
Mastering Data Analytics with pandas: A Comprehensive Guide to DataFrame Joins
Data analytics is an integral part of any data-driven organization. To extract valuable insights and make data-driven decisions, you often need to combine and analyze data from different sources. One of the essential skills in this domain is mastering the art of DataFrame joins using pandas, a popular Python library for data manipulation and analysis.
In this comprehensive guide, we will dive into the world of DataFrame joins, exploring different types of joins and demonstrating how to perform them with pandas. By the end of this blog, you’ll have a solid understanding of how to leverage pandas to combine, merge, and analyze data effectively.
Table of Contents
ToggleIntroduction to DataFrame Joins
Data analysis frequently involves working with multiple datasets that need to be combined to gain meaningful insights or perform advanced analysis. DataFrame joins are a fundamental technique in data manipulation, especially when using pandas in Python. This introductory section will provide an overview of DataFrame joins, highlighting their importance and the types of joins available.
The Need for DataFrame Joins
In the real world, data often resides in multiple datasets. For example, you may have one dataset containing customer information and another containing their purchase history. To analyze customer behavior or preferences, you need to combine these datasets. This is where DataFrame joins come into play.
DataFrame joins enable you to bring together data from different sources, linking them based on a common attribute, such as a unique identifier, key, or column. The result is a merged dataset that provides a comprehensive view of the information you require for analysis.
Types of DataFrame Joins
There are several types of DataFrame joins, each serving a specific purpose:
Inner Join: This type of join returns only the rows where there is a match in both DataFrames based on the specified key. It filters the data to show only the common elements between the two datasets.
Left Join: A left join includes all rows from the left DataFrame and only the matching rows from the right DataFrame. If there’s no match in the right DataFrame, it still includes the data from the left DataFrame.
Right Join: The right join is the opposite of the left join. It includes all rows from the right DataFrame and the matching rows from the left DataFrame. Non-matching rows from the left DataFrame are excluded.
Outer Join: An outer join combines all rows from both DataFrames. It includes matching rows from both DataFrames and fills in missing values with NaN for columns that don’t have a match.
Practical Use Cases
DataFrame joins are a versatile tool for data analysts and scientists in various industries. Here are some common use cases:
Combining Sales Data: Merge sales transactions with customer information to analyze customer demographics and purchasing behavior.
Matching Employee Records: Join employee data with department data to assign department information to employees for organizational analysis.
Merging Time Series Data: Combine time series data with weather data to analyze the impact of weather on certain events or activities.
Data Enrichment: Augmenting existing data with additional information, such as adding geographical data to customer addresses for mapping and geospatial analysis.
DataFrame joins are an essential skill for data analysts and data scientists, and mastering them allows you to unlock the full potential of your data for informed decision-making. In the following sections of this guide, we will explore each type of join in detail and provide practical examples to help you become proficient in using pandas for data analysis.
sales_data:
- order_id: The order ID for each sale.
- product_id: The ID of the product sold.
- quantity: The quantity of the product sold.
- total_price: The total price for the sale.
customer_data:
- customer_id: The customer’s unique identifier.
- customer_name: The customer’s name.
- customer_email: The customer’s email address.
import pandas as pd # Read the customer data from the first Excel file # Read customer data from Excel customer_data = pd.read_excel(r"E:\JOINS\CUSTOMERDATA.xlsx") sales_data = pd.read_excel(r"E:\JOINS\SALESDATA.xlsx") print(customer_data) print(sales_data)
OUTPUT
customer_id customer_name customer_email 0 101 Alice alice@example.com 1 102 Bob bob@example.com 2 103 Charlie charlie@example.com 3 104 David david@example.com 4 105 Eve eve@example.com order_id customer_id quantity total_price 0 1 101 3 150 1 2 101 2 120 2 3 103 5 250 3 4 103 1 50 4 5 105 4 200
The code you provided will perform a left join on the ‘customer_id’ column in the “customer_data” and “sales_data” DataFrames. Here’s what the code will do:
- It will merge the two DataFrames based on the ‘customer_id’ column.
- Since you specified how=’left’, the result will include all rows from the “customer_data” DataFrame and only the matching rows from the “sales_data” DataFrame. Any unmatched rows from the “customer_data” DataFrame will still be included in the result.
The result will be a new DataFrame containing all the columns from both the “customer_data” and “sales_data” DataFrames, with additional rows where “customer_id” matches between the two DataFrames. If there is no match for a specific ‘customer_id’ in the “sales_data” DataFrame, the corresponding columns for that row in the “sales_data” DataFrame will contain NaN (missing values) in the result.
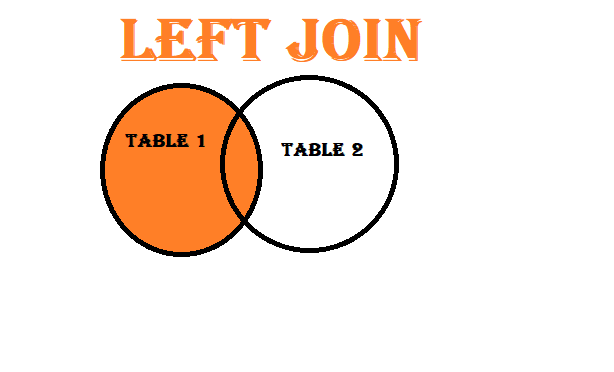
LEFT Join
# Perform a left join on 'customer_id' in customer_data and 'customer_id' in sales_data result_df = pd.merge(customer_data, sales_data, left_on='customer_id', right_on='customer_id', how='left') # Display the result print(result_df)outcome
customer_id customer_name customer_email order_id quantity \ 0 101 Alice alice@example.com 1.0 3.0 1 101 Alice alice@example.com 2.0 2.0 2 102 Bob bob@example.com NaN NaN 3 103 Charlie charlie@example.com 3.0 5.0 4 103 Charlie charlie@example.com 4.0 1.0 5 104 David david@example.com NaN NaN 6 105 Eve eve@example.com 5.0 4.0 total_price 0 150.0 1 120.0 2 NaN 3 250.0 4 50.0 5 NaN 6 200.0The code you provided will perform a left join on the ‘customer_id’ column in the “customer_data” and “sales_data” DataFrames. Here’s what the code will do:
- It will merge the two DataFrames based on the ‘customer_id’ column.
- Since you specified how=’left’, the result will include all rows from the “customer_data” DataFrame and only the matching rows from the “sales_data” DataFrame. Any unmatched rows from the “customer_data” DataFrame will still be included in the result.
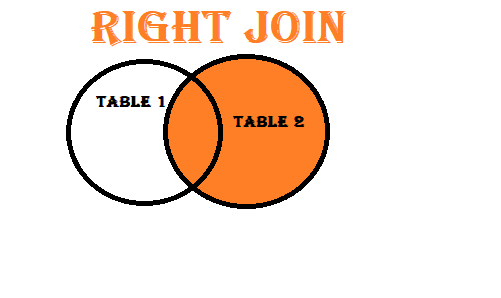
Right join
# Perform a right join on 'customer_id' in customer_data and 'customer_id' in sales_data result_df = pd.merge(customer_data, sales_data, left_on='customer_id', right_on='customer_id', how='right') # Display the result print(result_df)
OUTPUT
customer_id customer_name customer_email order_id quantity \ 0 101 Alice alice@example.com 1 3 1 101 Alice alice@example.com 2 2 2 103 Charlie charlie@example.com 3 5 3 103 Charlie charlie@example.com 4 1 4 105 Eve eve@example.com 5 4 total_price 0 150 1 120 2 250 3 50 4 200
The code you provided performs a right join between two DataFrames, customer_data and sales_data, on the ‘customer_id’ column. Here’s an explanation of each part of the code:
- pd.merge(customer_data, sales_data, left_on=’customer_id’, right_on=’customer_id’, how=’right’): This line of code uses the pd.merge() function to perform the right join. Here’s a breakdown of the parameters used:
- customer_data and sales_data are the two DataFrames you want to join.
left_on=’customer_id’ specifies that you want to use the ‘customer_id’ column from the customer_data DataFrame as the key for the left DataFrame.
right_on=’customer_id’ specifies that you want to use the ‘customer_id’ column from the sales_data DataFrame as the key for the right DataFrame. - how=’right’ specifies the type of join, in this case, it’s a right join. This means that all rows from the right DataFrame (sales_data) will be included in the result, and matching rows from the left DataFrame (customer_data) will be included as well.
The result of the merge operation is stored in the result_df DataFrame. - print(result_df): This line of code prints the resulting DataFrame, which is the result of the right join between customer_data and sales_data.
The resulting DataFrame, result_df, will contain all the rows from the sales_data DataFrame and additional columns from the customer_data DataFrame where there is a matching ‘customer_id’. Rows from customer_data that don’t have a matching ‘customer_id’ in sales_data will be included with NaN values in the columns from sales_data.
In summary, this code is performing a right join between customer data and sales data using the ‘customer_id’ column as the key, and the result will include all sales data and associated customer data where applicable.
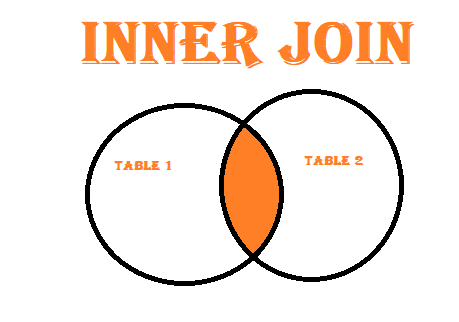
Inner Join
result_df = pd.merge(customer_data, sales_data, on='customer_id', how='inner') # Display the result print(result_df)Output
customer_id customer_name customer_email order_id quantity \ 0 101 Alice alice@example.com 1 3 1 101 Alice alice@example.com 2 2 2 103 Charlie charlie@example.com 3 5 3 103 Charlie charlie@example.com 4 1 4 105 Eve eve@example.com 5 4 total_price 0 150 1 120 2 250 3 50 4 200
- pd.merge(customer_data, sales_data, on=’customer_id’, how=’inner’): This line of code performs an inner join between customer_data and sales_data on the ‘customer_id’ column. The on=’customer_id’ parameter specifies that the ‘customer_id’ column is used as the key for the join, and how=’inner’ specifies that it’s an inner join. This means that only rows with matching ‘customer_id’ values in both DataFrames will be included in the result.
- The result of the inner join is stored in the result_df DataFrame.
- print(result_df): This line of code prints the resulting DataFrame, which contains only the rows with matching ‘customer_id’ values from both customer_data and sales_data.
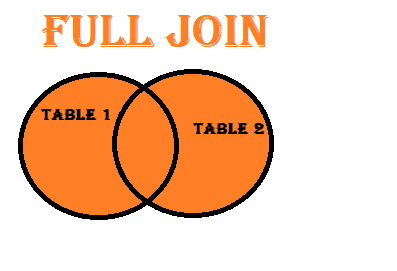
OUTER JOIN
result_df = pd.merge(customer_data, sales_data, on=’customer_id’, how=’outer’) # Display the result print(result_df)output
customer_id customer_name customer_email order_id quantity \ 0 101 Alice alice@example.com 1.0 3.0 1 101 Alice alice@example.com 2.0 2.0 2 102 Bob bob@example.com NaN NaN 3 103 Charlie charlie@example.com 3.0 5.0 4 103 Charlie charlie@example.com 4.0 1.0 5 104 David david@example.com NaN NaN 6 105 Eve eve@example.com 5.0 4.0 total_price 0 150.0 1 120.0 2 NaN 3 250.0 4 50.0 5 NaN 6 200.0