Exploring the Power of Python Libraries: A Deep Dive into Pandas
What is Pandas?
Pandas is a powerful Python library used for data analysis and manipulation. It provides essential tools for handling datasets, performing operations like data cleaning, transformation, and aggregation. The name “Pandas” is derived from both “Panel Data” and “Python Data Analysis.” It was developed by Wes McKinney in 2008 as a means to solve the difficulties of working with structured data in Python.
Importing Pandas
To use Pandas, you need to first install it. Once installed, you can easily import it using the following statement:
import pandas as pd
import numpy as np
The alias “pd” is commonly used for Pandas to keep the code short and easy to read. You can also import other libraries like NumPy alongside Pandas for numerical operations.
Introduction: Why Use Pandas?
Pandas provides several advantages over other libraries like NumPy, especially when dealing with real-world data. Here’s why you should consider using Pandas:
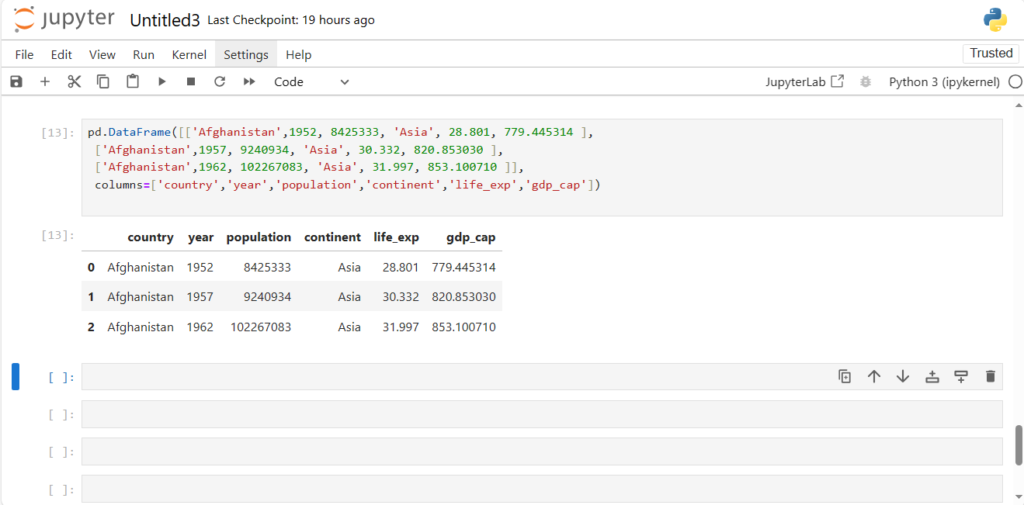
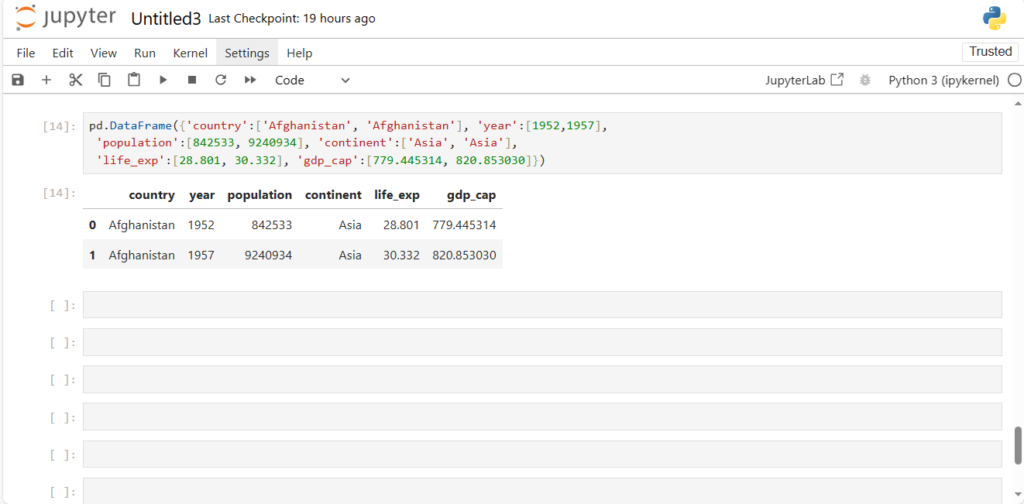
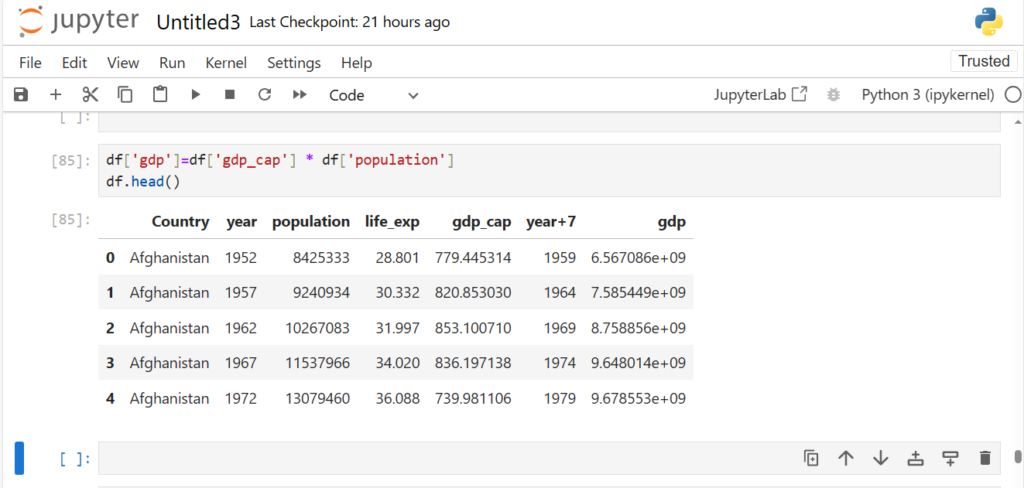
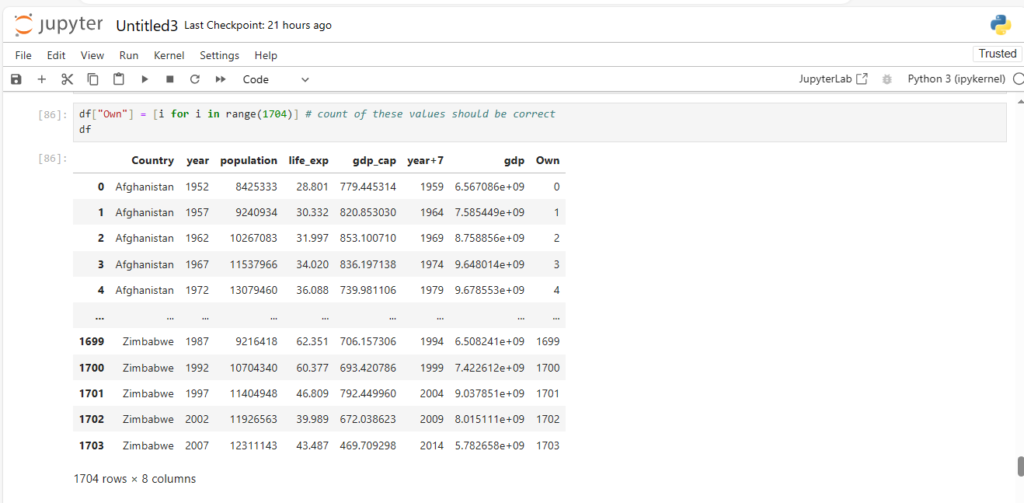
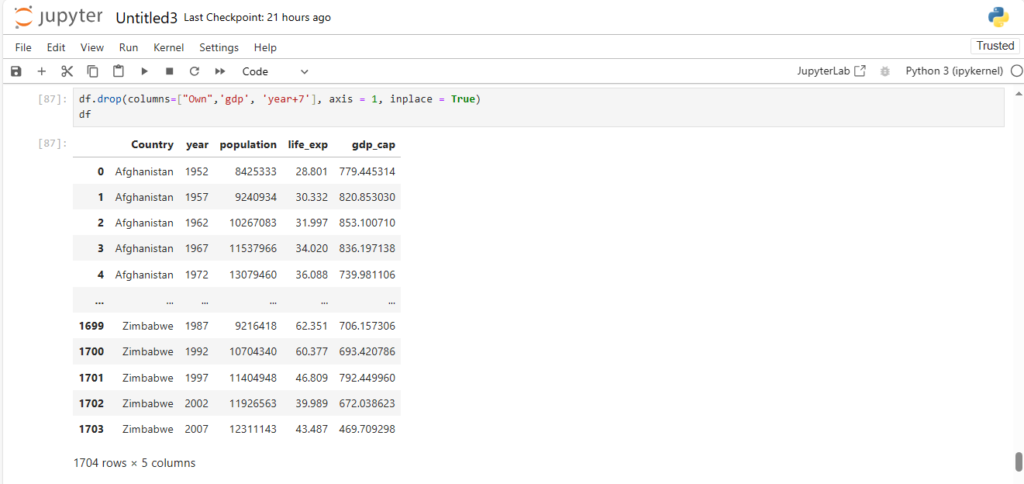
- Handling Heterogeneous Data: Unlike NumPy, which primarily works with a single datatype (usually numeric), Pandas can handle heterogeneous data, meaning it can work with both numeric and string data in a dataset simultaneously. For example, you can store a combination of numeric data (like population) and string data (like place names) in a Pandas DataFrame.
- Ease of Use: Pandas provides an intuitive syntax and powerful data structures (like Series and DataFrame) to make data manipulation easier. This is especially useful when dealing with complex datasets.
How is Pandas Different from NumPy?
While both NumPy and Pandas are excellent libraries for data manipulation, they are different in several ways:
- NumPy: Works primarily with homogeneous data, meaning that all elements in an array are of the same type (e.g., all numbers).
- Pandas: Provides more flexibility by supporting heterogeneous data types. You can work with numbers, strings, and other types of data in a single DataFrame.
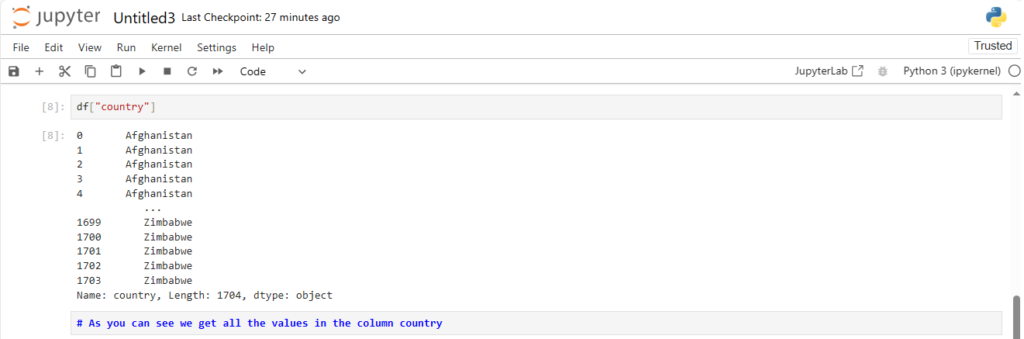
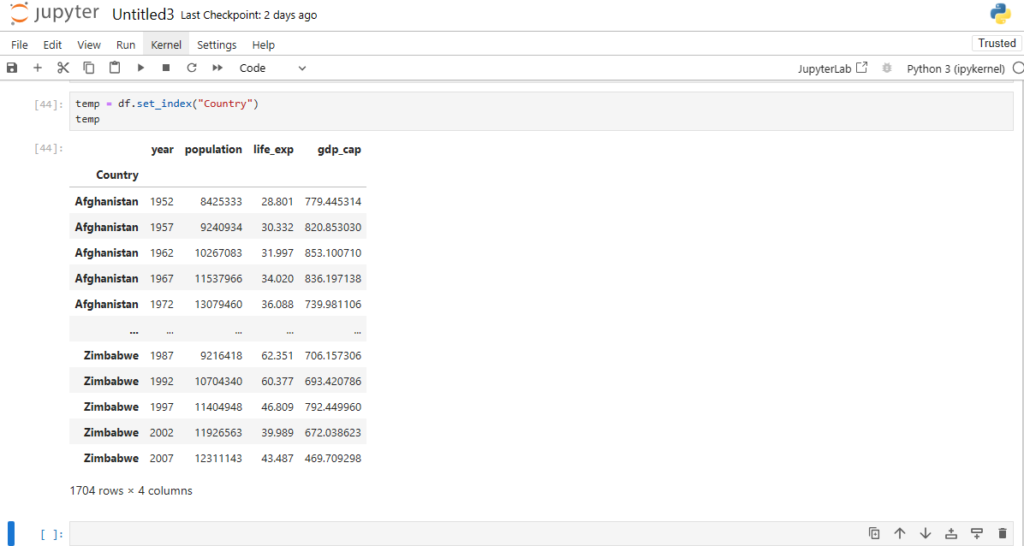
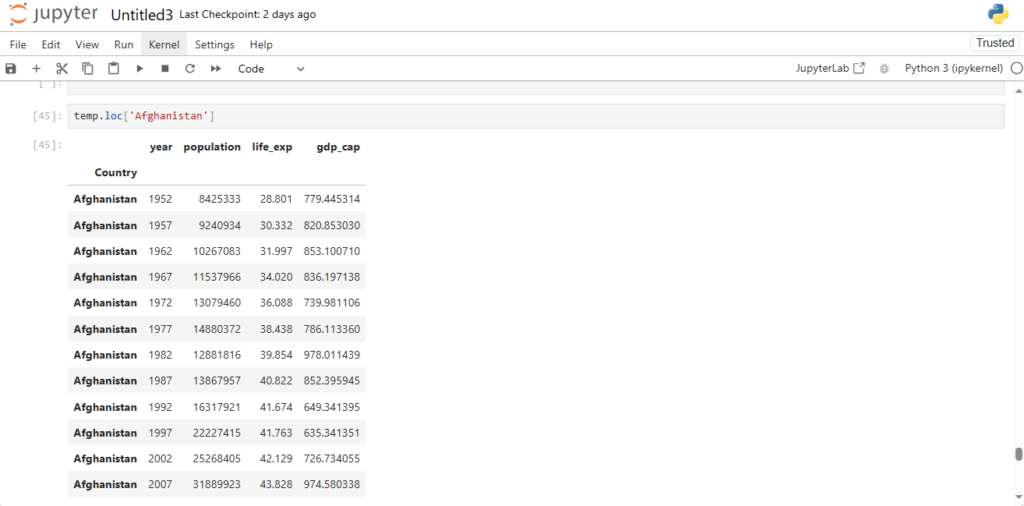
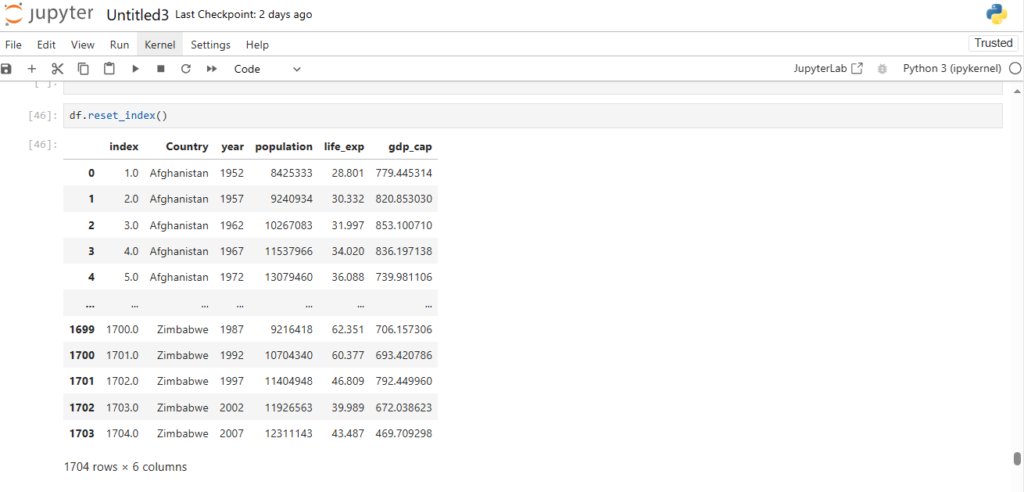
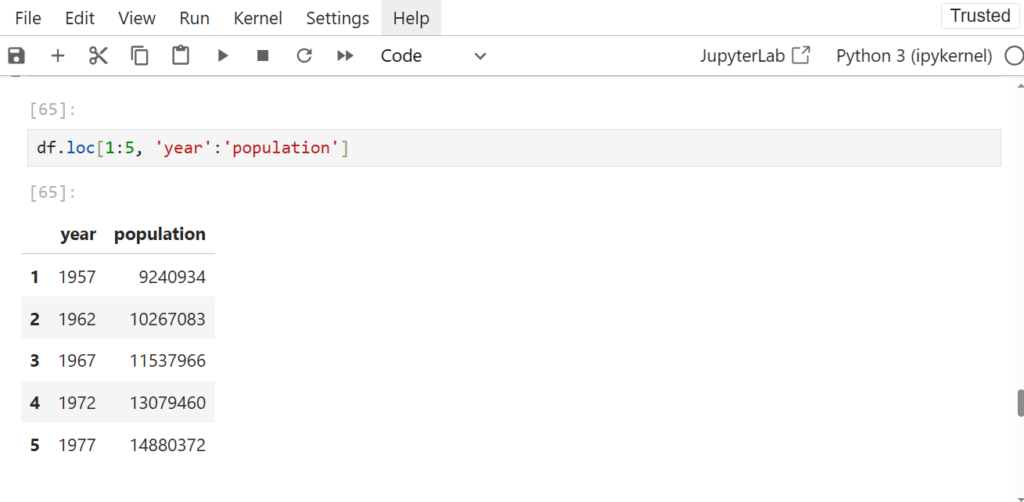
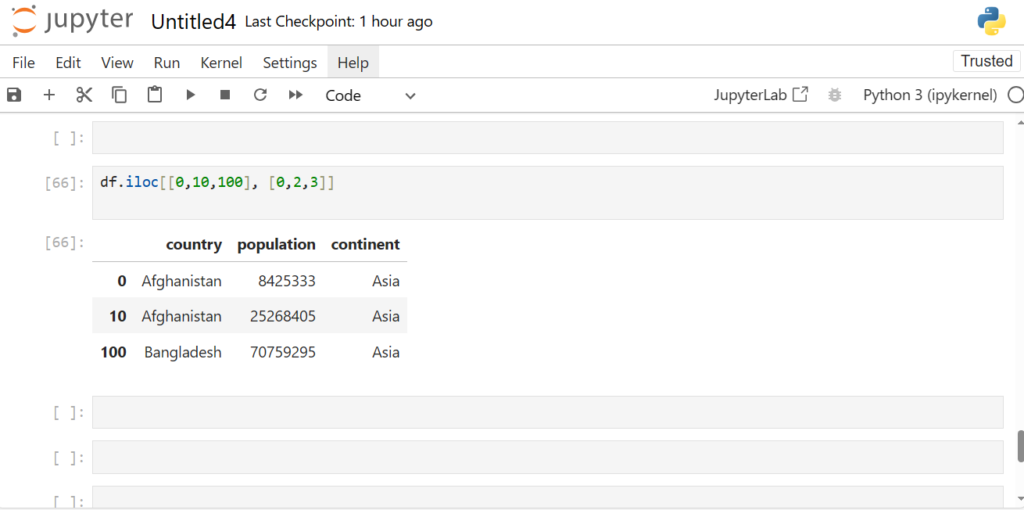
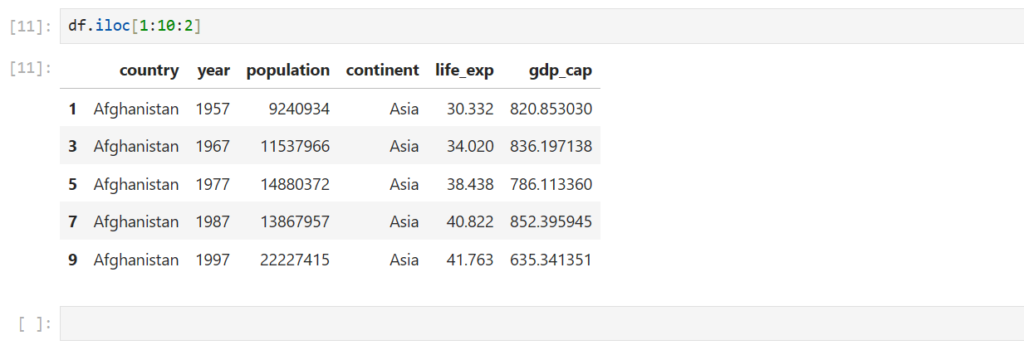
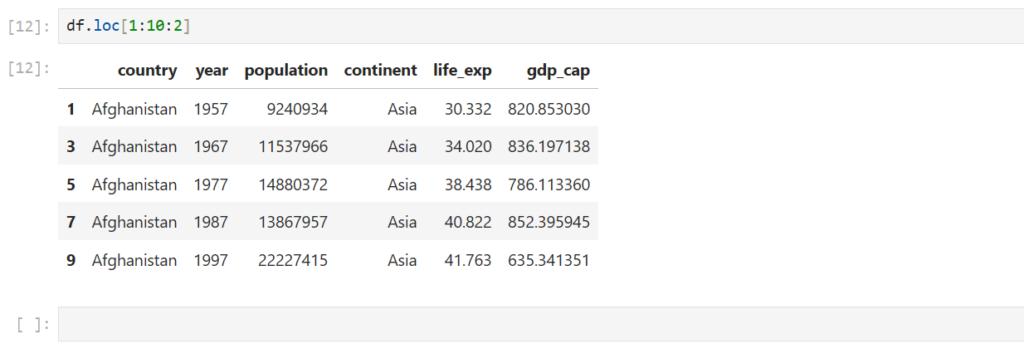
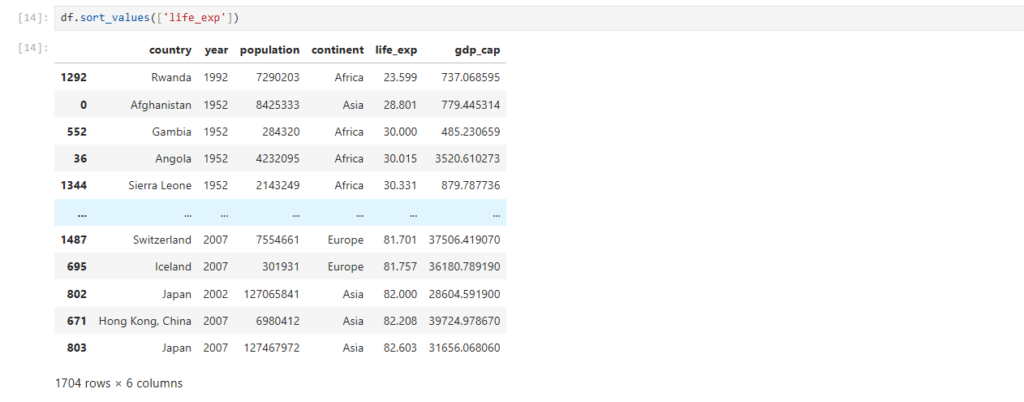
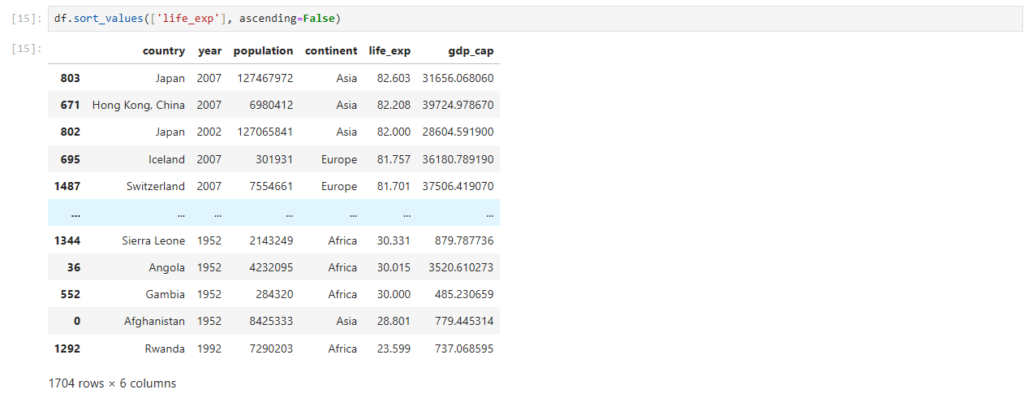
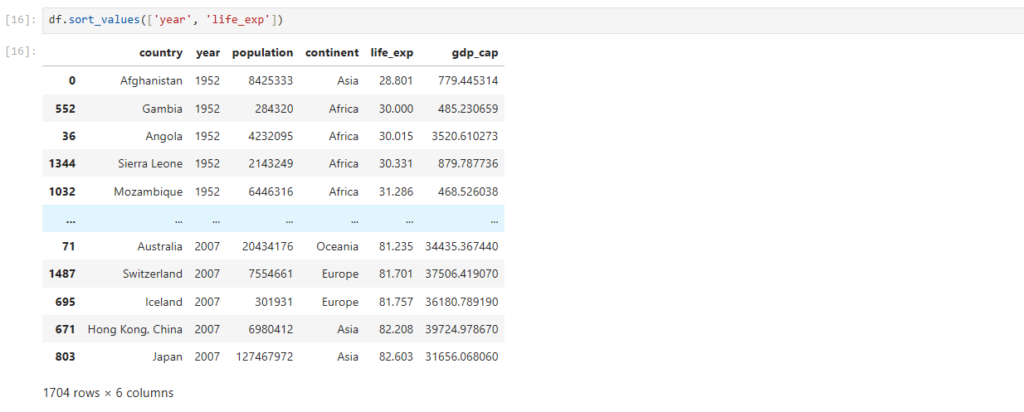
Reading Dataset in Pandas
One of the most important features of Pandas is its ability to read data from different file formats like CSV, Excel, and SQL databases. Here’s how you can read a dataset from a CSV file:
df = pd.read_csv(r"C:\Users\welcome\Downloads\dataset1.csv")
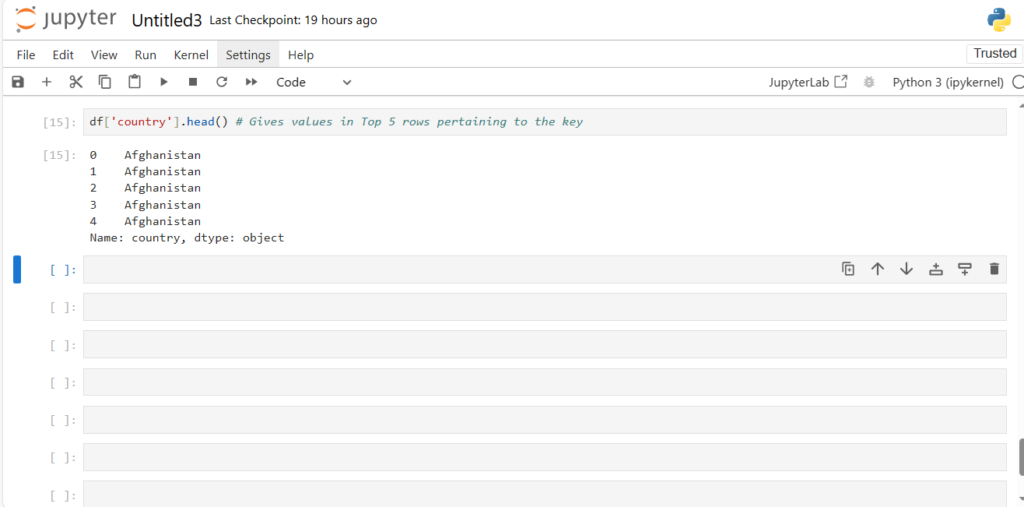
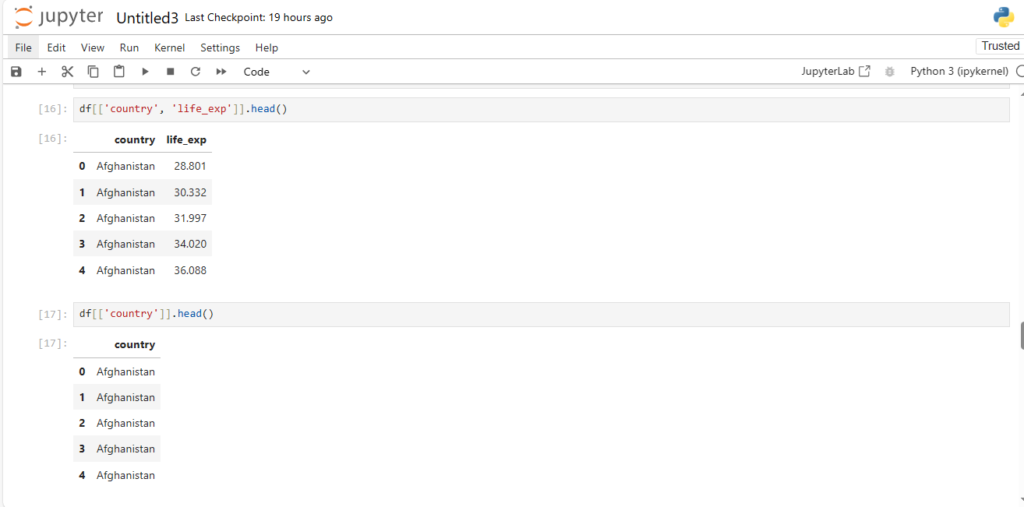
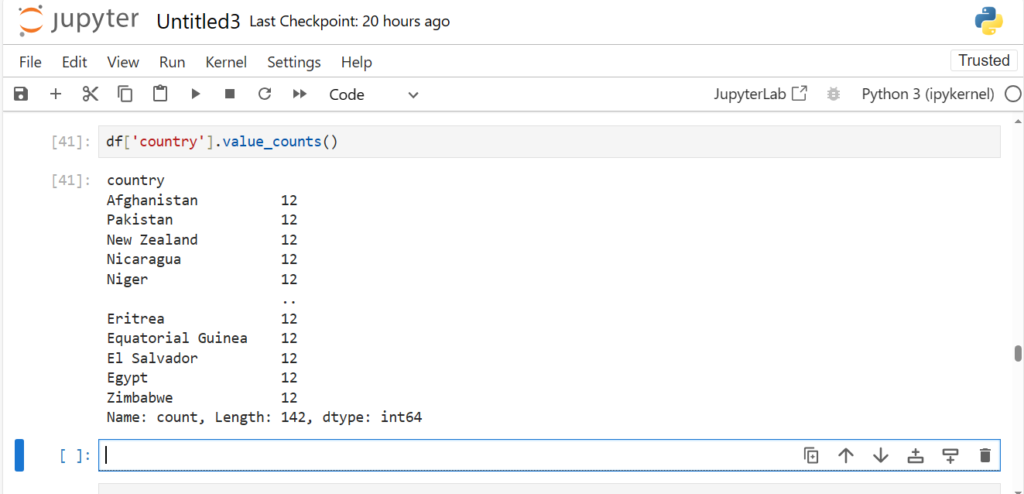
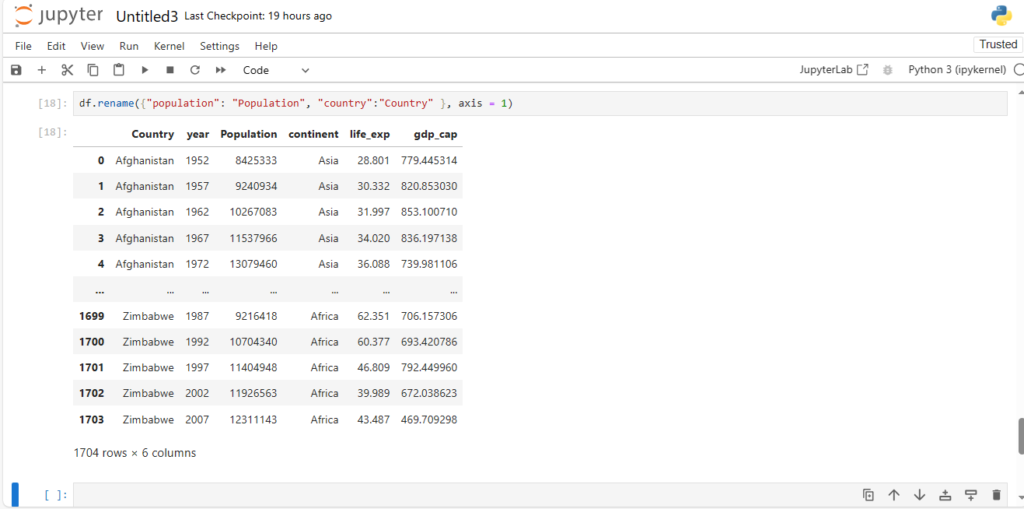
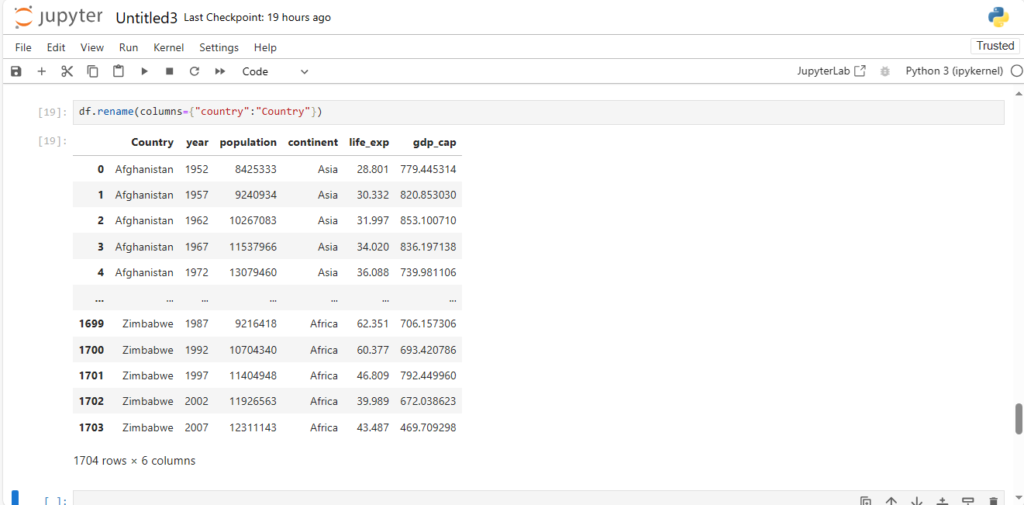
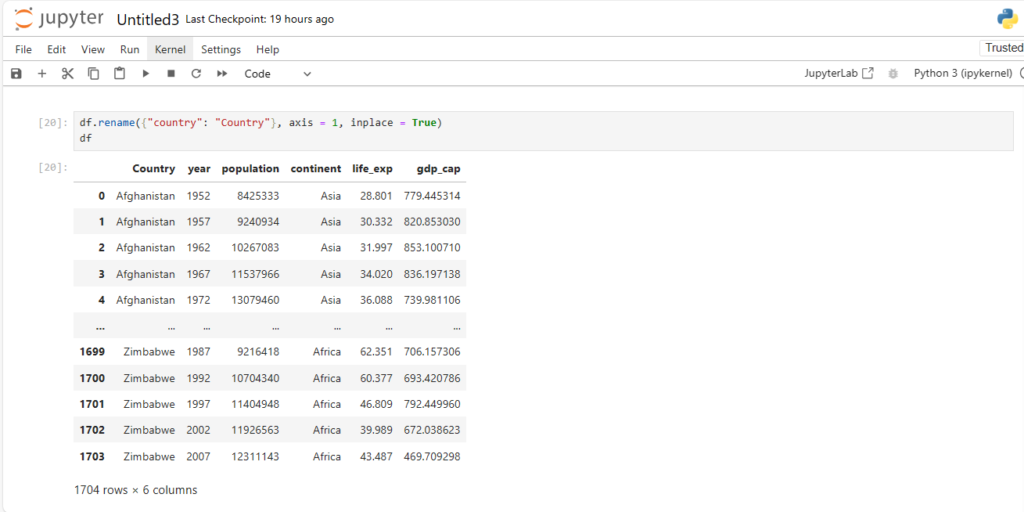
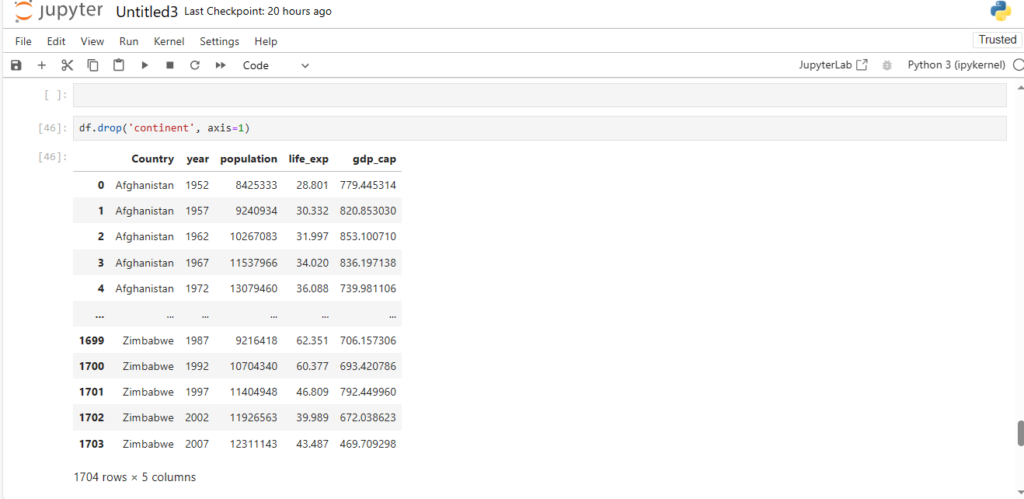
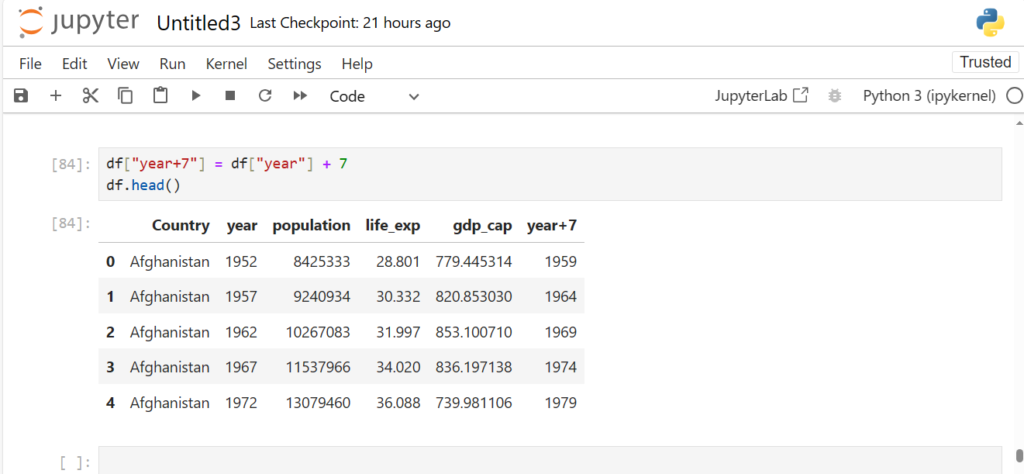
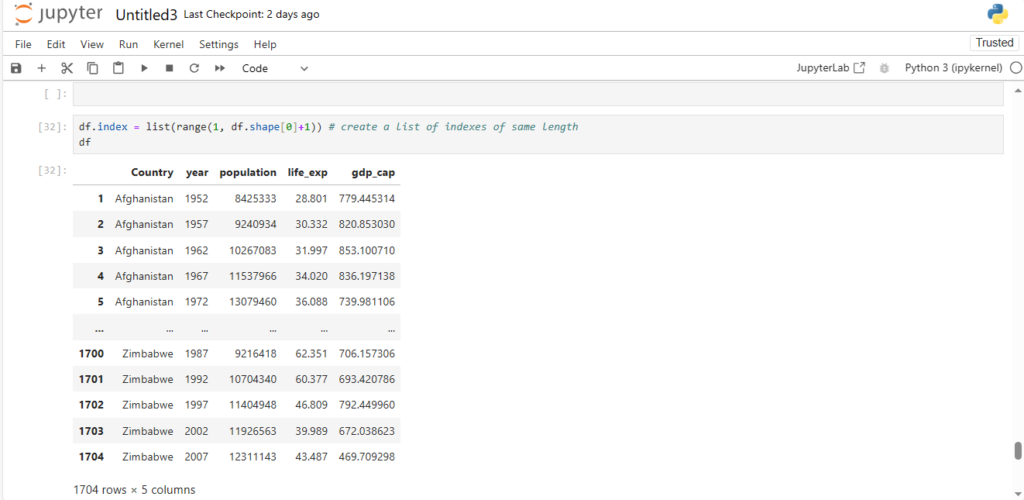
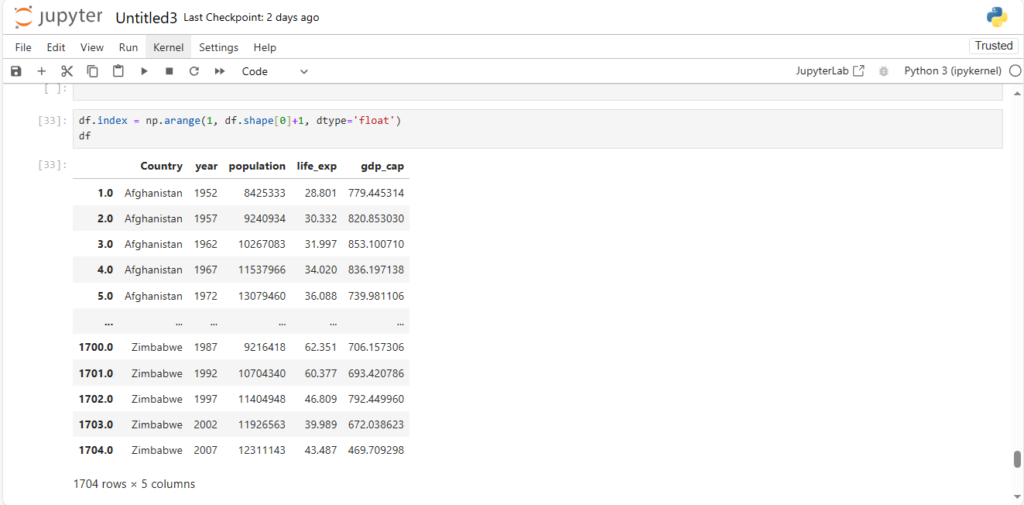
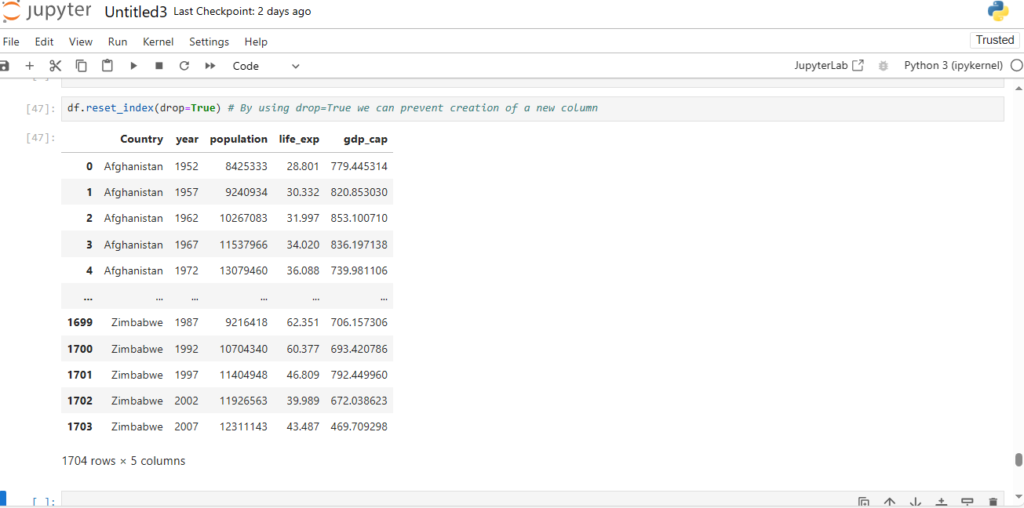
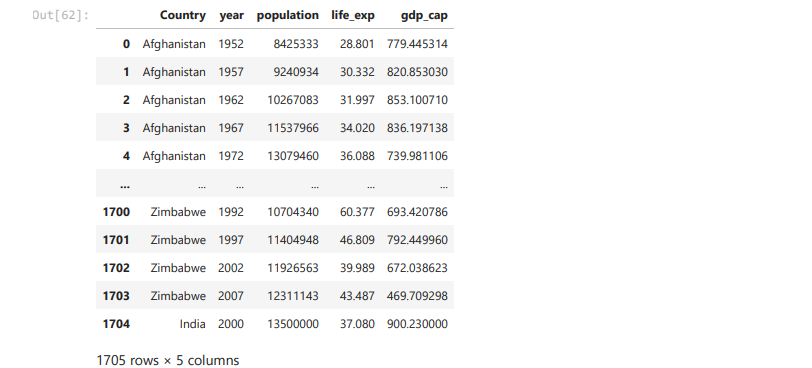
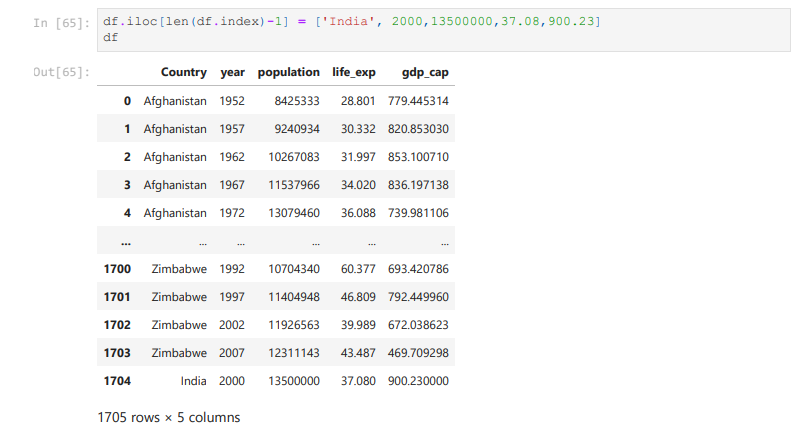
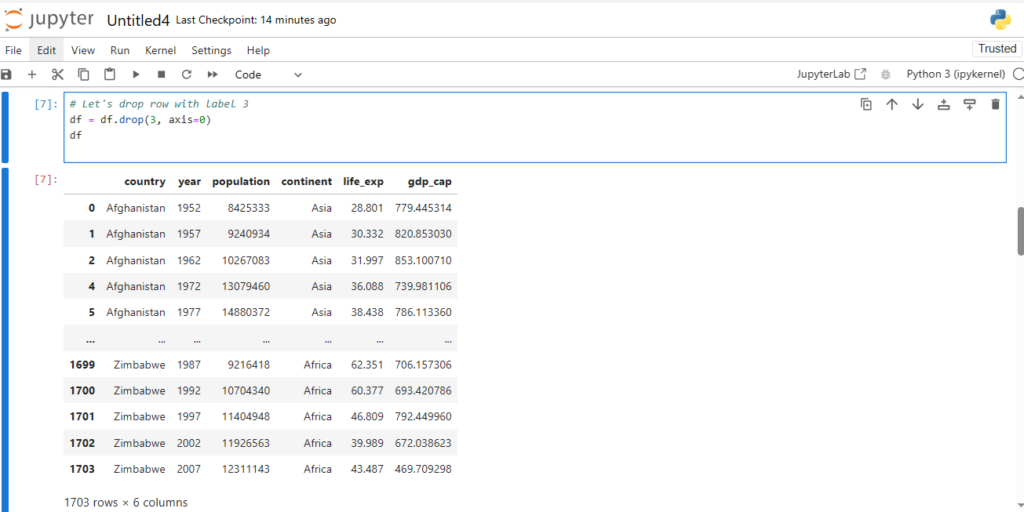
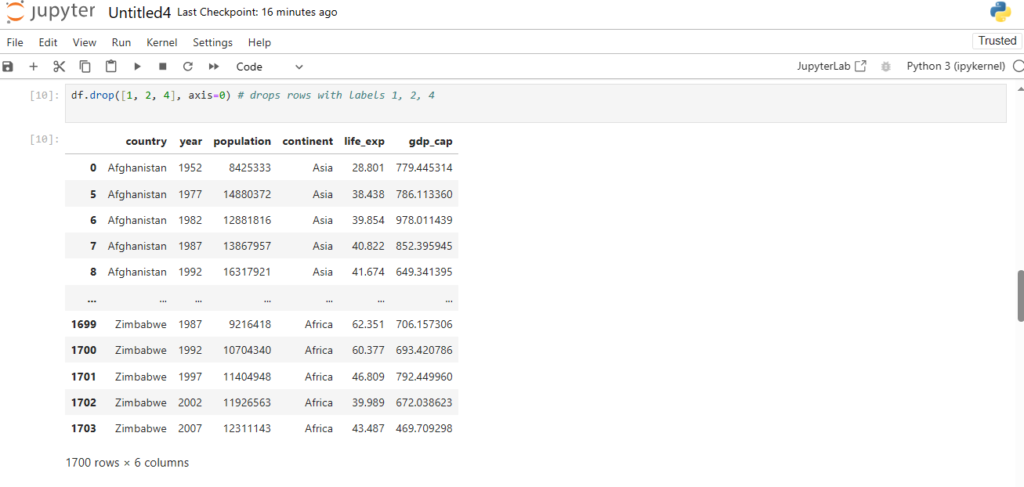
After loading the dataset into a DataFrame (stored in the variable df), you can perform a wide range of operations like filtering, sorting, and analyzing the data.
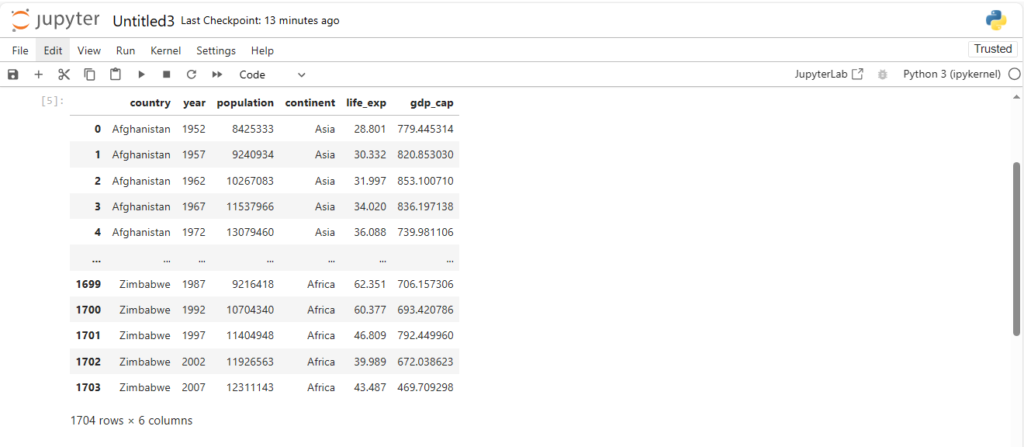
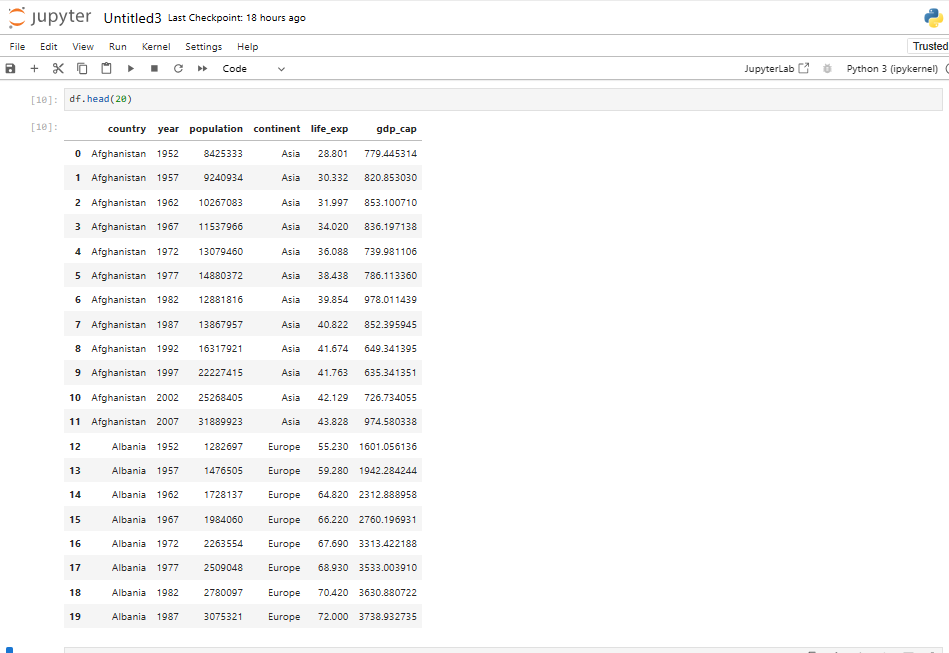
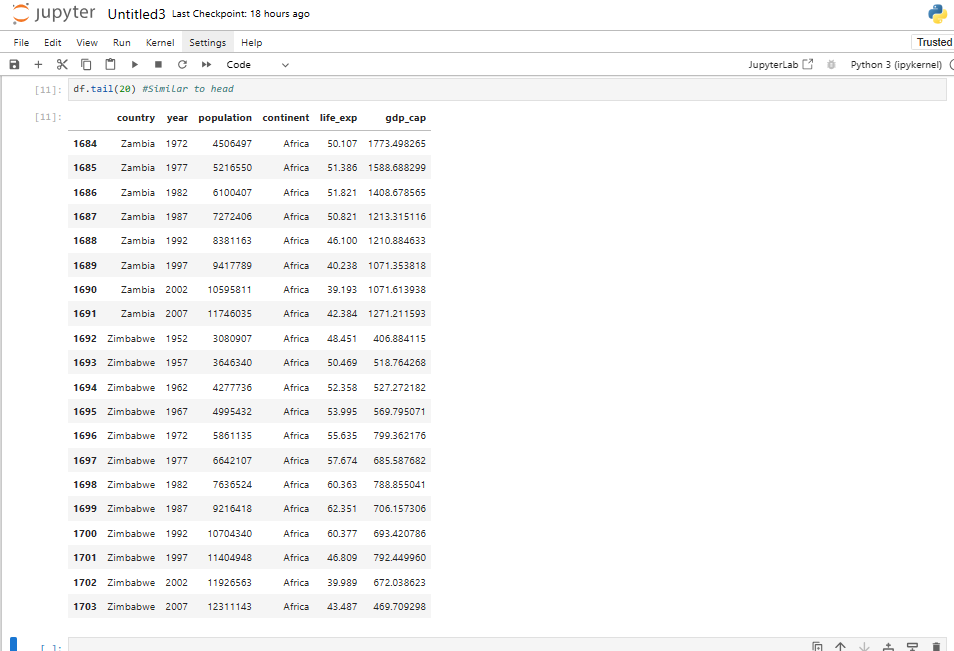
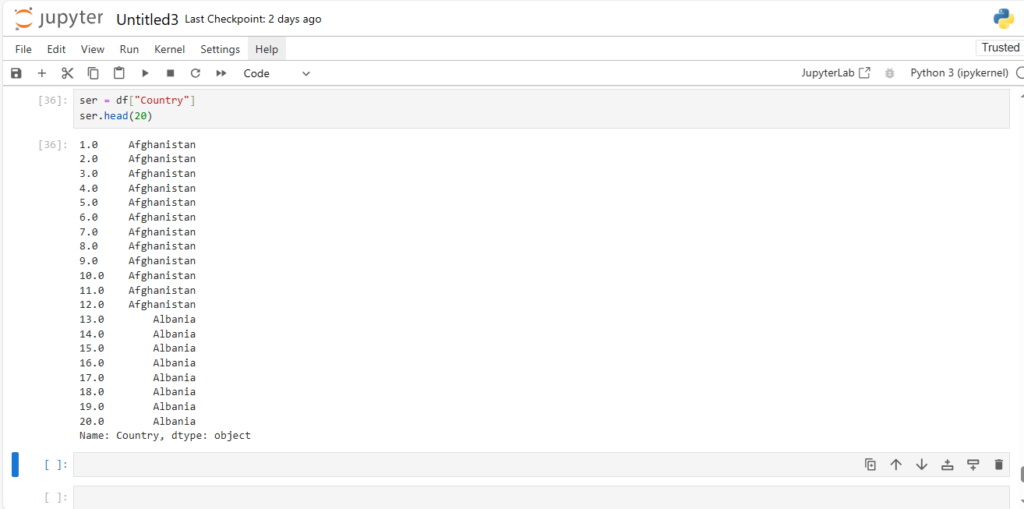
Exploring the Dataset
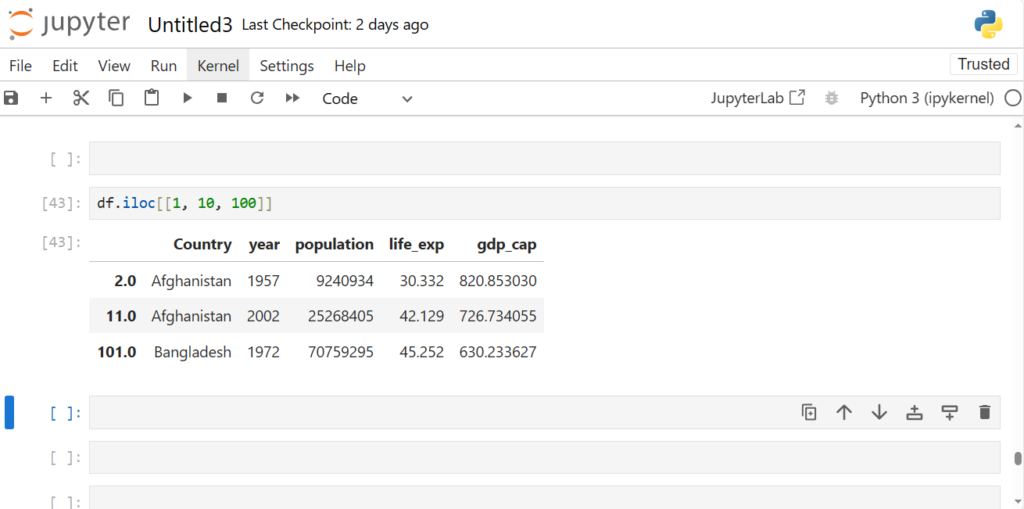
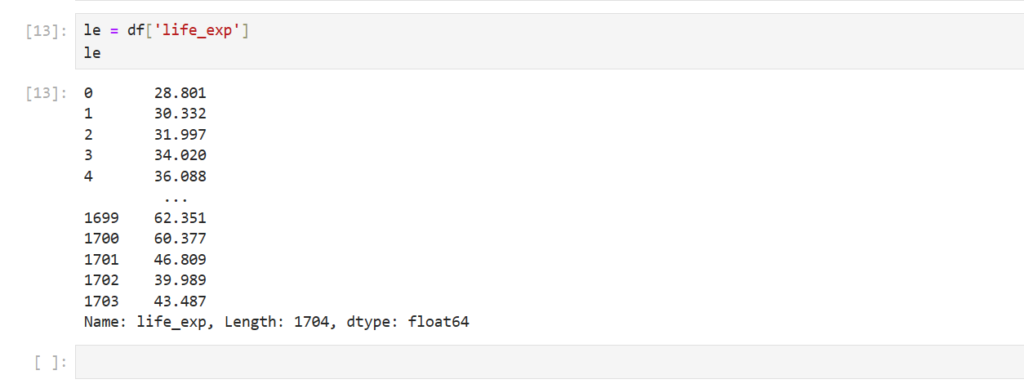
Once the dataset is loaded, you can simply print it using the command:
df
This will display the contents of the DataFrame. Pandas automatically handles the data types, formats, and data structure, making it much easier to explore and manipulate the data.