SQL Concepts for Data Analysts (डेटा एनालिस्ट के लिए SQL कॉन्सेप्ट्स)
SQL क्या है?
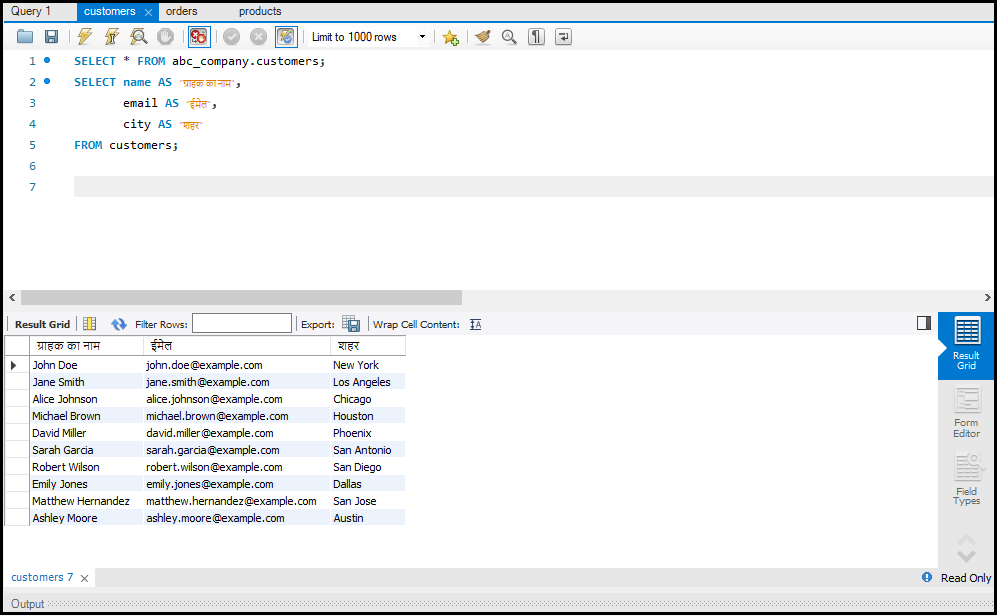
SQL (Structured Query Language) एक मानक भाषा है, जिसका उपयोग डेटाबेस से डेटा को डिफाइन, मैनिपुलेट और रिट्रीव करने के लिए किया जाता है। इसका उपयोग डेटा को स्टोर, एक्सेस और एनालाइज करने में किया जाता है।
SQL की प्रमुख ऑपरेशन्स
SQL का उपयोग कई प्रकार के ऑपरेशन्स को करने के लिए किया जाता है, जैसे:
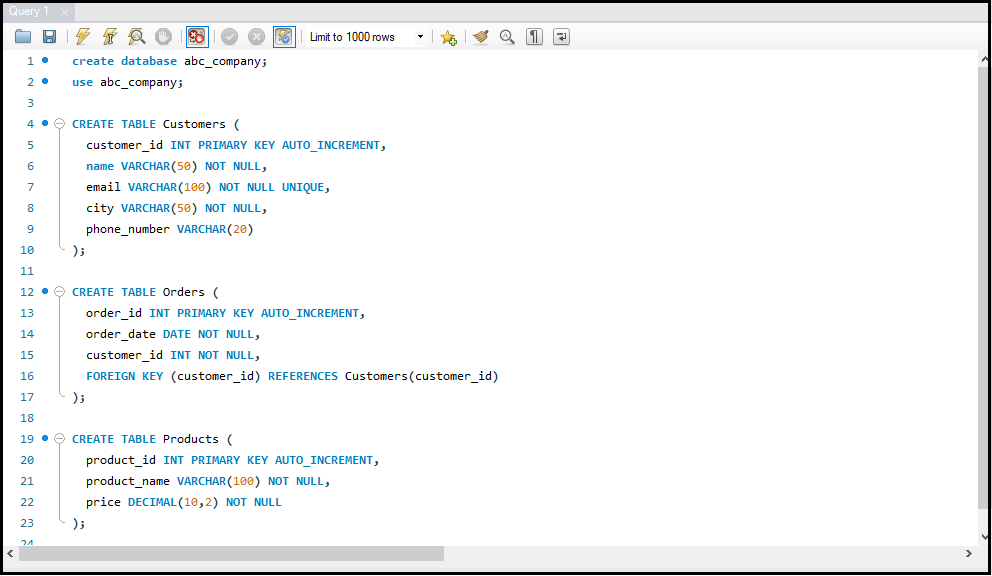
- Database बनाना और हटाना: `CREATE DATABASE` और `DROP DATABASE` का उपयोग करके।
- Tables बनाना और हटाना: `CREATE TABLE` और `DROP TABLE` का उपयोग करके।
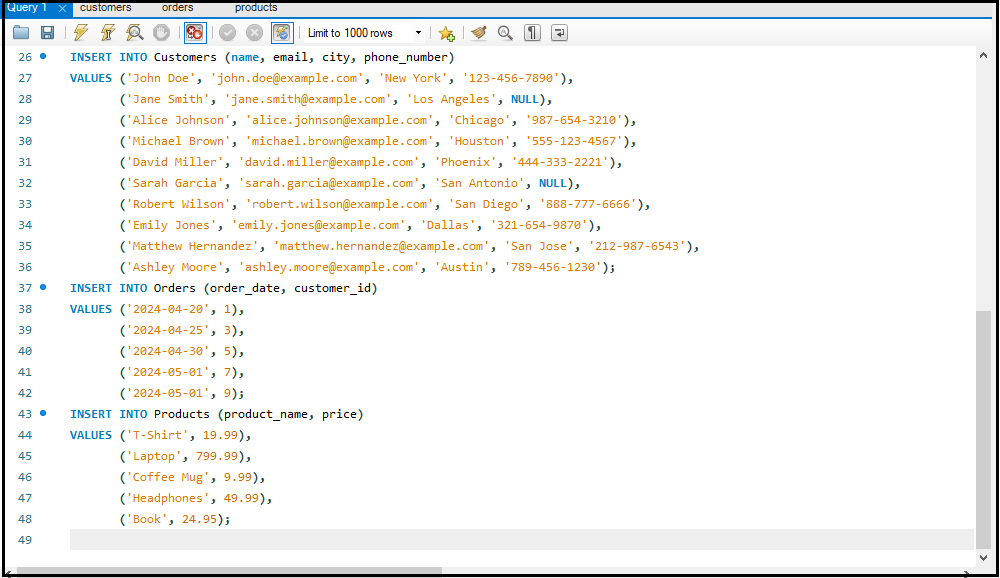
- Data Insert करना: `INSERT INTO` का उपयोग करके।
- Data Update करना: `UPDATE` का उपयोग करके।
- Data Delete करना: `DELETE FROM` का उपयोग करके।
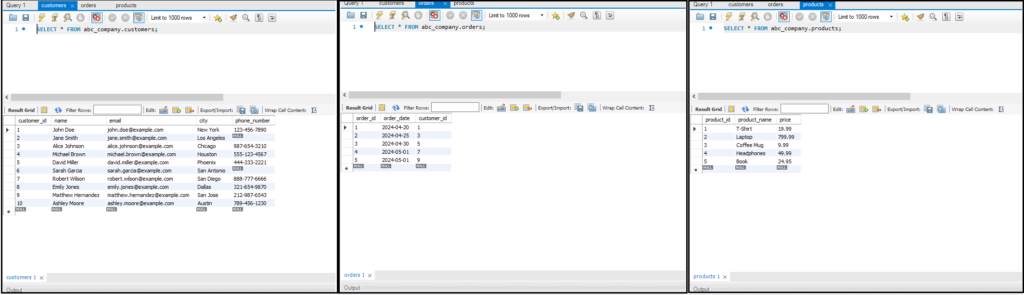
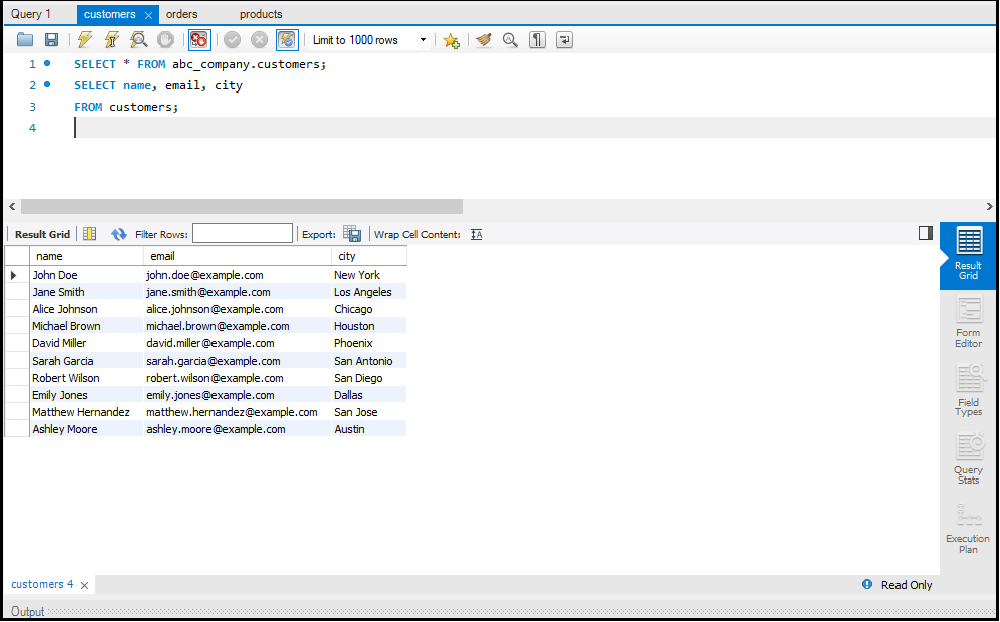
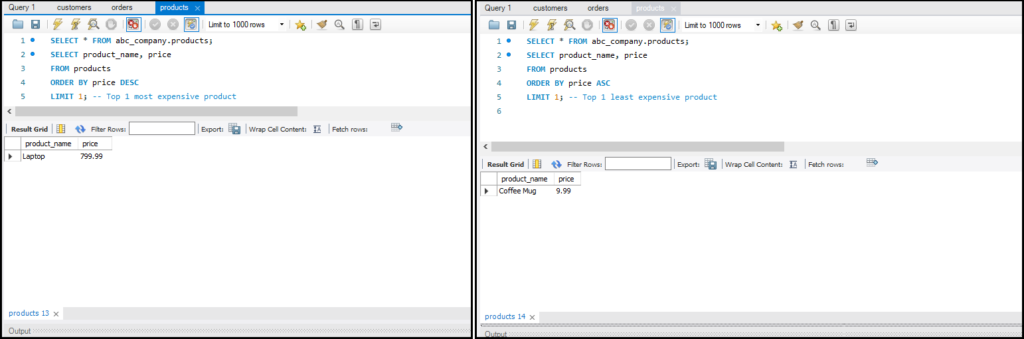
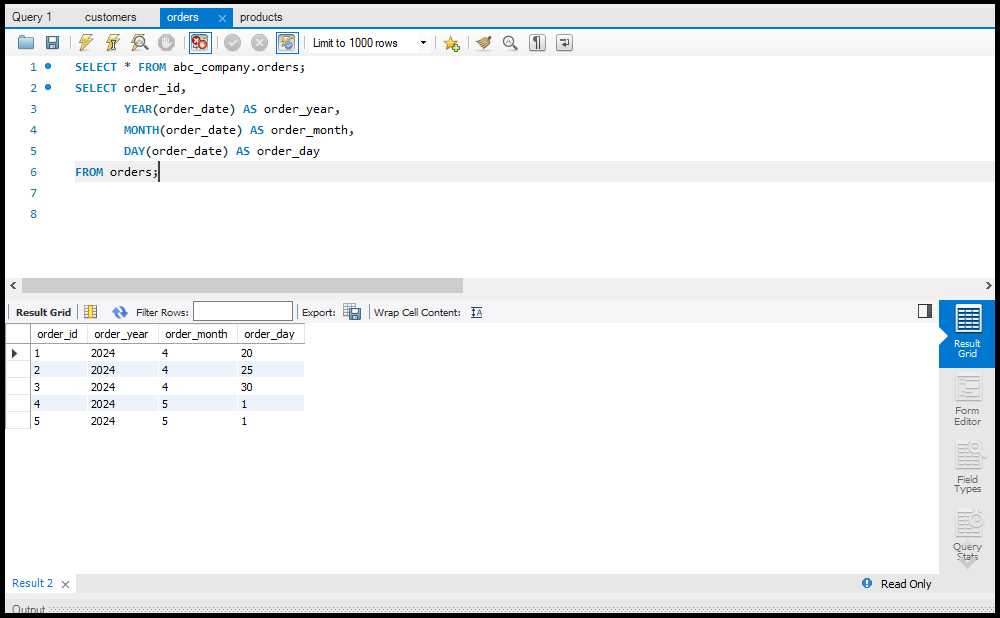
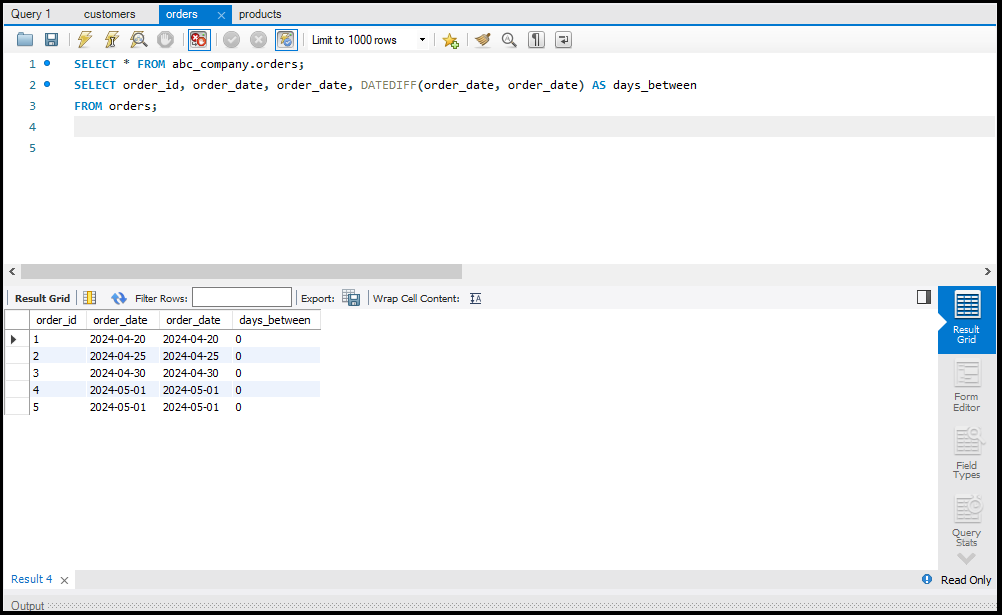
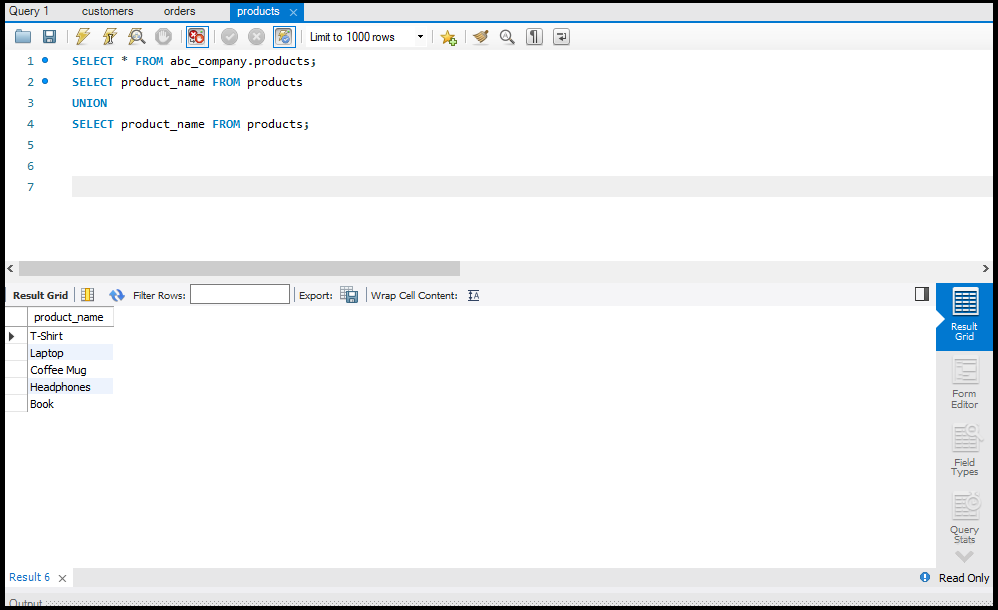
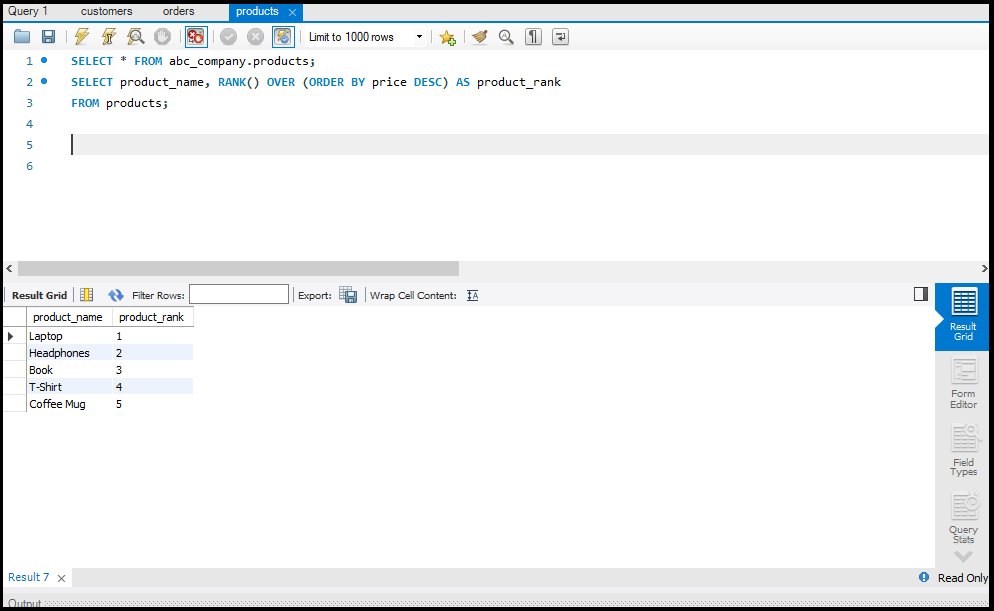
- Data Select करना: `SELECT` का उपयोग करके।
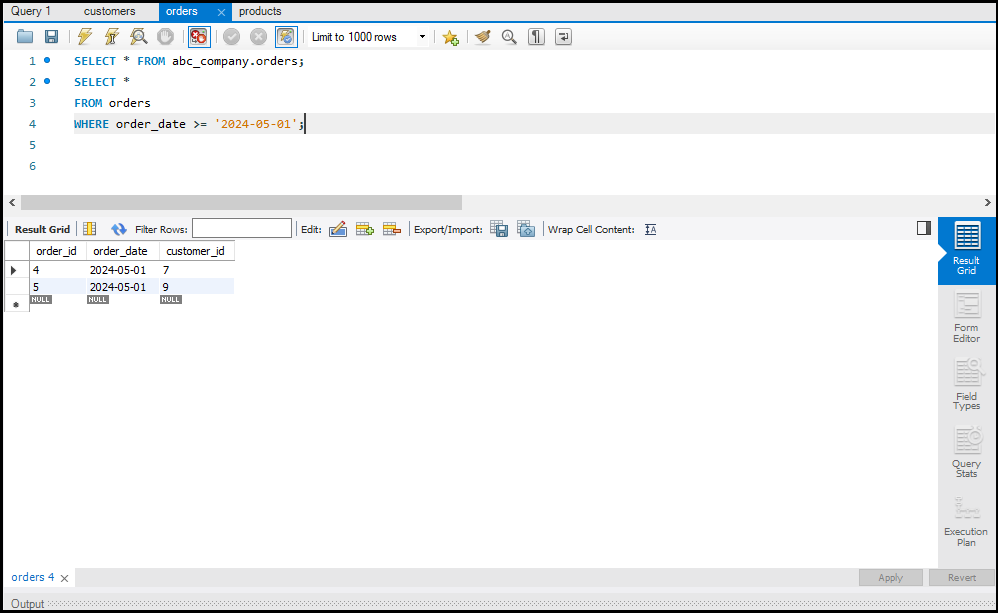
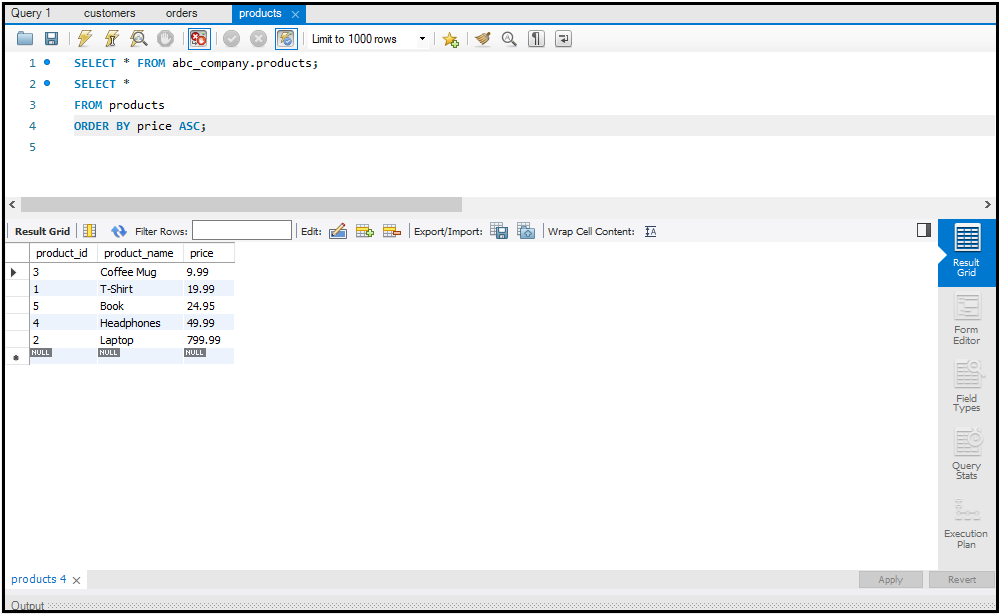
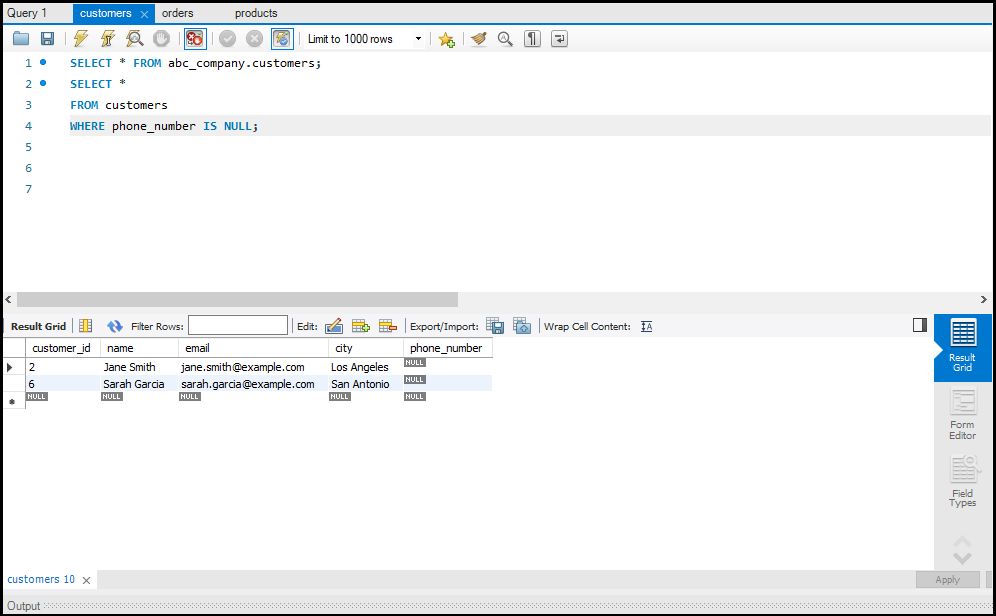
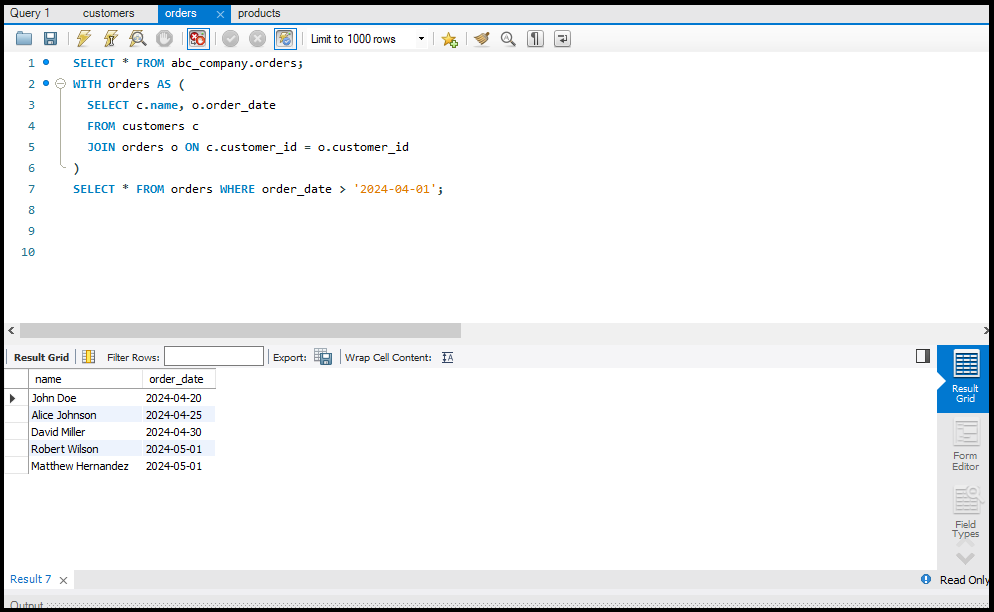
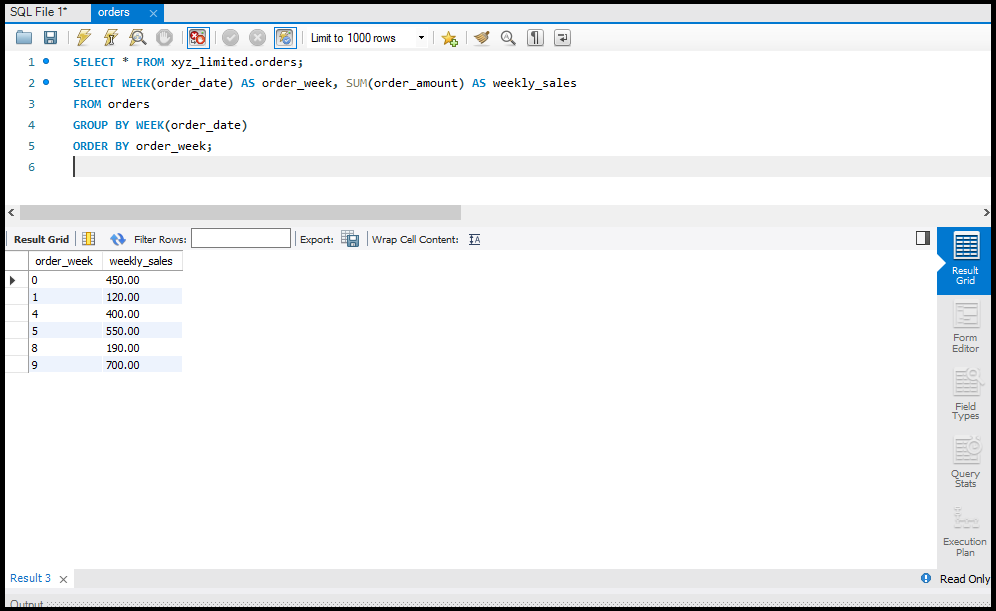
Data को Sort और Filter करना
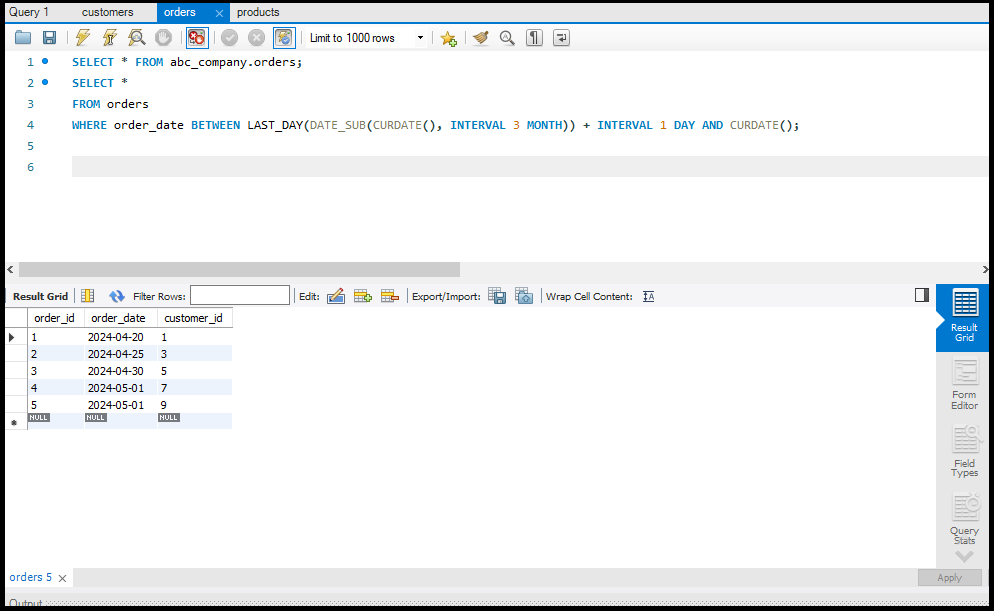
`ORDER BY` का उपयोग करके आप डेटा को सॉर्ट कर सकते हैं और `WHERE` क्लॉज़ का उपयोग करके आप डेटा को फिल्टर कर सकते हैं। ये ऑपरेशन्स बड़े डेटा सेट्स को सटीक रूप से देखने में मदद करते हैं।
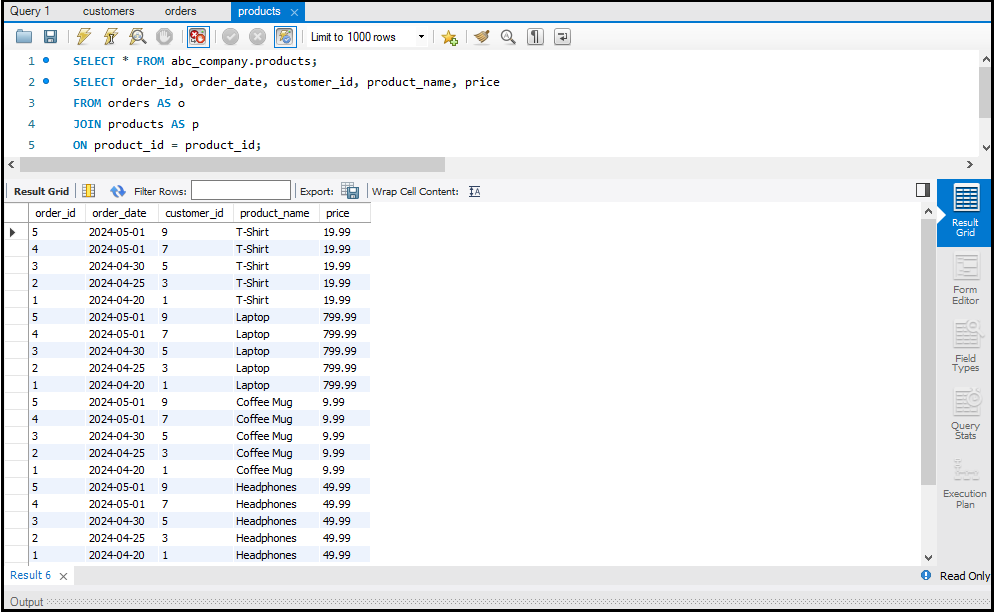
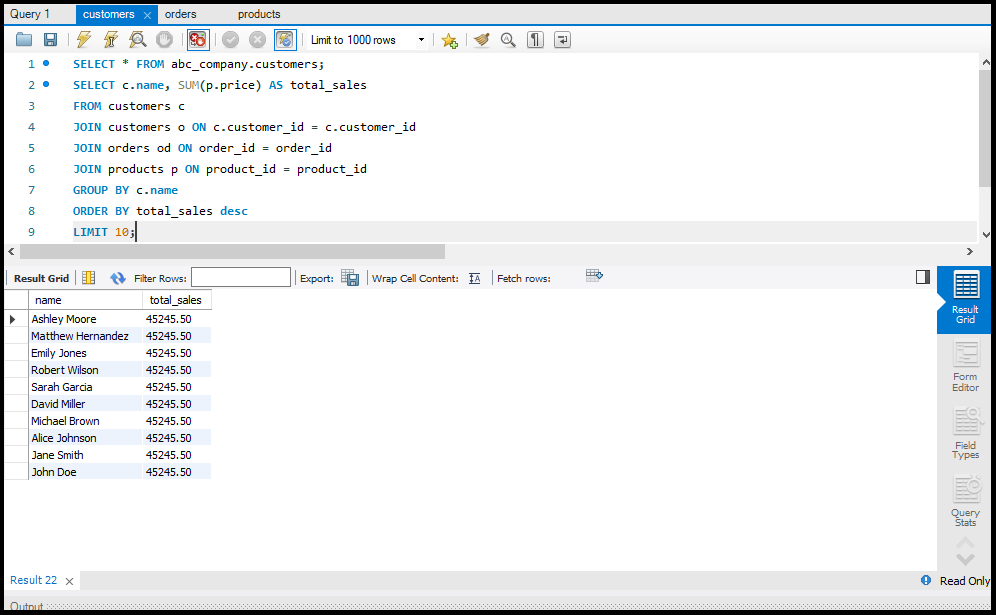
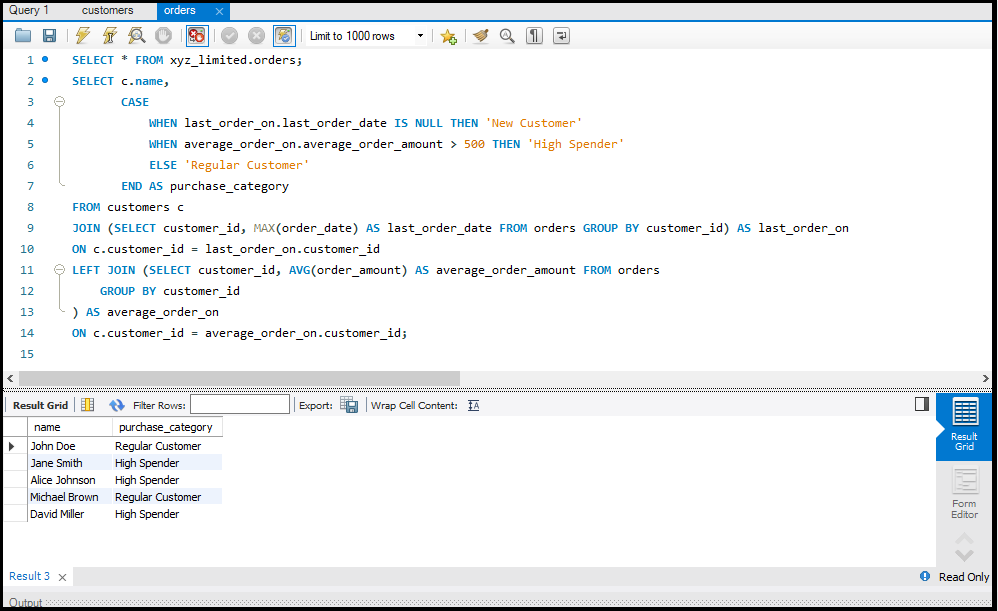
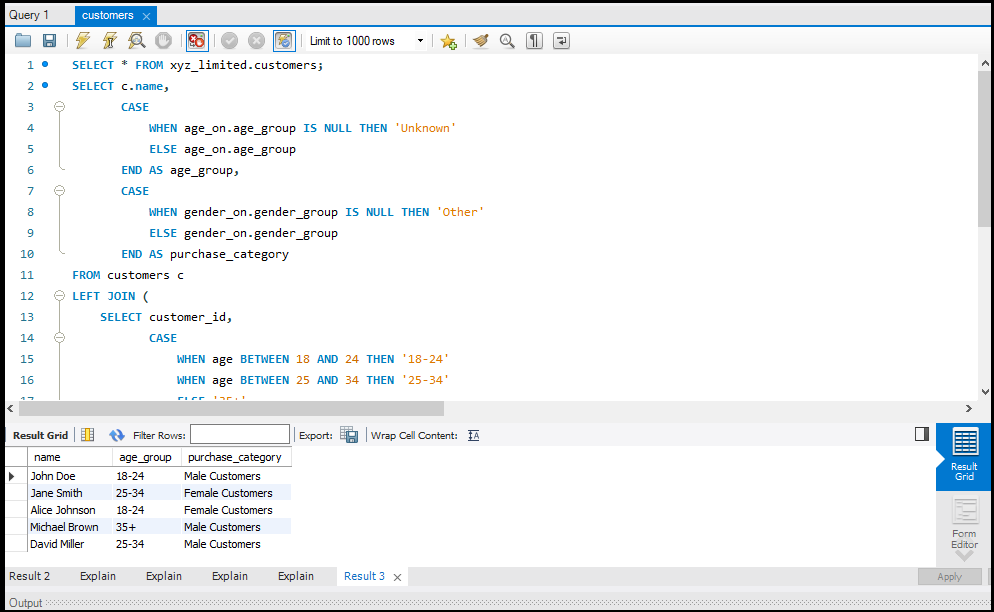
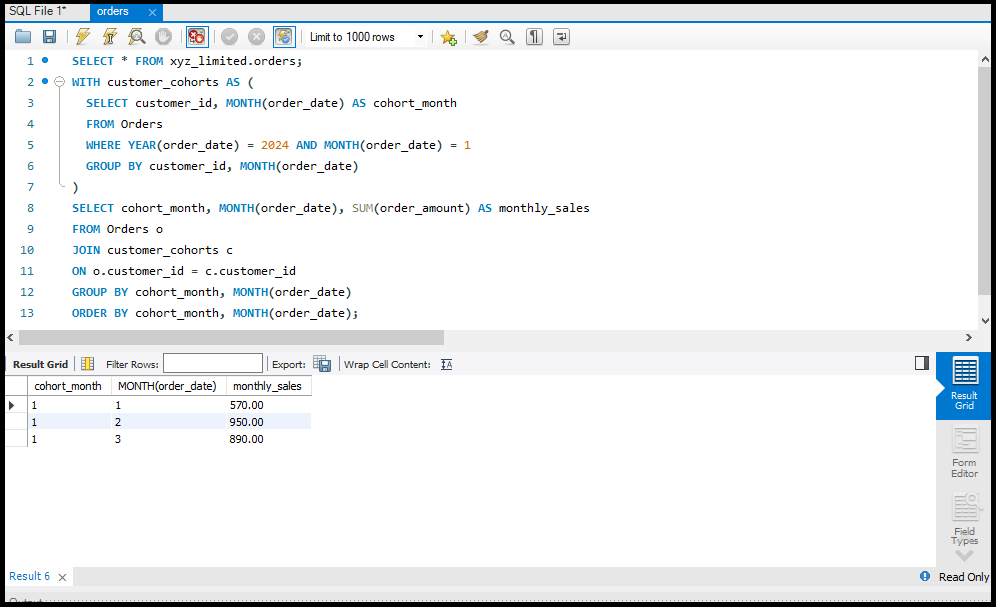
SQL Joins
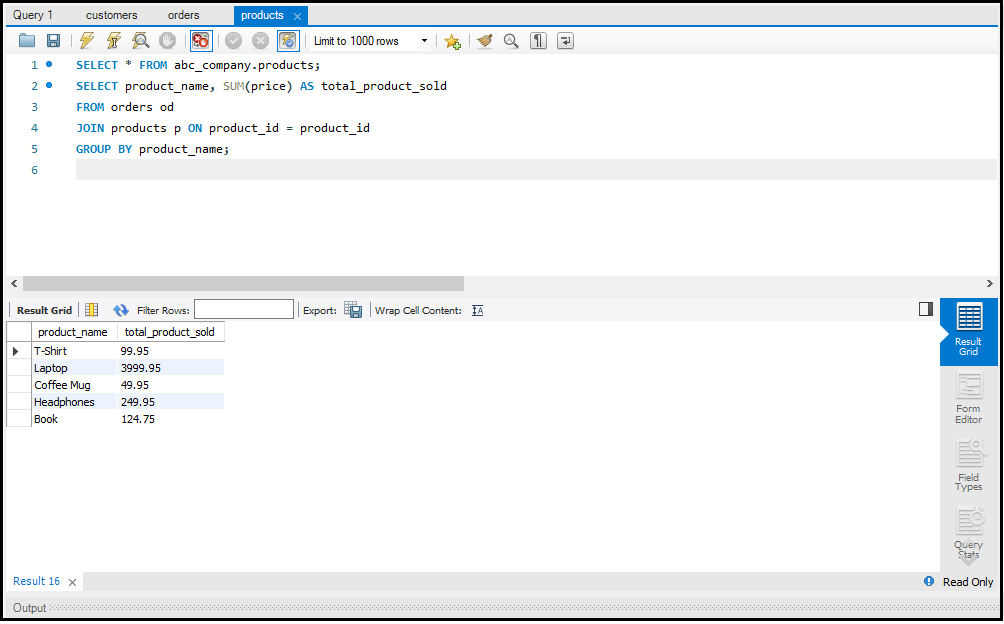
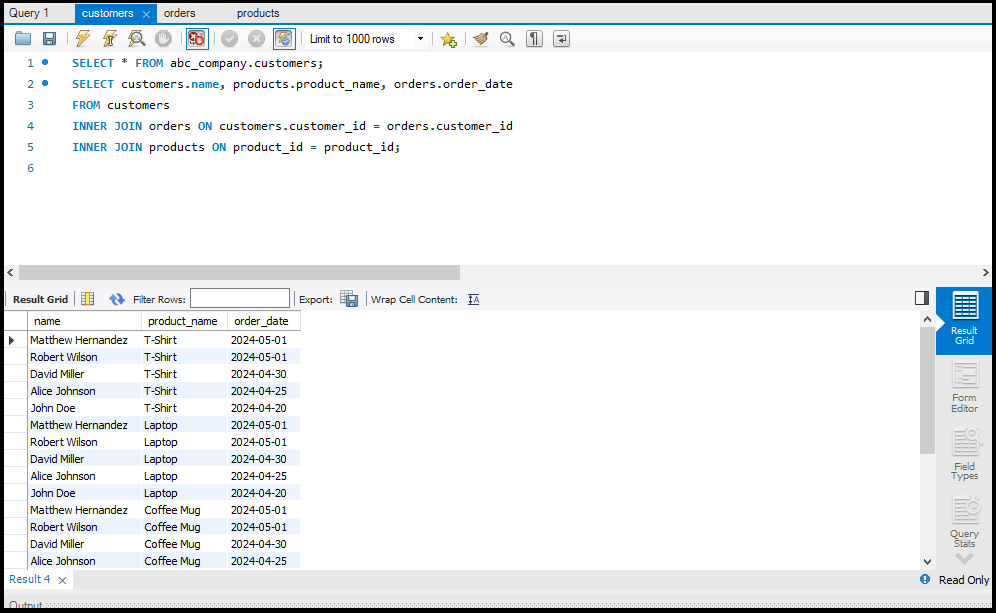
`JOIN` क्लॉज़ का उपयोग एक से अधिक टेबल्स के डेटा को जोड़ने के लिए किया जाता है। इसके कुछ प्रमुख प्रकार हैं:
- INNER JOIN: केवल उन रिकॉर्ड्स को लौटाता है जो दोनों टेबल्स में मेल खाते हैं।
- LEFT JOIN: बाएं टेबल के सभी रिकॉर्ड्स और दाएं टेबल के मेल खाने वाले रिकॉर्ड्स को लौटाता है।
- RIGHT JOIN: दाएं टेबल के सभी रिकॉर्ड्स और बाएं टेबल के मेल खाने वाले रिकॉर्ड्स को लौटाता है।
- FULL OUTER JOIN: दोनों टेबल्स के मेल खाने वाले और न मेल खाने वाले सभी रिकॉर्ड्स को लौटाता है।
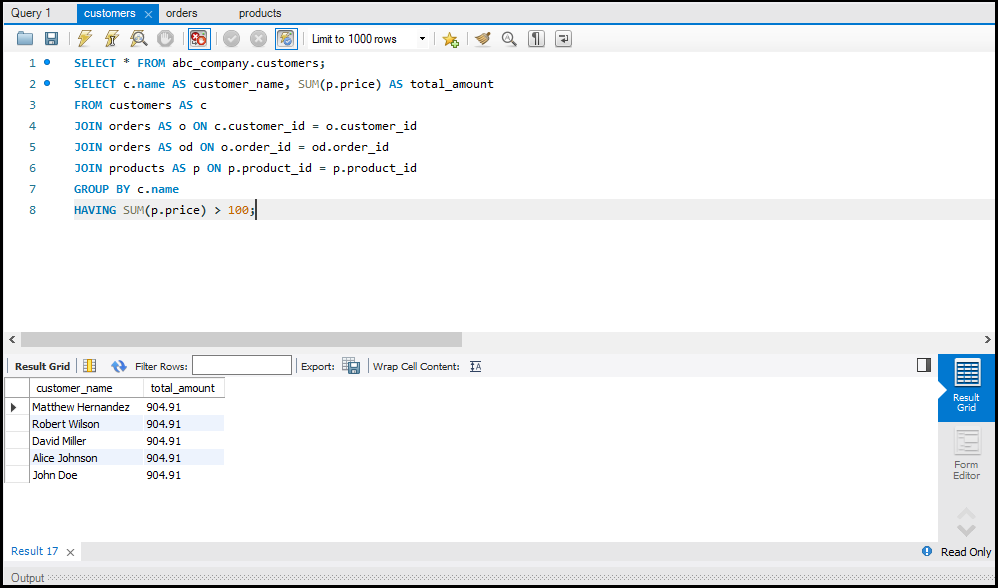
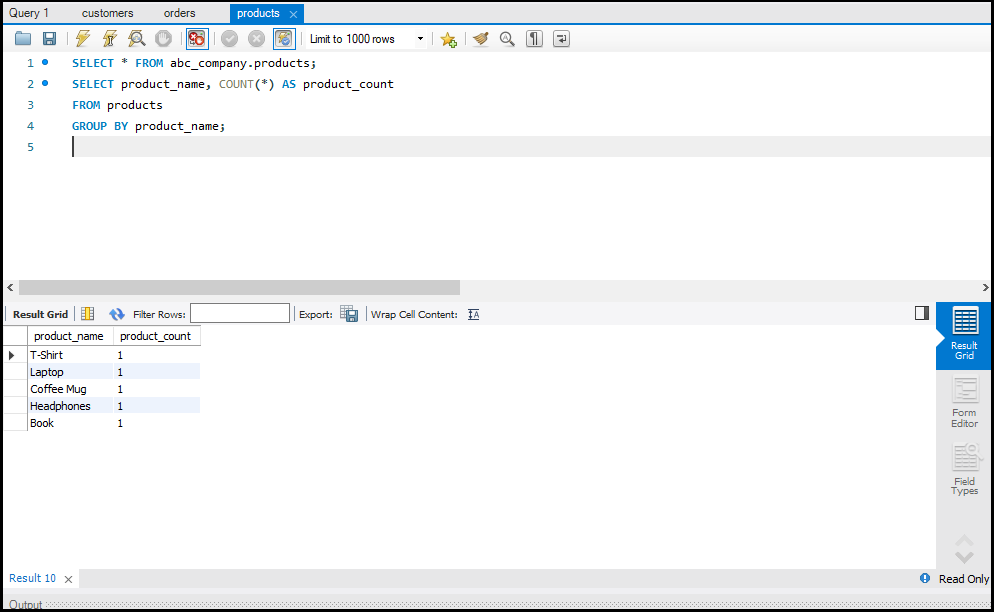
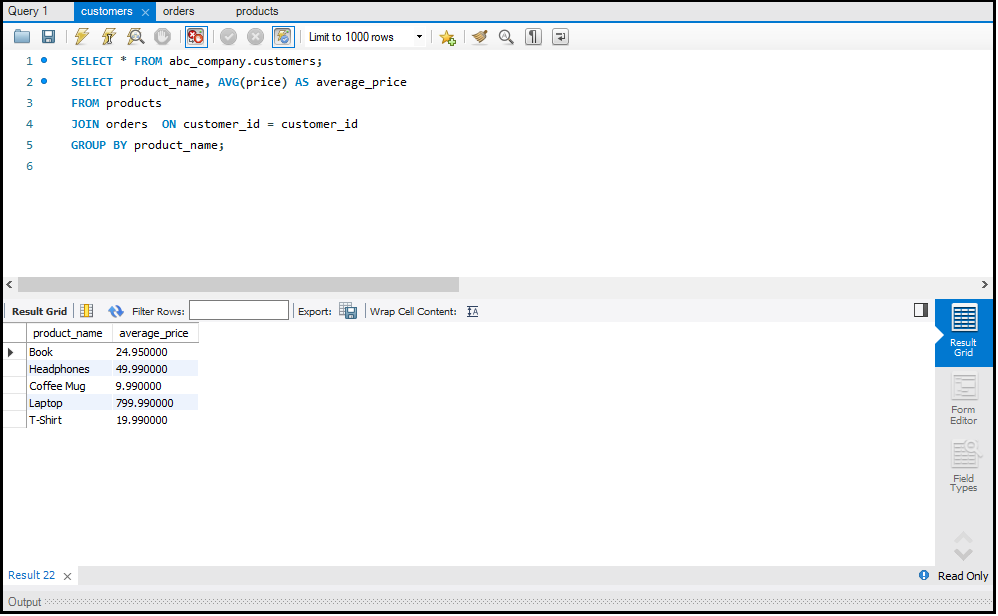
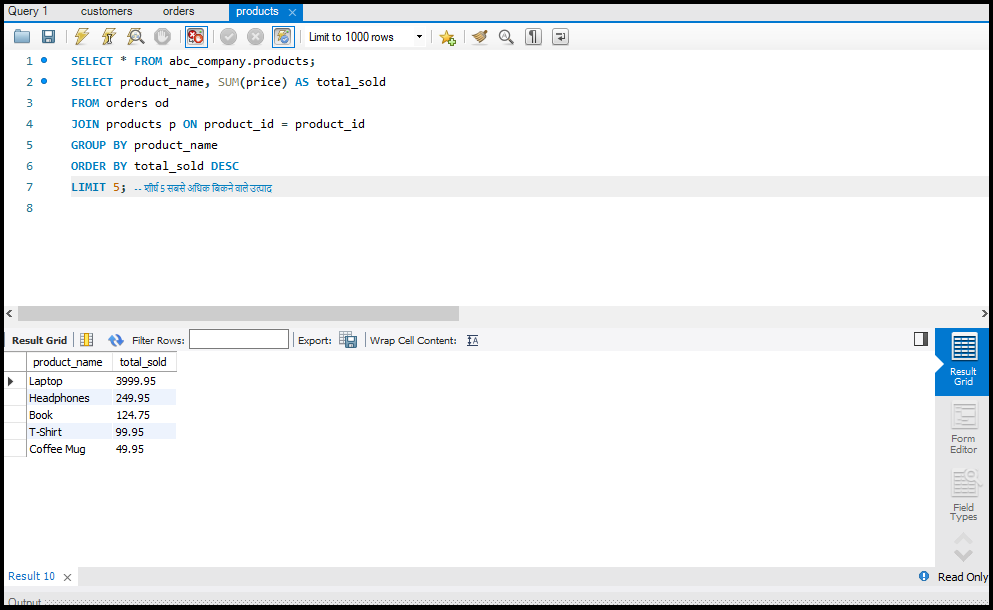
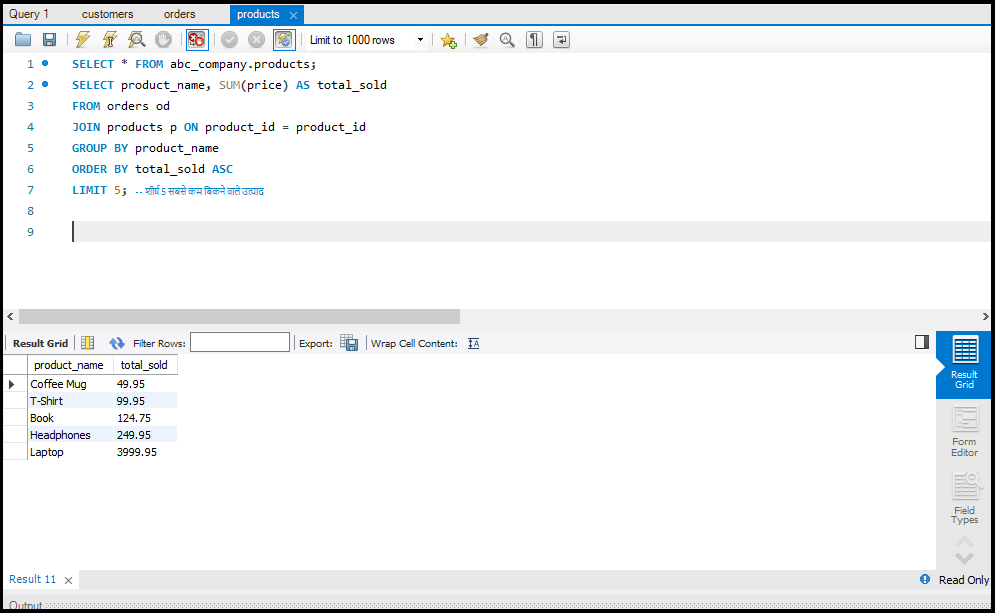
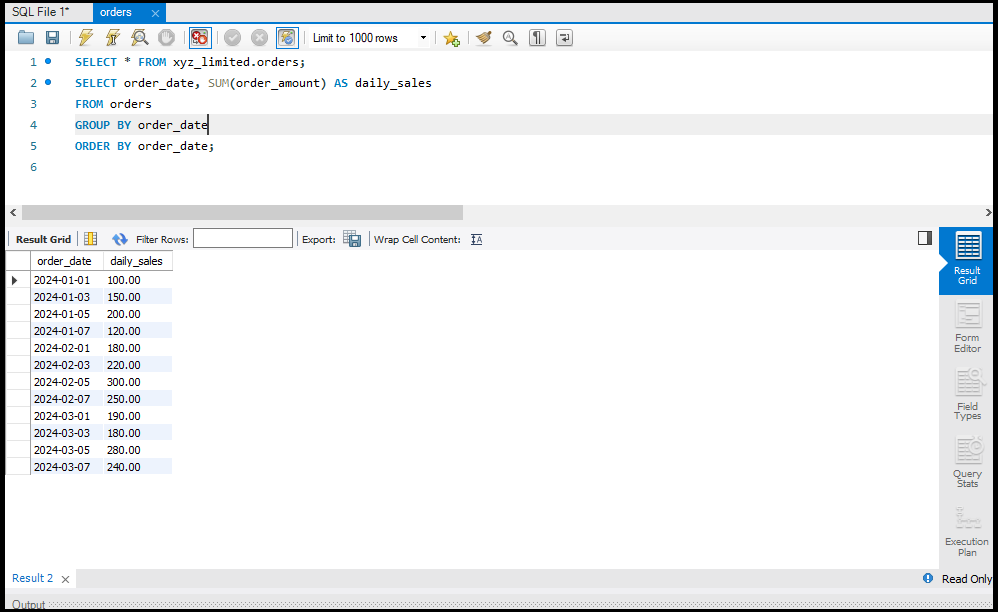
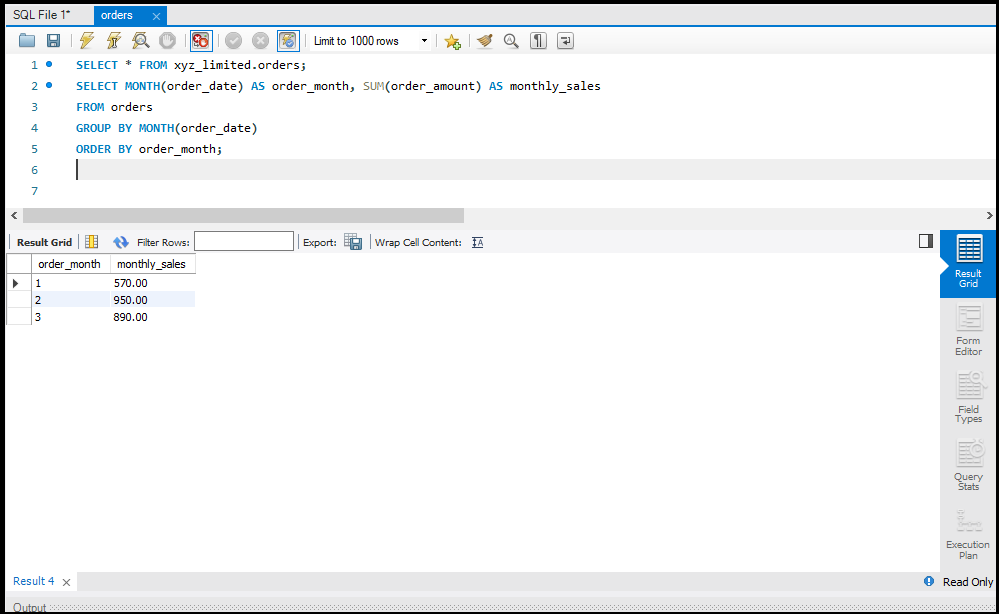
SQL में Data को Aggregate करना
डेटा को सारांशित करने के लिए हम Aggregate Functions जैसे `SUM`, `AVG`, और `COUNT` का उपयोग करते हैं।
- SUM: एक कॉलम के सभी वैल्यूज़ का योग करता है।
- AVG: एक कॉलम के सभी वैल्यूज़ का औसत निकालता है।
- COUNT: रिकॉर्ड्स की संख्या गिनता है।
SQL क्यों सीखें?
SQL डेटा एनालिस्ट के लिए एक आवश्यक कौशल है क्योंकि यह आपको बड़े पैमाने पर डेटा को प्रभावी रूप से प्रबंधित और विश्लेषण करने में मदद करता है। SQL सीखकर आप डेटा से महत्वपूर्ण इनसाइट्स निकाल सकते हैं और व्यवसाय निर्णयों को बेहतर बना सकते हैं।