Python Data Cleaning & Charting with Matplotlib and Seaborn
Master Python Data Cleaning and Charting with Matplotlib and Seaborn.In t
his hands-on tutorial, we’ll guide you through the essential data cleaning techniques in Python. Learn how to effectively handle missing data, apply various strategies to fill in the gaps, and optimize your datasets for analysis.
Next, unleash the power of data visualization using Matplotlib and Seaborn. Discover how to create captivating charts, interactive plots, and stunning visualizations to convey complex insights with ease.
Whether you’re a beginner or an experienced data scientist, this video will equip you with the skills to clean and visualize your data like a pro. Join us on this exciting journey of Python data cleaning and charting and take your data analysis skills to the next level!”
Table of Contents
ToggleStep 1: Import Pandas
import pandas as pd
Step 3: Read Data
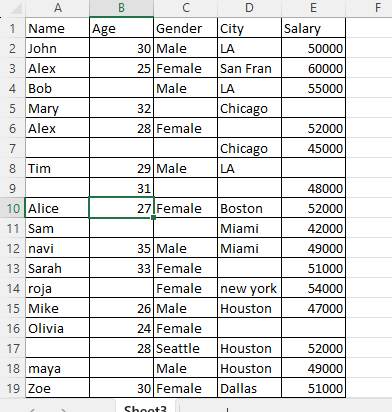
import pandas as pd df = pd.read_excel(r'C:\Users\yogesh\Desktop\excel files for practice\messeydataset.xlsx') # Display the DataFrame. print(df)
Step 3: Explore the Data
print(df.columns)In Python Pandas, the df.columns attribute is used to retrieve the column labels (column names) of a DataFrame. It returns a Pandas Index object containing the column names of the DataFrame.
Index(['Name', 'Age', 'Gender', 'City', 'Salary'], dtype='object')
Step 4 :Fill the missing values in the 'Name
df['Name'].fillna('Unknown', inplace=True)
The line of code df[‘Name’].fillna(‘Unknown’, inplace=True) is used to fill the missing values in the ‘Name’ column of the DataFrame df with the value ‘Unknown’. print(df.Name)Output
0 John 1 Alex 2 Bob 3 Mary 4 Alex 5 Unknown 6 Tim 7 Unknown 8 Alice 9 Sam 10 navi 11 Sarah 12 roja 13 Mike 14 Olivia 15 Unknown 16 maya 17 Zoe 18 Unknown Name: Name, dtype: object
Step 5: Filling age missing value
mean_age = df['Age'].mean() df['Age'].fillna(mean_age, inplace=True) print(df.Age)
The lines of code mean_age = df[‘Age’].mean() and df[‘Age’].fillna(mean_age, inplace=True) are used to calculate the mean of the ‘Age’ column and then fill the missing values in the ‘Age’ column with this mean value, directly modifying the original DataFrame df.
OUTPUT below
0 30.000000 1 25.000000 2 29.071429 3 32.000000 4 28.000000 5 29.071429 6 29.000000 7 31.000000 8 27.000000 9 29.071429 10 35.000000 11 33.000000 12 29.071429 13 26.000000 14 24.000000 15 28.000000 16 29.071429 17 30.000000 18 29.000000 Name: Age, dtype: float64
Step 6: Fill most frequent Gender
mode_gender = df['Gender'].mode().values[0] # Fill missing 'Gender' values with the mode (most frequent) gender df['Gender'].fillna(mode_gender, inplace=True) # Print the DataFrame to see the updated values print(df)
Here’s a step-by-step explanation of the code:
- mode_gender = df[‘Gender’].mode().values[0]: This line calculates the mode (most frequent value) of the ‘Gender’ column and stores it in the variable mode_gender.
- df[‘Gender’].fillna(mode_gender, inplace=True): This line fills the missing values in the ‘Gender’ column with the value stored in the mode_gender variable. The fillna method is used to replace the missing values with the specified value. The inplace=True argument ensures that the changes are applied directly to the DataFrame df.
- print(df): Finally, this line prints the updated DataFrame that now has the missing ‘Gender’ values filled with the mode (most frequent) gender.
- After executing this code, you should see the DataFrame with the missing ‘Gender’ values replaced by the mode value, and all missing values in the ‘Gender’ column should be filled.
Output
0 Male 1 Female 2 Male 3 Female 4 Female 5 Female 6 Male 7 Female 8 Female 9 Female 10 Male 11 Female 12 Female 13 Male 14 Female 15 Seattle 16 Male 17 Female 18 Female Name: Gender, dtype: object
Step 7: Change 'Seattle' in the 'Gender' column with 'Female'
df['Gender'].replace({'Seattle': 'Female'}, inplace=True)
print(df.Gender)
Output
0 Male 1 Female 2 Male 3 Female 4 Female 5 Female 6 Male 7 Female 8 Female 9 Female 10 Male 11 Female 12 Female 13 Male 14 Female 15 Female 16 Male 17 Female 18 Female Name: Gender, dtype: object
Step 8: Fill missing 'City' values with the mode (most frequent)
mode_city = df['City'].mode().values[0] # Fill missing 'City' values with the mode (most frequent) city df['City'].fillna(mode_city, inplace=True) # Print the DataFrame to see the updated values print(df.City)In this code snippet, it appears that the DataFrame df contains a column named ‘City’, and there are some missing values in that column. The goal is to fill the missing ‘City’ values with the mode (most frequent) city in the DataFrame.
Here’s a step-by-step explanation of what the code does:
- mode_city = df[‘City’].mode().values[0]: This line calculates the mode (most frequent) value of the ‘City’ column in the DataFrame df using the .mode() function. The result is stored in the variable mode_city.
- df[‘City’].fillna(mode_city, inplace=True): This line fills the missing values in the ‘City’ column of the DataFrame with the value stored in mode_city. The fillna() function is used for this purpose, and inplace=True means the changes are made directly to the DataFrame df without creating a copy.
- print(df.City): This line prints the ‘City’ column of the DataFrame df after filling the missing values with the mode city. The updated values will be displayed on the screen.
0 LA 1 San Fran 2 LA 3 Chicago 4 Houston 5 Chicago 6 LA 7 Houston 8 Boston 9 Miami 10 Miami 11 Houston 12 new york 13 Houston 14 Houston 15 Houston 16 Houston 17 Dallas 18 Dallas Name: City, dtype: object
Step 9: Fill missing 'Salary' values with the mean salary
mean_salary = df['Salary'].mean() # Fill missing 'Salary' values with the mean salary df['Salary'].fillna(mean_salary, inplace=True) # Print the DataFrame to see the updated values print(df.Salary)Output
0 50000.0 1 60000.0 2 55000.0 3 50375.0 4 52000.0 5 45000.0 6 50375.0 7 48000.0 8 52000.0 9 42000.0 10 49000.0 11 51000.0 12 54000.0 13 47000.0 14 50375.0 15 52000.0 16 49000.0 17 51000.0 18 49000.0 Name: Salary, dtype: float64
Step 10: Bar chart of Gender distribution:
#Bar chart of Gender distribution:
import matplotlib.pyplot as plt
import seaborn as sns
sns.countplot(x='Gender', data=df)
plt.title('Gender Distribution')
plt.show()
Here’s a step-by-step explanation of what the code does:
- import matplotlib.pyplot as plt: This line imports the pyplot module from the matplotlib library, which allows you to create visualizations like plots and charts.
- import seaborn as sns: This line imports the seaborn library, which is a powerful data visualization library built on top of matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics.
- sns.countplot(x=’Gender’, data=df): This line creates a count plot using seaborn’s countplot function. The x parameter specifies that the ‘Gender’ column should be represented on the x-axis, and the data parameter specifies the DataFrame from which the data will be taken.
- plt.title(‘Gender Distribution’): This line sets the title of the plot to ‘Gender Distribution’.
- plt.show(): This line displays the plot.
Make sure that you have the correct data in the ‘Gender’ column of the DataFrame ‘df’ before running this code. If everything is set up correctly, this code will generate a bar chart showing the distribution of genders in your dataset.
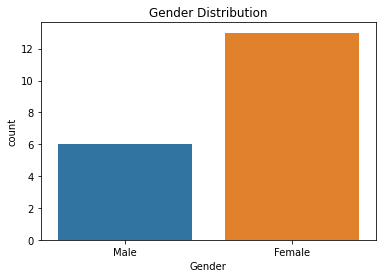
Step 11:Bar chart of Salary distribution:
plt.hist(df['Salary'], bins=10, edgecolor='black')
plt.xlabel('Salary')
plt.ylabel('Count')
plt.title('Salary Distribution')
plt.show()
Here’s a step-by-step explanation of the code:
- plt.hist(df[‘Salary’], bins=10, edgecolor=’black’): This line creates the histogram using the ‘Salary’ column from the DataFrame ‘df’. The ‘bins=10’ parameter specifies that the data will be divided into 10 equally spaced bins. The ‘edgecolor=’black” parameter sets the color of the edges of the bars in the histogram to black.
- plt.xlabel(‘Salary’): This line sets the label for the x-axis as ‘Salary’.
- plt.ylabel(‘Count’): This line sets the label for the y-axis as ‘Count’, representing the number of occurrences in each bin.
- plt.title(‘Salary Distribution’): This line sets the title of the plot to ‘Salary Distribution’.
- `plt.show:This line displays the histogram plot on the screen.
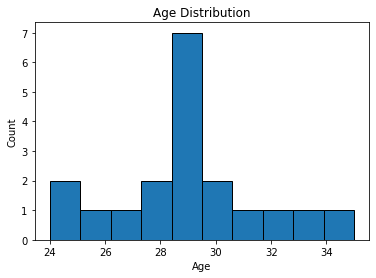
Step 12:Bar chart of Age distribution:
plt.hist(df['Age'], bins=10, edgecolor='black')
plt.xlabel('Age')
plt.ylabel('Count')
plt.title('Age Distribution')
plt.show()
Here’s a breakdown of the code:
- plt.hist(df[‘Age’], bins=10, edgecolor=’black’): This line creates the histogram. It takes the ‘Age’ column from the DataFrame ‘df’ and plots it using the plt.hist function from the matplotlib library. The ‘bins’ parameter is set to 10, which means the histogram will have 10 bars, representing different age ranges. The ‘edgecolor’ parameter sets the color of the edges of the bars to black.
- plt.xlabel(‘Age’): This line sets the label for the x-axis to ‘Age’.
- plt.ylabel(‘Count’): This line sets the label for the y-axis to ‘Count’, representing the frequency of each age group.
- plt.title(‘Age Distribution’): This line sets the title of the histogram to ‘Age Distribution’.
- plt.show(): This line displays the histogram plot
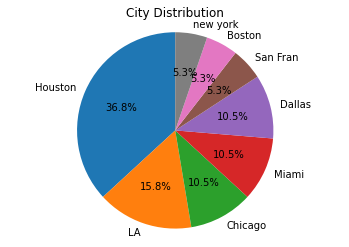
Step 13:Pie chart of City distribution
city_counts = df['City'].value_counts()
plt.pie(city_counts, labels=city_counts.index, autopct='%1.1f%%', startangle=90)
plt.title('City Distribution')
plt.axis('equal')
plt.show()
- city_counts = df[‘City’].value_counts(): This line calculates the count of occurrences of each unique city in the ‘City’ column of the DataFrame df. The result is stored in the city_counts variable, which is a Pandas Series containing city names as index and their corresponding counts as values.
- plt.pie(city_counts, labels=city_counts.index, autopct=’%1.1f%%’, startangle=90): This line creates the pie chart. The plt.pie() function takes several parameters:
- city_counts: The data for the pie chart, which is the city_counts Series containing city counts.
- labels: The labels for each pie slice, which are the city names (obtained from city_counts.index).
- autopct=’%1.1f%%’: This parameter formats the percentage values displayed on each pie slice. ‘%1.1f%%’ formats the percentage with one decimal place.
- startangle=90: This parameter sets the starting angle for the first slice in degrees. In this case, it’s set to 90 degrees, which means the first slice will start from the 12 o’clock position.
- plt.title(‘City Distribution’): This line sets the title for the pie chart.
- plt.axis(‘equal’): This line ensures that the pie chart is displayed as a circle (i.e., an equal aspect ratio).
- plt.show(): This line displays the pie chart.
FAQ
Data cleaning, also known as data preprocessing, is the process of identifying and correcting errors or inconsistencies in datasets. It is crucial in data analysis because clean data ensures the accuracy and reliability of your analysis results.
Common data cleaning tasks in Python include handling missing values, removing duplicates, converting data types, and dealing with outliers.
You can handle missing values by using methods like dropna() to remove rows with missing values, fillna() to fill missing values with specific values, or interpolate() to fill missing values with interpolated values.
Outliers can significantly affect statistical analysis and visualization. Removing or transforming outliers can help in producing more accurate and meaningful insights from the data.
Some popular Python libraries for data cleaning are Pandas and NumPy. Pandas provides powerful tools for data manipulation, while NumPy is useful for numerical operations.
Matplotlib and Seaborn are Python libraries used for data visualization. Matplotlib is a versatile library for creating various types of plots, while Seaborn is built on top of Matplotlib and provides a high-level interface for creating attractive statistical graphics.
With Matplotlib, you can create line plots, bar plots, scatter plots, histograms, and more. Seaborn specializes in statistical visualization and offers functions for creating heatmaps, pair plots, and distribution plots.
You can customize plots by modifying parameters such as color, style, labels, and titles. Matplotlib and Seaborn provide extensive customization options to tailor the visualizations to your specific needs.