals on the report page will respond accordingly.
How can you optimize the performance of a Power BI report with large datasets?
Performance optimization can include techniques like data modeling improvements, using DirectQuery or Live Connection, reducing the number of visuals, and using summarized tables.
What are the different ways to share a Power BI report with others?
– You can share Power BI reports through publishing to the Power BI Service, embedding in a website or application, exporting as a PDF or PowerPoint, or using Power BI Apps for distribution.
Can you explain the difference between Power BI Desktop and Power BI Report Server?
– Power BI Desktop is for creating reports and dashboards, while Power BI Report Server is an on-premises solution for hosting and managing Power BI reports within an organization’s network.
How does Power BI handle security and data access control?
– Power BI offers various security features, including role-level security, row-level security, and Azure Active Directory integration, to control who can access and interact with reports and data.
What are custom visuals in Power BI, and when would you use them?
– Custom visuals are third-party or custom-developed visualizations that can be added to Power BI reports. They are used when the built-in visualizations do not meet specific visualization requirements.
What is Power BI Embedded, and how is it different from regular Power BI?
– Power BI Embedded is a service that allows developers to embed Power BI reports and dashboards into custom applications. It is different from regular Power BI in terms of licensing and pricing.
Python Basics:
What is Python, and why is it widely used in data analytics?
Answer: Python is a high-level, interpreted programming language known for its simplicity and readability. It is widely used in data analytics because of the following reasons:
- Versatility: Python offers a wide range of libraries and tools specifically designed for data analysis, making it a powerful choice for data professionals.
- Data Libraries: Python has libraries like NumPy, Pandas, Matplotlib, and Seaborn that simplify data manipulation, analysis, and visualization.
- Community Support: Python has a large and active community of data analysts and data scientists who contribute to its ecosystem, providing support and sharing resources.
- Integration: Python easily integrates with databases, big data frameworks, and machine learning libraries, making it suitable for end-to-end data analytics pipelines.
Explain the difference between Python 2 and Python 3.
Answer: Python 2 and Python 3 are two major versions of Python. Python 3 was developed to address some shortcomings in Python 2. Here are key differences:
- Print Statement: In Python 2, you use print “Hello” for printing, while in Python 3, you use print(“Hello”).
- Division: In Python 2, dividing two integers using / performs integer division, while in Python 3, it performs float division.
- Unicode Support: Python 3 has better support for Unicode characters, making it more suitable for internationalization.
- Syntax Changes: Python 3 introduced various syntax changes and improvements, which enhance code readability and consistency.
- Library Compatibility: Some libraries and code written for Python 2 may not be compatible with Python 3 without modifications.
How do you comment in Python code?
Answer: You can add comments to Python code using the # symbol for single-line comments. For multi-line comments, you can enclose text in triple-quotes (”’ or “””). Here are examples:
python
Copy code
# This is a single-line comment
”’
This is a
multi-line comment
”’
“””
Another way to create
a multi-line comment
“””
What are the advantages of using Python for data analytics over other programming languages?
Answer: There are several advantages of using Python for data analytics:
- Ease of Learning: Python’s simple and readable syntax makes it accessible to beginners.
- Rich Ecosystem: Python offers a wide range of libraries and frameworks, such as NumPy, Pandas, Matplotlib, Scikit-Learn, and TensorFlow, tailored for data analytics and machine learning.
- Community Support: Python has a large and active community of data professionals who contribute to its ecosystem, share knowledge, and provide support.
- Interoperability: Python easily integrates with other languages (e.g., C/C++, Java) and can be used in various stages of data analytics, from data cleaning to machine learning.
- Open Source: Python is open source and free to use, which reduces costs for organizations.
- Cross-Platform: Python runs on multiple operating systems, ensuring compatibility across different environments.
What is PEP 8, and why is it important in Python coding?
Answer: PEP 8 stands for “Python Enhancement Proposal 8.” It is a style guide for writing Python code that promotes consistency and readability. PEP 8 is important in Python coding for the following reasons:
- Readability: Consistent code style makes it easier for developers to understand and maintain code, especially in collaborative projects.
- Community Standards: PEP 8 reflects the coding conventions widely accepted by the Python community, making it easier to share and collaborate on Python code.
- Reduced Errors: Following PEP 8 helps prevent common coding mistakes and errors.
- Professionalism: Adhering to a coding style guide like PEP 8 demonstrates professionalism and attention to detail in software development.
- Tool Support: Many Python integrated development environments (IDEs) and code analysis tools can automatically check and enforce PEP 8 compliance.
- Overall, PEP 8 promotes clean, consistent, and readable Python code, which is essential for maintaining code quality and improving collaboration.
Python Data Structures:
What are the key differences between lists, tuples, and sets in Python?
Answer :
- Lists are ordered and mutable collections defined with square brackets [ ]. They can contain elements of different data types and allow for modifications (addition, removal, and modification of elements) after creation.
- Tuples are ordered and immutable collections defined with parentheses ( ). They can contain elements of different data types, but once created, their contents cannot be changed.
- Sets are unordered collections of unique elements defined with curly braces { }. They don’t allow duplicate values and do not guarantee any specific order for elements.
What is a dictionary in Python, and how does it differ from a list?
Answer:
- A dictionary in Python is a collection of key-value pairs, defined with curly braces { } or the dict() constructor. Each key is associated with a value, and dictionaries are unordered and mutable. Keys must be unique and immutable, while values can be of any data type.
- The primary difference from a list is that lists are ordered collections accessed by numerical indices, while dictionaries use keys to access their values.
- Lists are used when you need an ordered collection of items, whereas dictionaries are suitable for storing and retrieving data based on specific keys.
How can you check if an element exists in a list or a dictionary in Python?
Answer :
To check if an element exists in a list, you can use the in keyword:
my_list = [1, 2, 3, 4, 5]
if 3 in my_list:
print("Element 3 exists in the list.")
To check if a key exists in a dictionary, you can also use the in keyword with the dictionary:
my_dict = {'name': 'Alice', 'age': 30}
if 'name' in my_dict:
print("Key 'name' exists in the dictionary.")
What are the common use cases for using a tuple instead of a list in Python?
What are the common use cases for using a tuple instead of a list in Python?
Answer :
- Immutability: Tuples are immutable, making them suitable for situations where you want to ensure data remains constant and cannot be accidentally modified.
- Hashability: Tuples are hashable and can be used as dictionary keys, unlike lists, which makes them useful for creating composite keys in dictionaries.
- Performance: In some cases, tuples can be slightly faster than lists for operations like iteration and indexing, especially for large collections.
- Multiple Return Values: Tuples are often used to return multiple values from a function because you can easily pack multiple values into a tuple and unpack them when needed.
What is a generator in Python, and how does it work?
Answer : A generator in Python is a special type of iterable that generates values on-the-fly instead of storing them in memory. It’s defined using functions with the yield keyword.
Generators are memory-efficient and are useful when dealing with large datasets or when generating infinite sequences of values.
Example of a generator function:
def countdown(n):
while n > 0:
yield n
n -= 1
# Using the generator to iterate over values
for num in countdown(5):
print(num)