

Statistics क्या है?
Table of Contents
Toggleयदि आप Data Analytics, Data Science, Machine Learning, Artificial Intelligence या Business Analytics सीखना चाहते हैं, तो Statistics आपकी सबसे महत्वपूर्ण Foundation है। Python आपको Data पर काम करना सिखाता है, लेकिन Statistics आपको Data को समझना सिखाता है।
आज की Digital World में हर सेकंड लाखों Records Generate होते हैं। जब आप Instagram Scroll करते हैं, Amazon से Shopping करते हैं, Netflix पर Movie देखते हैं या UPI Payment करते हैं, तब Data बनता है। लेकिन केवल Data होना पर्याप्त नहीं है। असली शक्ति उस Data को समझने और उससे सही Decision लेने में है।
यहीं पर Statistics हमारी मदद करता है। Statistics हमें Data के पीछे छिपे Patterns, Trends और Relationships को समझने में सहायता करता है ताकि हम भविष्य के बारे में बेहतर अनुमान लगा सकें और सही निर्णय ले सकें।
Statistics की सरल परिभाषा
Statistics एक ऐसी Science है जो Data को Collect, Organize, Analyze और Interpret करने का कार्य करती है ताकि हम सही निष्कर्ष (Conclusions) निकाल सकें और बेहतर Decisions ले सकें।

ऊपर दिए गए Workflow में आप देख सकते हैं कि Statistics केवल Numbers का खेल नहीं है। यह Raw Data को Valuable Insights में बदलने की पूरी प्रक्रिया है। यही कारण है कि Data Analytics, Data Science और Machine Learning में Statistics को सबसे महत्वपूर्ण Skill माना जाता है।
Statistics क्यों सीखें?
बहुत से Students सीधे Python, Power BI, SQL या Machine Learning सीखना शुरू कर देते हैं। लेकिन जब उन्हें Data को समझना और Analyze करना होता है, तब Statistics की आवश्यकता महसूस होती है। Statistics केवल Exam पास करने के लिए नहीं बल्कि Real-World Problems को Solve करने के लिए सीखी जाती है।
Data Analytics में Statistics का उपयोग
Data Analytics का मुख्य उद्देश्य Data को समझना और Business Problems का समाधान ढूँढना है। Statistics Data Analyst को यह समझने में मदद करता है कि किसी Dataset में क्या हो रहा है और उससे कौन-से Business Insights निकाले जा सकते हैं।
मान लीजिए किसी E-Commerce Company के पास 1 लाख Customers का Data है। Statistics की सहायता से Analyst निम्न सवालों के जवाब प्राप्त कर सकता है:
💡 Data Analytics में लगभग हर Dashboard, KPI Report और Business Insight के पीछे Statistics काम करता है।
Data Science में Statistics का उपयोग
Data Science का उद्देश्य केवल Reports बनाना नहीं बल्कि भविष्य की घटनाओं का अनुमान लगाना और Data से Intelligent Insights निकालना है। Statistics Data Scientist को Data को समझने, Models बनाने और Predictions करने में मदद करता है।
उदाहरण के लिए, Netflix Statistics और Data Science का उपयोग करके यह अनुमान लगाता है कि आप अगली कौन-सी Movie या Series देखना पसंद करेंगे।
Machine Learning में Statistics का उपयोग
Machine Learning वास्तव में Statistics का Advanced Application है। यदि आपकी Statistics मजबूत है, तो Machine Learning Algorithms को समझना और Implement करना बहुत आसान हो जाता है।
आज Recommendation Systems, Spam Detection, Fraud Detection और AI Applications के पीछे Statistics और Machine Learning दोनों मिलकर कार्य करते हैं।
Key Takeaway 🚀
Statistics Data Analytics, Data Science और Machine Learning की नींव है। यह हमें Data को समझने, Patterns पहचानने, Business Insights निकालने और बेहतर Decisions लेने में मदद करता है। यदि आप Python के साथ Data Analytics सीखना चाहते हैं, तो Statistics आपका पहला और सबसे महत्वपूर्ण कदम है।
आगे क्या सीखेंगे?
अब जब आपने Statistics की Basics समझ ली हैं, अगले Section में हम Data और Statistics का संबंध, Types of Data, Numerical Data, Categorical Data, Discrete Data और Continuous Data को आसान उदाहरणों के साथ समझेंगे। यही Concepts आगे आने वाले Mean, Median, Mode, Probability और Machine Learning Topics को समझने की मजबूत Foundation बनाएँगे।
Data और Statistics का संबंध
पिछले Section में हमने जाना कि Statistics क्या है और यह Data Analytics, Data Science तथा Machine Learning में क्यों महत्वपूर्ण है। लेकिन Statistics को समझने से पहले हमें Data को समझना होगा, क्योंकि Statistics का पूरा आधार Data पर ही टिका हुआ है।
सरल शब्दों में, Data बिना Statistics अधूरा है और Statistics बिना Data बेकार है। यदि Data कच्चा माल (Raw Material) है, तो Statistics वह Tool है जो उस Data को उपयोगी Information और Insights में बदलता है।
Data + Statistics = Smart Decisions
Raw Data हमें केवल Numbers दिखाता है, जबकि Statistics हमें उन Numbers का अर्थ समझाता है।
Data क्या है?
Data किसी भी जानकारी (Information) का कच्चा रूप होता है। यह Numbers, Text, Images, Transactions, Ratings या किसी भी प्रकार की Observations हो सकती हैं।
उदाहरण के लिए:
जब किसी कंपनी के पास लाखों Records होते हैं, तब केवल Data देखकर निर्णय लेना मुश्किल हो जाता है। इसलिए Statistics की आवश्यकता पड़ती है।
Statistics और Data का संबंध
Statistics का मुख्य कार्य Data को Analyze करके Meaningful Information निकालना है। Statistics हमें यह बताता है कि Data क्या कह रहा है, कौन-सा Trend चल रहा है और भविष्य में क्या होने की संभावना है।
💡 याद रखें: Data हमें Facts देता है और Statistics उन Facts का Meaning समझाता है।
Types of Data (Data के प्रकार)
Data Science और Analytics में Data को मुख्य रूप से दो Categories में बाँटा जाता है:
आगे Statistics में Mean, Median, Correlation और Machine Learning Models का उपयोग करने से पहले यह समझना बहुत जरूरी है कि आपका Data Numerical है या Categorical।
Numerical Data क्या है?
Numerical Data वह Data होता है जिसे Numbers में व्यक्त किया जा सकता है और जिस पर Mathematical Calculations की जा सकती हैं।
इस प्रकार के Data पर Average, Sum, Percentage, Standard Deviation जैसी Calculations की जाती हैं।
उदाहरण के लिए यदि किसी कंपनी के 100 Employees की Salary Data उपलब्ध है, तो हम Average Salary, Highest Salary और Salary Distribution आसानी से निकाल सकते हैं।
Categorical Data क्या है?
Categorical Data वह Data होता है जो किसी Category, Group या Label को दर्शाता है। इस प्रकार के Data पर सीधे Mathematical Calculations नहीं की जा सकतीं।
Categorical Data हमें यह बताता है कि कोई व्यक्ति, वस्तु या घटना किस Category में आती है।
मान लीजिए किसी E-Commerce Website पर Customers के Gender और Product Category का Data है। यहाँ हम Average Gender नहीं निकाल सकते क्योंकि Gender एक Category है, Number नहीं।
Numerical Data vs Categorical Data
Examples: Marks, Salary, Age, Height
Examples: Gender, City, Product Type
Key Takeaway 🚀
Data Statistics की Foundation है। Statistics Data को Analyze करके Meaningful Insights निकालता है। Data मुख्य रूप से दो प्रकार का होता है: Numerical Data और Categorical Data। इन दोनों को समझना Data Analytics, Data Science और Machine Learning सीखने का पहला महत्वपूर्ण कदम है।
आगे क्या सीखेंगे?
अगले Section में हम Descriptive Statistics को विस्तार से समझेंगे, जहाँ Mean, Median, Mode और Range जैसे सबसे महत्वपूर्ण Statistical Measures को Python Examples के साथ सीखेंगे।
Statistics के प्रकार
Statistics की दुनिया बहुत बड़ी है, लेकिन इसे समझना आसान हो जाता है जब हम इसे दो मुख्य भागों में बाँटते हैं। Data को समझने और उससे निर्णय लेने के लिए Statistics को मुख्य रूप से Descriptive Statistics और Inferential Statistics में विभाजित किया जाता है।
Statistics के दो मुख्य प्रकार
📊 Descriptive Statistics → Data में क्या हुआ?
🔮 Inferential Statistics → आगे क्या हो सकता है?
Descriptive Statistics
Descriptive Statistics का उपयोग Data को Summarize और Describe करने के लिए किया जाता है। जब किसी Dataset में हजारों Records होते हैं, तब प्रत्येक Record को पढ़ना संभव नहीं होता। इसलिए हम पूरे Data को कुछ महत्वपूर्ण Metrics में बदल देते हैं।
उदाहरण के लिए यदि किसी कंपनी की 12 महीनों की Sales Data है, तो Descriptive Statistics हमें Average Sales, Highest Sales और Lowest Sales जैसी महत्वपूर्ण जानकारी तुरंत प्रदान कर सकता है।
💡 Descriptive Statistics का मुख्य उद्देश्य Data को आसान और समझने योग्य बनाना है।
Descriptive Statistics का उपयोग
Inferential Statistics
Inferential Statistics का उपयोग Sample Data के आधार पर पूरी Population के बारे में निष्कर्ष निकालने के लिए किया जाता है। यह केवल Data को Describe नहीं करता बल्कि भविष्य की संभावनाओं का अनुमान भी लगाता है।
जब किसी कंपनी के पास लाखों Customers होते हैं, तब हर Customer का अध्ययन करना संभव नहीं होता। इसलिए कुछ Customers का Sample लिया जाता है और उसके आधार पर पूरे समूह के बारे में निर्णय लिया जाता है।
💡 Election Polls, Market Research और Customer Surveys में सबसे अधिक उपयोग Inferential Statistics का होता है।
Descriptive vs Inferential Statistics
Focus: क्या हुआ?
Mean, Median, Mode, Range
Focus: क्या हो सकता है?
Hypothesis Testing, Confidence Interval
Section Summary 🚀
Statistics मुख्य रूप से दो भागों में विभाजित है। Descriptive Statistics Data को समझने और Summarize करने में मदद करता है, जबकि Inferential Statistics उसी Data के आधार पर भविष्यवाणी और निर्णय लेने में सहायता करता है। Data Analytics, Data Science और Machine Learning में दोनों की महत्वपूर्ण भूमिका है।
Descriptive Statistics
Descriptive Statistics Statistics का वह भाग है जिसका उपयोग Data को Summarize, Organize और Describe करने के लिए किया जाता है। जब किसी Dataset में हजारों Records होते हैं, तब पूरे Data को एक-एक करके समझना कठिन हो जाता है। ऐसे में Descriptive Statistics Data को कुछ महत्वपूर्ण Numbers और Visualizations में बदल देता है।
Data Analytics में सबसे पहला कार्य Data को समझना होता है और यहीं पर Descriptive Statistics की भूमिका शुरू होती है। यह हमें बताता है कि Data का औसत क्या है, Data कितना फैला हुआ है, सबसे सामान्य Value कौन-सी है और Data का Overall Pattern कैसा है।
Descriptive Statistics का मुख्य उद्देश्य
Raw Data को Meaningful Information में बदलना ताकि Trends, Patterns और Insights को आसानी से समझा जा सके।
Descriptive Statistics क्यों महत्वपूर्ण है?
मान लीजिए किसी E-Commerce Company के पास 5 लाख Orders का Data है। यदि Analyst हर Order को अलग-अलग देखने लगे तो Analysis में कई दिन लग सकते हैं। लेकिन यदि Average Order Value, Highest Order Value और Most Common Product निकाल लिया जाए, तो कुछ मिनटों में Business Insights मिल सकती हैं।
Descriptive Statistics के प्रमुख Measures
Descriptive Statistics कई प्रकार के Measures का उपयोग करता है। प्रत्येक Measure Data के बारे में अलग जानकारी देता है।
1. Mean (Average)
Mean Descriptive Statistics का सबसे लोकप्रिय Measure है। इसे सामान्य भाषा में Average कहा जाता है। Mean हमें बताता है कि Data की Typical Value क्या है।
उदाहरण के लिए यदि पाँच Students के Marks 70, 80, 90, 85 और 75 हैं, तो Mean इन सभी Marks का Average होगा।
💡 Business में Mean का उपयोग Average Sales, Average Salary और Average Customer Spending निकालने के लिए किया जाता है।
2. Median
Median Data की बीच वाली Value होती है। जब Data को Ascending या Descending Order में Arrange किया जाता है, तब बीच में आने वाली Value Median कहलाती है।
Median विशेष रूप से तब उपयोगी होता है जब Dataset में Outliers मौजूद हों।
💡 Real Estate Industry में Median House Price Mean से अधिक उपयोगी माना जाता है क्योंकि कुछ बहुत महंगे घर Average को प्रभावित कर सकते हैं।
3. Mode
Mode वह Value होती है जो Dataset में सबसे अधिक बार दिखाई देती है। यह Data के सबसे Common Pattern को दर्शाती है।
यदि किसी Online Store में सबसे अधिक Customers Blue Color Shirt खरीदते हैं, तो Blue Category उस Dataset का Mode मानी जा सकती है।
4. Range
Range Data की सबसे बड़ी और सबसे छोटी Value के बीच का अंतर होता है। यह Data के Spread का सबसे सरल Measure है।
यदि Highest Salary ₹100,000 है और Lowest Salary ₹20,000 है, तो Range ₹80,000 होगी।
5. Variance
Variance यह मापता है कि Data की Values Mean से कितनी दूर फैली हुई हैं। Variance जितना अधिक होगा, Data उतना अधिक बिखरा हुआ होगा।
Data Science और Machine Learning में Variance Model Performance को समझने में महत्वपूर्ण भूमिका निभाता है।
6. Standard Deviation
Standard Deviation Variance का Square Root होता है और यह बताता है कि Data Mean के आसपास कितना Consistent है।
यदि Standard Deviation कम है, तो Data अधिक Consistent है। यदि Standard Deviation अधिक है, तो Values में अधिक Variation मौजूद है।
Section Summary 🚀
Descriptive Statistics Data को समझने का पहला कदम है। Mean, Median, Mode, Range, Variance और Standard Deviation हमें Data के Center, Spread और Pattern को समझने में मदद करते हैं। Data Analytics और Data Science में इन Concepts का दैनिक उपयोग होता है।
Descriptive Statistics को एक उदाहरण से समझें 🚀
मान लीजिए एक छात्र के पाँच विषयों में अंक हैं:
70, 80, 90, 85, 75
Mean = 400 ÷ 5 = 80
यह छात्र का औसत प्रदर्शन दर्शाता है।
70, 75, 80, 85, 90
बीच वाली Value = 80
Median = 80
70, 80, 80, 90, 80
सबसे अधिक बार 80 आया है।
Mode = 80
Lowest Value = 70
Range = 90 − 70 = 20
Variance कम होगा तो Marks अधिक Consistent माने जाएंगे।
यह बताता है कि Data Mean के आसपास कितना Stable या Consistent है।
💡 इस एक उदाहरण से आप समझ सकते हैं कि Mean, Median, Mode, Range, Variance और Standard Deviation सभी एक ही Data को अलग-अलग दृष्टिकोण से समझने में मदद करते हैं। यही कारण है कि Data Analytics और Data Science में Descriptive Statistics सबसे पहला और सबसे महत्वपूर्ण कदम माना जाता है।
Mean (Average) क्या है?
Mean Statistics का सबसे लोकप्रिय और सबसे अधिक उपयोग किया जाने वाला Measure है। सामान्य भाषा में Mean को Average कहा जाता है। जब हम किसी Dataset की Typical Value जानना चाहते हैं, तो सबसे पहले Mean निकाला जाता है।
Mean हमें यह समझने में मदद करता है कि पूरे Data का औसत प्रदर्शन कैसा है। Data Analytics, Business Reporting, Finance और Data Science में Mean का उपयोग लगभग हर जगह किया जाता है।
Mean की सरल परिभाषा
Mean प्राप्त करने के लिए सभी Values को जोड़ा जाता है और फिर कुल Values की संख्या से भाग दिया जाता है।
Mean को समझने के लिए एक सरल उदाहरण
मान लीजिए पाँच छात्रों के अंक इस प्रकार हैं:
70, 80, 90, 85, 75
सभी अंकों का योग:
70 + 80 + 90 + 85 + 75 = 400
कुल छात्रों की संख्या = 5
Mean = 400 ÷ 5 = 80
इसका अर्थ है कि छात्रों का औसत प्रदर्शन 80 अंक है।
Mean का वास्तविक जीवन में उपयोग
Business Example
मान लीजिए किसी दुकान की पाँच दिनों की Sales इस प्रकार है:
₹10,000 • ₹15,000 • ₹20,000 • ₹18,000 • ₹12,000
कुल Sales = ₹75,000
दिन = 5
Average Daily Sales = ₹15,000
अब Store Owner आसानी से समझ सकता है कि सामान्य दिन में उसकी दुकान कितनी Sales करती है।
Mean के फायदे
Mean की सीमाएँ
Mean हमेशा सही तस्वीर नहीं दिखाता। यदि Dataset में बहुत बड़ी या बहुत छोटी Values (Outliers) हों, तो Mean प्रभावित हो सकता है।
Outlier Example
10, 12, 15, 18, 200
यहाँ 200 एक Outlier है। Mean बहुत अधिक बढ़ जाएगा जबकि अधिकांश Values 10 से 20 के बीच हैं। ऐसी स्थिति में Median अधिक उपयोगी होता है।
💡 Interview Tip: यदि Dataset में Outliers मौजूद हों, तो Mean के बजाय Median का उपयोग अधिक उपयुक्त माना जाता है।
Section Summary 🚀
Mean Data का Average Value बताता है और Statistics में सबसे अधिक उपयोग किया जाने वाला Measure है। यह Overall Trend समझने में मदद करता है, लेकिन Outliers होने पर परिणाम प्रभावित हो सकते हैं।
अगले Section में
अब हम Median को समझेंगे और जानेंगे कि Outliers वाले Data में Median अक्सर Mean से बेहतर क्यों माना जाता है।
Median क्या है?
Mean के बाद Statistics में सबसे महत्वपूर्ण Measure Median है। Median Data की बीच वाली (Middle) Value होती है। जब Data को छोटे से बड़े या बड़े से छोटे क्रम में व्यवस्थित किया जाता है, तब बीच में आने वाली Value को Median कहा जाता है।
Median विशेष रूप से तब उपयोगी होता है जब Dataset में Outliers मौजूद हों। ऐसे मामलों में Mean गलत तस्वीर दिखा सकता है, लेकिन Median Data के वास्तविक केंद्र को बेहतर तरीके से दर्शाता है।
Median की सरल परिभाषा
Data को Ascending या Descending Order में Arrange करने के बाद जो Value बीच में आती है, वही Median कहलाती है।
Median को समझने के लिए उदाहरण
मान लीजिए पाँच छात्रों के अंक इस प्रकार हैं:
70, 75, 80, 85, 90
यह Data पहले से क्रम में है। यहाँ बीच वाली Value 80 है।
Median = 80
इसलिए इस Dataset का Median 80 होगा।
Even Number of Values होने पर Median
यदि Dataset में Values की संख्या सम (Even) हो, तो बीच की दो Values का Average निकाला जाता है।
10, 20, 30, 40, 50, 60
बीच की दो Values:
30 और 40
Median = (30 + 40) ÷ 2
Median = 35
Median और Mean में अंतर
आइए एक ऐसा उदाहरण देखते हैं जहाँ Mean और Median अलग-अलग परिणाम देते हैं।
₹20,000 • ₹22,000 • ₹25,000 • ₹28,000 • ₹5,00,000
यहाँ ₹5,00,000 एक Outlier है।
💡 Salary, Property Price और Income Data में Median अक्सर Mean से अधिक उपयोगी माना जाता है।
Median का वास्तविक जीवन में उपयोग
Median के फायदे
Median की सीमाएँ
Quick Comparison
Mean → Average Value बताता है
Median → Middle Value बताता है
Outliers होने पर Median अधिक भरोसेमंद माना जाता है।
Section Summary 🚀
Median Data की मध्य (Middle) Value होती है। यह विशेष रूप से तब उपयोगी होता है जब Dataset में Outliers मौजूद हों। Salary, Income और Property Price Analysis में Median सबसे अधिक उपयोग किए जाने वाले Statistical Measures में से एक है।
अगले Section में
अब हम Mode को समझेंगे और जानेंगे कि किसी Dataset में सबसे अधिक बार आने वाली Value क्यों महत्वपूर्ण होती है।
Mode क्या है?
Mean और Median के बाद Statistics का तीसरा महत्वपूर्ण Measure Mode है। Mode वह Value होती है जो किसी Dataset में सबसे अधिक बार दिखाई देती है।
सरल शब्दों में, यदि हमें यह जानना हो कि किसी Data में कौन-सी Value सबसे ज्यादा बार आई है, तो हम Mode का उपयोग करते हैं।
Mode की सरल परिभाषा
किसी Dataset में सबसे अधिक बार आने वाली Value को Mode कहा जाता है।
Mode को एक सरल उदाहरण से समझें
मान लीजिए एक कक्षा में छात्रों के पसंदीदा रंग इस प्रकार हैं:
Blue, Red, Blue, Green, Blue, Yellow, Blue
यहाँ Blue सबसे अधिक बार दिखाई दे रहा है।
Mode = Blue
इसका अर्थ है कि Blue छात्रों का सबसे लोकप्रिय रंग है।
Numerical Data में Mode
Mode केवल Categories के लिए ही नहीं बल्कि Numbers के लिए भी निकाला जा सकता है।
10, 20, 20, 30, 40, 20, 50
यहाँ 20 सबसे अधिक बार आया है।
Mode = 20
Mode के प्रकार
हर Dataset में केवल एक ही Mode हो, ऐसा जरूरी नहीं है। Dataset के आधार पर Mode तीन प्रकार का हो सकता है।
Example: 10, 20, 20, 30
Example: 10, 20, 20, 30, 30
Example: 10, 10, 20, 20, 30, 30
Business Example
मान लीजिए किसी Online Store पर Customers ने T-Shirt Sizes खरीदीं:
M, L, M, XL, M, L, M
यहाँ Size M सबसे अधिक बार खरीदी गई है।
Mode = M Size
अब Store Owner भविष्य में M Size का अधिक Stock रख सकता है।
💡 Retail और E-Commerce Industry में Mode का उपयोग Most Popular Product, Color, Size और Category पहचानने के लिए किया जाता है।
Mode का वास्तविक जीवन में उपयोग
Mode के फायदे
Mode की सीमाएँ
Mean vs Median vs Mode
Mean → Average Value
Median → Middle Value
Mode → Most Frequent Value
Section Summary 🚀
Mode वह Value होती है जो Dataset में सबसे अधिक बार दिखाई देती है। यह विशेष रूप से Categorical Data और Customer Preference Analysis में बहुत उपयोगी है। E-Commerce, Retail, Marketing और Business Analytics में Mode का उपयोग सबसे लोकप्रिय विकल्पों की पहचान करने के लिए किया जाता है।
अगले Section में
अब हम Range को समझेंगे और जानेंगे कि किसी Dataset में Maximum और Minimum Value का अंतर Data के Spread के बारे में क्या जानकारी देता है।
Range क्या है?
अब तक हमने Mean, Median और Mode जैसे Measures of Central Tendency को समझा, जो Data के Center के बारे में जानकारी देते हैं। लेकिन केवल Data का Center जानना पर्याप्त नहीं है। हमें यह भी समझना होता है कि Data कितना फैला हुआ (Spread Out) है।
यहीं पर Range हमारी मदद करता है। Range Statistics में Data Spread को मापने का सबसे आसान और सबसे सरल तरीका है।
Range की सरल परिभाषा
Range = Highest Value − Lowest Value
अर्थात Dataset की सबसे बड़ी और सबसे छोटी Value के बीच का अंतर Range कहलाता है।
Range को एक सरल उदाहरण से समझें
मान लीजिए पाँच छात्रों के अंक इस प्रकार हैं:
60, 70, 80, 90, 100
यहाँ:
इसका अर्थ है कि छात्रों के Marks 40 अंकों की सीमा (Range) में फैले हुए हैं।
Business Example
मान लीजिए किसी कंपनी की पाँच दिनों की Sales इस प्रकार है:
₹10,000 • ₹15,000 • ₹18,000 • ₹22,000 • ₹30,000
यह Range हमें बताती है कि Sales में कितना उतार-चढ़ाव (Variation) हुआ।
💡 Data Analytics में Range का उपयोग Sales Variation, Employee Salaries और Customer Spending Patterns समझने के लिए किया जाता है।
Range हमें क्या बताता है?
छोटी Range और बड़ी Range
Range की Value देखकर हम आसानी से समझ सकते हैं कि Dataset कितना Consistent है।
Data अधिक Consistent माना जाता है।
Data में अधिक Variation मौजूद है।
उदाहरण:
Dataset A: 78, 80, 81, 82, 79
Range = 4
Dataset B: 40, 60, 80, 100, 120
Range = 80
स्पष्ट है कि Dataset B में Values अधिक फैली हुई हैं।
Range के फायदे
Range की सीमाएँ
💡 इसी कारण Advanced Analysis में केवल Range पर निर्भर नहीं रहते। Variance और Standard Deviation अधिक सटीक जानकारी देते हैं।
Range vs Mean
Mean बताता है Data का Average क्या है।
Range बताता है Data कितना फैला हुआ है।
Section Summary 🚀
Range Data Spread का सबसे सरल Measure है। यह Highest और Lowest Value के बीच का अंतर बताता है। Range Data में Variation समझने का पहला कदम है, लेकिन Detailed Analysis के लिए Variance और Standard Deviation का उपयोग किया जाता है।
अगले Section में
अब हम Variance को समझेंगे और जानेंगे कि Data Mean से कितना दूर फैला हुआ है तथा क्यों Variance Data Science और Machine Learning में इतना महत्वपूर्ण माना जाता है।
Variance क्या है?
Range हमें केवल यह बताता है कि Data की सबसे बड़ी और सबसे छोटी Value के बीच कितना अंतर है। लेकिन यह नहीं बताता कि बाकी Values Mean (Average) से कितनी दूर हैं।
यहीं पर Variance की आवश्यकता होती है। Variance Statistics का एक महत्वपूर्ण Measure है जो बताता है कि Data की Values Mean के आसपास कितनी फैली हुई हैं।
सरल शब्दों में, Variance यह मापता है कि Dataset में Consistency कितनी है और Values Average से कितनी दूर हैं।
Variance की सरल परिभाषा
Variance बताता है कि Data की Values Mean से औसतन कितनी दूर फैली हुई हैं।
Variance को एक उदाहरण से समझें
मान लीजिए दो Classes के छात्रों का Average Score समान है।
Mean = 80
Mean = 80
दोनों Classes का Mean 80 है, लेकिन दोनों Datasets एक जैसे नहीं हैं।
Class A के Marks Mean के आसपास हैं, जबकि Class B के Marks काफी दूर-दूर फैले हुए हैं।
क्या अंतर है?
Class A → Low Variance
Class B → High Variance
इसलिए केवल Mean देखकर पूरी कहानी समझना संभव नहीं है। Variance Data के Spread को गहराई से समझने में मदद करता है।
Variance हमें क्या बताता है?
Data अधिक Stable है।
Data में अधिक Variation है।
Business Example
मान लीजिए दो Sales Teams की Average Monthly Sales ₹1,00,000 है।
Low Variance
High Variance
दोनों Teams का Average समान हो सकता है, लेकिन Team A अधिक Consistent है। इसलिए Business Managers Variance का उपयोग Performance Stability को मापने के लिए करते हैं।
💡 Finance Industry में Variance का उपयोग Investment Risk मापने के लिए किया जाता है। अधिक Variance का अर्थ अधिक Risk माना जाता है।
Data Analytics में Variance का उपयोग
Machine Learning में Variance का महत्व
Machine Learning में Variance एक अत्यंत महत्वपूर्ण Concept है। यदि किसी Model का Variance बहुत अधिक है, तो Model Training Data को बहुत अच्छी तरह याद कर लेता है लेकिन नए Data पर खराब प्रदर्शन करता है।
Variance के फायदे
Variance की सीमाएँ
💡 इसी समस्या को हल करने के लिए Standard Deviation का उपयोग किया जाता है, जो Variance का Square Root होता है और समझने में अधिक आसान होता है।
Quick Understanding
Low Variance → Data Consistent है
High Variance → Data अधिक बिखरा हुआ है
Variance → Mean से दूरी को मापता है
Section Summary 🚀
Variance Data के Spread और Consistency को मापने का एक महत्वपूर्ण Statistical Measure है। यह बताता है कि Values Mean से कितनी दूर हैं। Data Analytics, Finance, Machine Learning और Risk Analysis में Variance का व्यापक उपयोग किया जाता है।
अगले Section में
अब हम Standard Deviation को समझेंगे, जो Variance का सबसे व्यावहारिक रूप है और Data Analytics Interviews में सबसे अधिक पूछे जाने वाले Topics में से एक है।
Quartiles, Percentiles और IQR क्या हैं?
अब तक हमने Mean, Median, Mode, Range, Variance और Standard Deviation जैसे Concepts को समझा। ये Measures हमें Data का Center और Spread समझने में मदद करते हैं।
लेकिन कई बार हमें यह जानना होता है कि किसी Value की Position पूरे Dataset में कहाँ है। उदाहरण के लिए किसी छात्र ने परीक्षा में 85 अंक प्राप्त किए हैं, लेकिन यह जानना अधिक उपयोगी होगा कि वह पूरी कक्षा के कितने प्रतिशत छात्रों से बेहतर प्रदर्शन कर रहा है।
यहीं पर Quartiles, Percentiles और Interquartile Range (IQR) का उपयोग किया जाता है।
इस Section में क्या सीखेंगे?
📊 Quartiles
📈 Percentiles
📏 Interquartile Range (IQR)
🎯 Outlier Detection
Quartiles क्या हैं?
Quartiles किसी Dataset को चार बराबर भागों में विभाजित करते हैं। यह हमें Data Distribution को बेहतर तरीके से समझने में मदद करते हैं।
50% Data इसके नीचे होता है।
Quartile Example
10, 20, 30, 40, 50, 60, 70, 80
इस Dataset में:
Quartiles हमें बताते हैं कि Data किस प्रकार विभिन्न हिस्सों में विभाजित है।
💡 Box Plot Visualization पूरी तरह Quartiles पर आधारित होती है।
Percentiles क्या हैं?
Percentiles Dataset को 100 बराबर भागों में विभाजित करते हैं। यह बताते हैं कि कोई Value Dataset के कितने प्रतिशत Values से बड़ी है।
आज Competitive Exams, Education Analytics, Sports Analytics और Healthcare में Percentiles का व्यापक उपयोग किया जाता है।
Percentile Example
मान लीजिए किसी परीक्षा में आपका Score 90th Percentile पर है।
इसका क्या अर्थ है?
आपने 90% छात्रों से बेहतर प्रदर्शन किया है।
केवल 10% छात्र आपसे आगे हैं।
Business Example
एक E-Commerce Company Customers को Spending के आधार पर Segment कर सकती है।
Interquartile Range (IQR) क्या है?
IQR यानी Interquartile Range Data के बीच वाले 50% भाग का Spread मापता है।
IQR Formula
IQR = Q3 − Q1
यह Measure Range की तुलना में अधिक Reliable माना जाता है क्योंकि यह Extreme Values (Outliers) से कम प्रभावित होता है।
IQR Example
Q1 = 25
Q3 = 65
IQR = 65 − 25 = 40
इसका अर्थ है कि Dataset का मध्य 50% भाग 40 Units की सीमा में फैला हुआ है।
IQR का उपयोग Outliers खोजने में
Data Analytics और Machine Learning में IQR का सबसे लोकप्रिय उपयोग Outliers पहचानने के लिए किया जाता है।
💡 Machine Learning में Data Cleaning के दौरान IQR Method सबसे लोकप्रिय Outlier Detection Techniques में से एक है।
Quartiles vs Percentiles vs IQR
Section Summary 🚀
Quartiles Data को चार भागों में विभाजित करते हैं, Percentiles Data की Relative Position बताते हैं और IQR Data के मध्य 50% भाग का Spread मापता है। Data Analytics, Machine Learning और Business Intelligence में इन Concepts का उपयोग Data Distribution समझने और Outliers पहचानने के लिए किया जाता है।
अगले Section में
अब हम Probability (प्रायिकता) की दुनिया में प्रवेश करेंगे, जो Statistics, Machine Learning और Artificial Intelligence की सबसे महत्वपूर्ण Foundation मानी जाती है।
Standard Deviation क्या है?
Statistics में केवल Average (Mean) जानना पर्याप्त नहीं होता। कई बार दो Datasets का Mean समान होता है, लेकिन उनका व्यवहार बिल्कुल अलग होता है। ऐसे में हमें यह समझना होता है कि Data Mean के आसपास कितना फैला हुआ है।
यहीं पर Standard Deviation हमारी मदद करता है। यह Statistics का सबसे महत्वपूर्ण Measure of Dispersion है, जो बताता है कि Data की Values Average से कितनी दूर हैं।
Standard Deviation की सरल परिभाषा
Standard Deviation बताता है कि Data की Values Mean (Average) के आसपास कितनी फैली हुई हैं।
Standard Deviation क्यों महत्वपूर्ण है?
मान लीजिए दो क्रिकेट खिलाड़ियों का Average Score 50 रन है। क्या इसका मतलब दोनों खिलाड़ी समान प्रदर्शन कर रहे हैं? जरूरी नहीं।
लगातार अच्छा प्रदर्शन
कभी बहुत अच्छा, कभी बहुत खराब
दोनों का Average लगभग 50 है, लेकिन Player A अधिक Consistent है। Standard Deviation इसी Consistency को मापता है।
💡 कम Standard Deviation = अधिक Consistency
💡 अधिक Standard Deviation = अधिक Variation
Standard Deviation को Visual रूप में समझें
जब Data Mean के बहुत करीब होता है, तो Standard Deviation कम होता है। जब Values Mean से दूर-दूर होती हैं, तो Standard Deviation अधिक होता है।
एक सरल उदाहरण
मान लीजिए एक कक्षा के छात्रों के अंक हैं:
75, 78, 80, 82, 85
यहाँ सभी Marks Average के आसपास हैं। इसलिए Standard Deviation कम होगा।
अब दूसरा Dataset देखें:
20, 50, 80, 110, 140
यहाँ Values काफी दूर-दूर हैं। इसलिए Standard Deviation अधिक होगा।
Low Standard Deviation vs High Standard Deviation
Data Stable और Consistent है।
Data में अधिक Variation है।
Business Example
मान लीजिए दो Sales Teams की Average Monthly Sales ₹1,00,000 है।
Low Standard Deviation
High Standard Deviation
दोनों Teams का Average समान हो सकता है, लेकिन Team A अधिक भरोसेमंद और Consistent Performance दे रही है।
Data Analytics में Standard Deviation का उपयोग
Finance में Standard Deviation
Finance और Stock Market में Standard Deviation को Risk Indicator माना जाता है।
💡 Mutual Funds और Portfolio Analysis में Standard Deviation सबसे अधिक उपयोग किए जाने वाले Risk Metrics में से एक है।
Machine Learning में Standard Deviation
Standard Deviation के फायदे
Standard Deviation की सीमाएँ
Quick Recap
Mean → Average बताता है
Variance → Spread मापता है
Standard Deviation → Data की Consistency और Stability बताता है
Section Summary 🚀
Standard Deviation Statistics का सबसे महत्वपूर्ण Measure of Dispersion है। यह बताता है कि Data Mean के आसपास कितना फैला हुआ है। कम Standard Deviation अधिक Consistency को दर्शाता है जबकि अधिक Standard Deviation Data में अधिक Variation को दर्शाता है। Data Analytics, Finance, Machine Learning और Business Intelligence में इसका व्यापक उपयोग किया जाता है।
Probability (प्रायिकता) क्या है?
अब तक हमने Descriptive Statistics के महत्वपूर्ण Concepts जैसे Mean, Median, Mode, Range, Variance और Standard Deviation को समझा। ये सभी हमें यह बताते हैं कि Data में क्या हो चुका है।
लेकिन Data Analytics, Data Science और Machine Learning में केवल Past Data को समझना पर्याप्त नहीं होता। हमें भविष्य की घटनाओं का अनुमान भी लगाना होता है।
यहीं से Probability (प्रायिकता) की शुरुआत होती है। Probability Statistics की वह शाखा है जो किसी घटना के होने की संभावना (Chance) को मापती है।
Probability की सरल परिभाषा
Probability किसी घटना के होने या न होने की संभावना को संख्यात्मक रूप में व्यक्त करती है।
सरल शब्दों में:
Probability को एक सरल उदाहरण से समझें
मान लीजिए आप एक सिक्का (Coin) उछालते हैं।
कुल संभावित परिणाम = 2
Head आने के अनुकूल परिणाम = 1
Probability of Head = 1 ÷ 2 = 0.5 = 50%
इसका अर्थ है कि Head आने की संभावना 50% है।
Probability का Formula
Probability निकालने का सबसे मूल Formula है:
Probability = Favorable Outcomes ÷ Total Outcomes
जहाँ:
Dice Example
मान लीजिए एक सामान्य Dice फेंका जाता है।
1, 2, 3, 4, 5, 6
यदि हमें 4 आने की Probability निकालनी हो:
Favorable Outcomes = 1
Total Outcomes = 6
Probability = 1/6 ≈ 0.167
अर्थात 4 आने की संभावना लगभग 16.7% है।
Probability का वास्तविक जीवन में उपयोग
Machine Learning में Probability क्यों महत्वपूर्ण है?
लगभग हर Machine Learning Model Probability पर आधारित होता है। जब Gmail किसी Email को Spam बताता है, तब वह Probability का उपयोग कर रहा होता है।
Probability की मुख्य विशेषताएँ
💡 Probability के बिना आधुनिक Data Science, Machine Learning और Artificial Intelligence की कल्पना भी नहीं की जा सकती।
Section Summary 🚀
Probability किसी घटना के होने की संभावना को मापती है। इसकी Value हमेशा 0 और 1 के बीच होती है। Data Analytics, Risk Analysis, Machine Learning और Artificial Intelligence में Probability सबसे महत्वपूर्ण Foundations में से एक है।
अगले Section में
अब हम Probability के महत्वपूर्ण Concepts जैसे Experiment, Outcome, Event, Sample Space और Types of Probability को विस्तार से समझेंगे।
Probability के Basic Concepts
Probability को अच्छी तरह समझने के लिए कुछ महत्वपूर्ण Concepts को समझना जरूरी है। लगभग हर Probability Problem इन्हीं Concepts पर आधारित होती है। यदि आप Data Analytics, Statistics या Machine Learning सीखना चाहते हैं, तो Experiment, Outcome, Event और Sample Space की स्पष्ट समझ होना आवश्यक है।
इस Section में क्या सीखेंगे?
🎲 Experiment
📊 Outcome
🎯 Event
📋 Sample Space
Experiment क्या है?
Probability में Experiment वह प्रक्रिया या कार्य होता है जिसका परिणाम निश्चित नहीं होता। यानी Experiment करने से पहले हमें यह पता नहीं होता कि अंतिम परिणाम क्या होगा।
इन सभी उदाहरणों में परिणाम अनिश्चित (Uncertain) है, इसलिए इन्हें Probability Experiment कहा जाता है।
Outcome क्या है?
Experiment के बाद प्राप्त होने वाले प्रत्येक संभावित परिणाम को Outcome कहा जाता है।
उदाहरण के लिए यदि हम एक Dice फेंकते हैं, तो प्रत्येक संख्या एक Outcome होगी।
Possible Outcomes:
1, 2, 3, 4, 5, 6
यदि Dice पर 4 आता है, तो 4 उस Experiment का Outcome कहलाएगा।
Event क्या है?
Event एक या एक से अधिक Outcomes का समूह होता है। जब हम किसी विशेष परिणाम में रुचि रखते हैं, तो उसे Event कहते हैं।
मान लीजिए Dice फेंका गया और हमें केवल Even Numbers में रुचि है।
Even Number Event:
{2, 4, 6}
यहाँ Event तीन Outcomes का समूह है।
Example: Dice पर 3 आना।
Example: Even Number आना।
Sample Space क्या है?
किसी Experiment के सभी संभावित Outcomes के समूह को Sample Space कहा जाता है।
Probability Calculation का सबसे महत्वपूर्ण भाग Sample Space ही होता है।
Dice Example
S = {1, 2, 3, 4, 5, 6}
यहाँ S पूरे Sample Space को दर्शाता है।
Coin Toss Example
S = {Head, Tail}
क्योंकि Coin Toss में केवल दो ही संभावित Outcomes होते हैं।
Experiment, Outcome, Event और Sample Space को एक साथ समझें
Real World Example
मान लीजिए एक E-Commerce Website यह Predict करना चाहती है कि कोई Customer Product खरीदेगा या नहीं।
यही Concepts आगे चलकर Recommendation Systems, Fraud Detection और Machine Learning Models की Foundation बनते हैं।
💡 Probability की लगभग हर समस्या Experiment, Outcome, Event और Sample Space से शुरू होती है।
Quick Recap 🚀
Experiment → कोई अनिश्चित प्रक्रिया
Outcome → प्राप्त परिणाम
Event → Outcomes का समूह
Sample Space → सभी संभावित Outcomes
Section Summary
Probability के मूल Concepts Experiment, Outcome, Event और Sample Space हैं। इन्हें समझे बिना Probability के Advanced Topics जैसे Conditional Probability, Bayes Theorem और Probability Distributions को समझना कठिन होगा।
अगले Section में
अब हम Types of Probability को समझेंगे और जानेंगे कि Classical Probability, Empirical Probability और Subjective Probability में क्या अंतर होता है।
Types of Probability
अब तक हमने Probability की मूल अवधारणा और उसके Basic Concepts को समझा। लेकिन वास्तविक दुनिया में Probability निकालने के कई तरीके होते हैं। हर स्थिति में Probability का Calculation एक जैसा नहीं होता।
Statistics में Probability को मुख्य रूप से तीन प्रकारों में विभाजित किया जाता है:
1. Classical Probability
Classical Probability को Theoretical Probability भी कहा जाता है। इसका उपयोग तब किया जाता है जब सभी Outcomes की संभावना समान हो।
Formula
Probability = Favorable Outcomes ÷ Total Outcomes
Coin Toss Example
एक Coin Toss में दो संभावित Outcomes होते हैं:
Head, Tail
Head आने की Probability:
P(Head) = 1/2 = 0.5 = 50%
क्योंकि दोनों Outcomes की संभावना समान है।
💡 Dice Roll, Card Games और Coin Toss Classical Probability के सबसे सामान्य उदाहरण हैं।
2. Empirical Probability
Empirical Probability को Experimental Probability भी कहा जाता है। यह वास्तविक Data और Observations पर आधारित होती है।
इसमें Probability को पिछले परिणामों के आधार पर निकाला जाता है।
Formula
Probability = Event Occurrences ÷ Total Trials
Sales Example
मान लीजिए किसी Website पर 1,000 Visitors आए।
Visitors = 1000
Purchases = 150
Purchase Probability:
P(Purchase) = 150/1000 = 0.15 = 15%
यह Probability Historical Data के आधार पर निकाली गई है।
3. Subjective Probability
Subjective Probability व्यक्तिगत अनुभव, ज्ञान और Expert Opinion पर आधारित होती है।
यह Probability Mathematical Formula से नहीं बल्कि Human Judgment से निर्धारित होती है।
Weather Forecast Example
एक मौसम विशेषज्ञ कहता है:
कल बारिश होने की संभावना 80% है।
यह Probability पिछले मौसम डेटा, विशेषज्ञ अनुभव और विभिन्न Models के आधार पर बनाई गई है।
💡 Subjective Probability पूरी तरह निश्चित नहीं होती क्योंकि यह व्यक्ति के अनुभव और निर्णय पर निर्भर करती है।
Types of Probability Comparison
Example: Coin Toss, Dice Roll
Example: Sales Analysis, Customer Data
Example: Weather Forecast
Data Science में कौन-सी Probability सबसे अधिक उपयोग होती है?
Data Analytics और Machine Learning में सबसे अधिक उपयोग Empirical Probability का होता है क्योंकि Models Historical Data पर Train किए जाते हैं।
Quick Recap 🚀
Classical Probability → Equal Chances
Empirical Probability → Historical Data
Subjective Probability → Expert Judgment
Section Summary
Probability को मुख्य रूप से Classical, Empirical और Subjective Probability में विभाजित किया जाता है। Classical Probability समान अवसरों पर आधारित होती है, Empirical Probability वास्तविक Data पर आधारित होती है और Subjective Probability Expert Opinion पर आधारित होती है। Data Science और Machine Learning में सबसे अधिक उपयोग Empirical Probability का होता है।
अगले Section में
अब हम Conditional Probability को समझेंगे और जानेंगे कि किसी घटना की Probability दूसरी घटना के होने पर कैसे बदल जाती है।
Conditional Probability क्या है?
अब तक हमने Probability के Basic Concepts और Types of Probability को समझा। लेकिन वास्तविक जीवन में कई बार किसी घटना की Probability दूसरी घटना के होने या न होने पर निर्भर करती है।
ऐसी Probability को Conditional Probability कहा जाता है। यह Probability की सबसे महत्वपूर्ण Concepts में से एक है और Bayes Theorem, Machine Learning, Artificial Intelligence तथा Risk Analysis की Foundation मानी जाती है।
Conditional Probability की सरल परिभाषा
जब किसी घटना की Probability दूसरी घटना के घटित होने की शर्त पर निकाली जाती है, तो उसे Conditional Probability कहते हैं।
एक सरल उदाहरण
मान लीजिए एक बैग में 5 Red Balls और 5 Blue Balls हैं।
कुल Balls = 10
Red Balls = 5
Blue Balls = 5
पहली Ball निकालने पर यदि Red Ball निकल चुकी है और उसे वापस नहीं रखा गया, तो अब Bag में केवल 9 Balls बची हैं।
अब दूसरी बार Red Ball आने की Probability बदल जाएगी क्योंकि Sample Space बदल चुका है।
💡 पहली घटना के होने से दूसरी घटना की Probability बदल गई। यही Conditional Probability का मूल विचार है।
Conditional Probability Formula
Conditional Probability को गणितीय रूप से इस प्रकार व्यक्त किया जाता है:
जहाँ:
Student Example
मान लीजिए किसी कॉलेज में:
कुल Students = 100
Python सीखने वाले Students = 40
Python + Statistics दोनों सीखने वाले Students = 25
यदि हमें यह Probability निकालनी हो कि कोई Student Statistics भी सीख रहा है जबकि वह Python सीख रहा है, तो:
P(Statistics | Python)
= 25 / 40
= 0.625
= 62.5%
अर्थात Python सीखने वाले Students में से 62.5% Statistics भी सीख रहे हैं।
Conditional Probability का वास्तविक जीवन में उपयोग
Machine Learning में Conditional Probability
Machine Learning के कई Algorithms Conditional Probability पर आधारित होते हैं। विशेष रूप से Classification Problems में इसका उपयोग बहुत अधिक होता है।
Independent vs Conditional Probability
Example: Coin Toss
Example: Card Drawing Without Replacement
💡 Conditional Probability को समझना Bayes Theorem सीखने के लिए आवश्यक है क्योंकि Bayes Theorem इसी Concept पर आधारित है।
Quick Recap 🚀
Conditional Probability = किसी घटना की Probability, जब दूसरी घटना पहले से घट चुकी हो।
यह वास्तविक दुनिया की अधिकांश Prediction Problems की Foundation है।
Section Summary
Conditional Probability Statistics और Machine Learning का एक महत्वपूर्ण Concept है। यह बताती है कि किसी घटना की Probability दूसरी घटना के होने पर कैसे बदलती है। Healthcare, Finance, Recommendation Systems और Spam Detection जैसे क्षेत्रों में इसका व्यापक उपयोग किया जाता है।
अगले Section में
अब हम Bayes Theorem को समझेंगे, जो Conditional Probability का सबसे शक्तिशाली अनुप्रयोग है और आधुनिक Artificial Intelligence की आधारशिला माना जाता है।
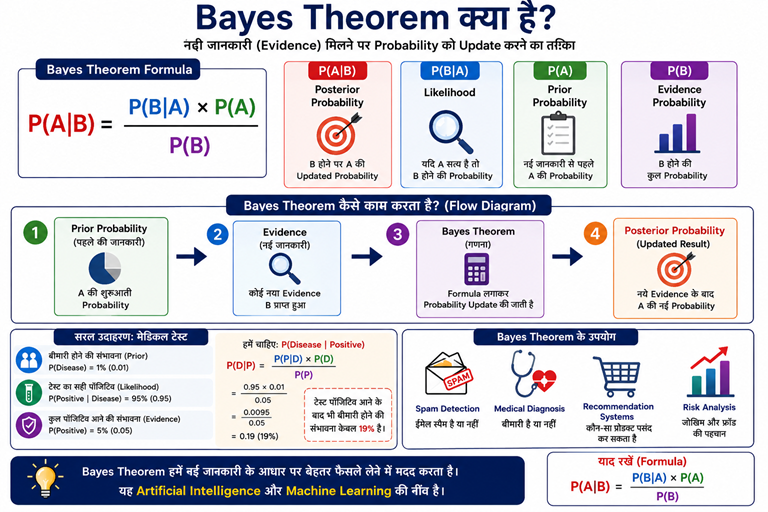
Bayes Theorem क्या है?
Conditional Probability को समझने के बाद अब हम Probability के सबसे शक्तिशाली Concepts में से एक Bayes Theorem को सीखेंगे। आधुनिक Artificial Intelligence, Machine Learning, Medical Diagnosis और Spam Detection जैसे क्षेत्रों में Bayes Theorem का व्यापक उपयोग किया जाता है।
Bayes Theorem हमें नई जानकारी मिलने पर Probability को Update करने की क्षमता देता है। दूसरे शब्दों में, यह बताता है कि किसी घटना की Probability अतिरिक्त Evidence मिलने के बाद कैसे बदलती है।
Bayes Theorem की सरल परिभाषा
जब हमें कोई नई जानकारी (Evidence) प्राप्त होती है, तो Bayes Theorem उसकी सहायता से Probability को Update करता है।
Bayes Theorem Formula
Bayes Theorem का गणितीय Formula इस प्रकार है:
जहाँ:
B होने पर A की Probability
यदि A सत्य है तो B होने की Probability
नई जानकारी से पहले A की Probability
B होने की कुल Probability
Medical Diagnosis Example
मान लीजिए एक बीमारी केवल 1% लोगों को होती है।
Disease Probability = 1%
Test Accuracy = 95%
यदि किसी व्यक्ति की Report Positive आती है, तो क्या उसे निश्चित रूप से बीमारी है?
उत्तर है — जरूरी नहीं।
Bayes Theorem इस प्रश्न का उत्तर देता है और वास्तविक Probability निकालने में मदद करता है कि व्यक्ति वास्तव में बीमार है या नहीं।
💡 Hospitals और Diagnostic Systems Bayes Theorem का उपयोग Test Results को बेहतर तरीके से Interpret करने के लिए करते हैं।
Spam Email Example
जब Gmail किसी Email को Spam या Non-Spam के रूप में वर्गीकृत करता है, तो वह केवल Keywords नहीं देखता बल्कि Probability भी Calculate करता है।
इसी सिद्धांत पर आधारित Algorithm को Naive Bayes Classifier कहा जाता है।
Bayes Theorem को एक सरल उदाहरण से समझें
मान लीजिए:
P(Disease) = 0.01
P(Positive | Disease) = 0.95
P(Positive) = 0.05
अब Bayes Theorem के अनुसार:
P(Disease | Positive) = (0.95 × 0.01) ÷ 0.05 = 0.19 = 19%
इसका अर्थ है कि Positive Test आने के बाद भी बीमारी होने की Probability केवल 19% हो सकती है।
Machine Learning में Bayes Theorem
Machine Learning में Bayes Theorem का उपयोग Classification Problems को हल करने के लिए किया जाता है।
Data Analytics में Bayes Theorem
Bayes Theorem के फायदे
💡 Bayes Theorem को Probability Theory का सबसे Practical Concept माना जाता है क्योंकि यह वास्तविक दुनिया के अनिश्चित निर्णयों में उपयोग होता है।
Quick Recap 🚀
Prior Probability → पुरानी जानकारी
Evidence → नई जानकारी
Posterior Probability → अपडेटेड Probability
Section Summary
Bayes Theorem Conditional Probability का एक शक्तिशाली विस्तार है। यह नई जानकारी मिलने पर Probability को Update करता है और AI, Machine Learning, Healthcare, Finance तथा Predictive Analytics में व्यापक रूप से उपयोग किया जाता है।
अगले Section में
अब हम Random Variable (यादृच्छिक चर) को समझेंगे, जो Probability Distribution और Statistical Modeling की नींव है।
Random Variable (यादृच्छिक चर) क्या है?
Probability में हमने Events, Outcomes और Bayes Theorem जैसे Concepts को समझा। अब हम एक ऐसे Concept पर पहुँचते हैं जो Probability Distribution, Hypothesis Testing और Machine Learning की नींव है — Random Variable।
Random Variable एक ऐसा Variable होता है जिसकी Value किसी Random Experiment के Outcome पर निर्भर करती है। दूसरे शब्दों में, इसका मान पहले से निश्चित नहीं होता बल्कि Probability के आधार पर बदल सकता है।
Random Variable की सरल परिभाषा
Random Variable वह Variable है जो किसी Random Experiment के Outcomes को Numerical Values में बदलता है।
Random Variable को सरल उदाहरण से समझें
मान लीजिए आप एक Coin Toss करते हैं।
यहाँ X एक Random Variable है क्योंकि इसका मान Coin Toss के Result पर निर्भर करता है।
Sample Space
S = {Head, Tail}
Random Variable X = {1, 0}
ध्यान दें कि Random Variable स्वयं घटना नहीं है, बल्कि घटना को Numerical Form में व्यक्त करने का तरीका है।
Dice Example
यदि एक Dice फेंका जाए तो संभावित Outcomes होंगे:
1, 2, 3, 4, 5, 6
यदि X Dice पर आने वाली संख्या को दर्शाता है, तो X एक Random Variable होगा।
Random Variable की आवश्यकता क्यों है?
Probability Theory में अधिकांश Mathematical Calculations Numbers पर आधारित होती हैं। इसलिए वास्तविक Outcomes को Numerical Values में बदलना आवश्यक होता है।
Real-World Example
मान लीजिए एक E-Commerce Website Customer Orders Track कर रही है।
अब Machine Learning Model आसानी से Probability Calculate कर सकता है कि Customer Product खरीदेगा या नहीं।
Healthcare Example
Disease Prediction Models इसी प्रकार Random Variables का उपयोग करते हैं।
💡 Machine Learning में अधिकांश Classification Problems वास्तव में Random Variables के साथ Probability Modeling ही होती हैं।
Random Variable की मुख्य विशेषताएँ
Random Variable से आगे क्या?
Random Variable को समझने के बाद अगला महत्वपूर्ण कदम यह जानना है कि विभिन्न Values किस Probability के साथ आती हैं। यही जानकारी Probability Distribution प्रदान करती है।
Quick Recap 🚀
Random Experiment → Outcome
Outcome → Numerical Value
Numerical Value → Random Variable
Section Summary
Random Variable Probability Theory का एक मूलभूत Concept है जो Random Outcomes को Numerical Values में बदलता है। Probability Distribution, Statistical Modeling, Machine Learning और Predictive Analytics सभी Random Variables पर आधारित होते हैं।
अगले Section में
अब हम Types of Random Variables को समझेंगे और जानेंगे कि Discrete Random Variable और Continuous Random Variable में क्या अंतर होता है।
Random Variable (यादृच्छिक चर) क्या है?
Probability में हमने Events, Outcomes और Bayes Theorem जैसे Concepts को समझा। अब हम एक ऐसे Concept पर पहुँचते हैं जो Probability Distribution, Hypothesis Testing और Machine Learning की नींव है — Random Variable।
Random Variable एक ऐसा Variable होता है जिसकी Value किसी Random Experiment के Outcome पर निर्भर करती है। दूसरे शब्दों में, इसका मान पहले से निश्चित नहीं होता बल्कि Probability के आधार पर बदल सकता है।
Random Variable की सरल परिभाषा
Random Variable वह Variable है जो किसी Random Experiment के Outcomes को Numerical Values में बदलता है।
Random Variable को सरल उदाहरण से समझें
मान लीजिए आप एक Coin Toss करते हैं।
यहाँ X एक Random Variable है क्योंकि इसका मान Coin Toss के Result पर निर्भर करता है।
Sample Space
S = {Head, Tail}
Random Variable X = {1, 0}
ध्यान दें कि Random Variable स्वयं घटना नहीं है, बल्कि घटना को Numerical Form में व्यक्त करने का तरीका है।
Dice Example
यदि एक Dice फेंका जाए तो संभावित Outcomes होंगे:
1, 2, 3, 4, 5, 6
यदि X Dice पर आने वाली संख्या को दर्शाता है, तो X एक Random Variable होगा।
Random Variable की आवश्यकता क्यों है?
Probability Theory में अधिकांश Mathematical Calculations Numbers पर आधारित होती हैं। इसलिए वास्तविक Outcomes को Numerical Values में बदलना आवश्यक होता है।
Real-World Example
मान लीजिए एक E-Commerce Website Customer Orders Track कर रही है।
अब Machine Learning Model आसानी से Probability Calculate कर सकता है कि Customer Product खरीदेगा या नहीं।
Healthcare Example
Disease Prediction Models इसी प्रकार Random Variables का उपयोग करते हैं।
💡 Machine Learning में अधिकांश Classification Problems वास्तव में Random Variables के साथ Probability Modeling ही होती हैं।
Random Variable की मुख्य विशेषताएँ
Random Variable से आगे क्या?
Random Variable को समझने के बाद अगला महत्वपूर्ण कदम यह जानना है कि विभिन्न Values किस Probability के साथ आती हैं। यही जानकारी Probability Distribution प्रदान करती है।
Quick Recap 🚀
Random Experiment → Outcome
Outcome → Numerical Value
Numerical Value → Random Variable
Section Summary
Random Variable Probability Theory का एक मूलभूत Concept है जो Random Outcomes को Numerical Values में बदलता है। Probability Distribution, Statistical Modeling, Machine Learning और Predictive Analytics सभी Random Variables पर आधारित होते हैं।
अगले Section में
अब हम Types of Random Variables को समझेंगे और जानेंगे कि Discrete Random Variable और Continuous Random Variable में क्या अंतर होता है।

Random Variable (यादृच्छिक चर) क्या है?
Probability में हमने Events, Outcomes और Bayes Theorem जैसे Concepts को समझा। अब हम एक ऐसे Concept पर पहुँचते हैं जो Probability Distribution, Hypothesis Testing और Machine Learning की नींव है — Random Variable।
Random Variable एक ऐसा Variable होता है जिसकी Value किसी Random Experiment के Outcome पर निर्भर करती है। दूसरे शब्दों में, इसका मान पहले से निश्चित नहीं होता बल्कि Probability के आधार पर बदल सकता है।
Random Variable की सरल परिभाषा
Random Variable वह Variable है जो किसी Random Experiment के Outcomes को Numerical Values में बदलता है।
Random Variable को सरल उदाहरण से समझें
मान लीजिए आप एक Coin Toss करते हैं।
यहाँ X एक Random Variable है क्योंकि इसका मान Coin Toss के Result पर निर्भर करता है।
Sample Space
S = {Head, Tail}
Random Variable X = {1, 0}
ध्यान दें कि Random Variable स्वयं घटना नहीं है, बल्कि घटना को Numerical Form में व्यक्त करने का तरीका है।
Dice Example
यदि एक Dice फेंका जाए तो संभावित Outcomes होंगे:
1, 2, 3, 4, 5, 6
यदि X Dice पर आने वाली संख्या को दर्शाता है, तो X एक Random Variable होगा।
Random Variable की आवश्यकता क्यों है?
Probability Theory में अधिकांश Mathematical Calculations Numbers पर आधारित होती हैं। इसलिए वास्तविक Outcomes को Numerical Values में बदलना आवश्यक होता है।
Real-World Example
मान लीजिए एक E-Commerce Website Customer Orders Track कर रही है।
अब Machine Learning Model आसानी से Probability Calculate कर सकता है कि Customer Product खरीदेगा या नहीं।
Healthcare Example
Disease Prediction Models इसी प्रकार Random Variables का उपयोग करते हैं।
💡 Machine Learning में अधिकांश Classification Problems वास्तव में Random Variables के साथ Probability Modeling ही होती हैं।
Random Variable की मुख्य विशेषताएँ
Random Variable से आगे क्या?
Random Variable को समझने के बाद अगला महत्वपूर्ण कदम यह जानना है कि विभिन्न Values किस Probability के साथ आती हैं। यही जानकारी Probability Distribution प्रदान करती है।
Quick Recap 🚀
Random Experiment → Outcome
Outcome → Numerical Value
Numerical Value → Random Variable
Section Summary
Random Variable Probability Theory का एक मूलभूत Concept है जो Random Outcomes को Numerical Values में बदलता है। Probability Distribution, Statistical Modeling, Machine Learning और Predictive Analytics सभी Random Variables पर आधारित होते हैं।
अगले Section में
अब हम Types of Random Variables को समझेंगे और जानेंगे कि Discrete Random Variable और Continuous Random Variable में क्या अंतर होता है।
Types of Random Variables
पिछले Section में हमने सीखा कि Random Variable किसी Random Experiment के Outcomes को Numerical Values में बदलता है। लेकिन सभी Random Variables एक जैसे नहीं होते।
Statistics और Probability में Random Variables को मुख्य रूप से दो प्रकारों में विभाजित किया जाता है:
क्यों महत्वपूर्ण है?
Probability Distribution, Machine Learning और Statistical Modeling में सही Random Variable Type पहचानना आवश्यक होता है।
1. Discrete Random Variable
Discrete Random Variable वह Variable होता है जिसकी Values Countable (गिनी जा सकने वाली) होती हैं।
इसमें संभावित Values सीमित (Finite) या Countably Infinite हो सकती हैं।
Simple Definition
यदि Values को एक-एक करके गिना जा सकता है, तो वह Discrete Random Variable कहलाता है।
Discrete Variable Examples
उदाहरण के लिए किसी दिन 10.5 Orders नहीं हो सकते। Orders हमेशा पूर्ण संख्या (Whole Number) में होंगे।
💡 Count किया जा सके = Discrete Random Variable
2. Continuous Random Variable
Continuous Random Variable वह Variable होता है जिसकी Value किसी Range के भीतर कोई भी हो सकती है।
इसकी Values Countable नहीं होतीं क्योंकि Decimal और Fraction Values भी संभव होती हैं।
Simple Definition
यदि Values किसी Range में अनंत (Infinite) हो सकती हैं, तो वह Continuous Random Variable कहलाता है।
Continuous Variable Examples
उदाहरण के लिए किसी व्यक्ति की Height 170 cm या 171 cm ही नहीं हो सकती, बल्कि 170.25 cm या 170.257 cm भी हो सकती है।
💡 Measure किया जाए = Continuous Random Variable
Discrete vs Continuous Random Variable
Example: Students, Orders, Cars
Example: Height, Weight, Temperature
Real-World Business Example
मान लीजिए एक E-Commerce Company Analytics कर रही है।
Machine Learning में उपयोग
Machine Learning Algorithms Data Type के अनुसार अलग-अलग Statistical Techniques का उपयोग करते हैं।
Quick Trick 🚀
Count = Discrete
Measure = Continuous
Section Summary
Random Variables दो प्रकार के होते हैं। Discrete Random Variables की Values Countable होती हैं जबकि Continuous Random Variables की Values किसी Range में अनंत हो सकती हैं। Probability Distributions और Machine Learning Models को समझने के लिए इन दोनों के बीच का अंतर जानना बहुत महत्वपूर्ण है।
अगले Section में
अब हम Probability Distribution को समझेंगे और जानेंगे कि Random Variable की प्रत्येक Value के साथ Probability कैसे जुड़ी होती है।
Probability Distribution क्या है?
पिछले Sections में हमने Random Variable और उसके Types को समझा। अब एक महत्वपूर्ण प्रश्न आता है —
यदि Random Variable कई अलग-अलग Values ले सकता है, तो प्रत्येक Value के आने की Probability क्या होगी?
इस प्रश्न का उत्तर Probability Distribution देता है।
Probability Distribution की सरल परिभाषा
Probability Distribution एक Mathematical Function है जो Random Variable की प्रत्येक संभावित Value के साथ उसकी Probability को दर्शाता है।
सरल भाषा में समझें
Probability Distribution हमें बताता है:
यानी Probability Distribution = Values + उनकी Probability
Dice Example
मान लीजिए एक Fair Dice फेंका जाता है।
Possible Values:
1, 2, 3, 4, 5, 6
क्योंकि Dice Fair है, इसलिए प्रत्येक संख्या की Probability समान होगी।
इन सभी Probabilities का समूह ही Probability Distribution कहलाता है।
Coin Toss Example
मान लीजिए:
X = Number of Heads
यदि Coin एक बार उछाला जाए:
P = 0.5
P = 0.5
यह भी एक Probability Distribution का उदाहरण है।
Probability Distribution क्यों महत्वपूर्ण है?
Probability Distribution Statistics और Data Science की सबसे महत्वपूर्ण Foundations में से एक है।
Probability Distribution के प्रकार
Random Variable के प्रकार के अनुसार Probability Distribution भी दो मुख्य प्रकार की होती है।
Example: Binomial Distribution
Example: Normal Distribution
Real World Example
मान लीजिए एक Online Store प्रतिदिन मिलने वाले Orders का Analysis कर रहा है।
20 Orders → 10%
30 Orders → 25%
40 Orders → 40%
50 Orders → 25%
यह Distribution Store Owner को यह समझने में मदद करता है कि सामान्यतः कितने Orders आने की संभावना है।
💡 Netflix, Amazon, Google और Meta जैसी कंपनियाँ User Behaviour Predict करने के लिए Probability Distributions का उपयोग करती हैं।
Machine Learning में उपयोग
Probability Distribution से आगे क्या?
सभी Probability Distributions में सबसे महत्वपूर्ण Distribution Normal Distribution है। वास्तविक दुनिया के अधिकांश Data Sets लगभग Normal Distribution को Follow करते हैं।
💡 Statistics, Hypothesis Testing, Confidence Interval और Machine Learning की कई Techniques Normal Distribution पर आधारित हैं।
Quick Recap 🚀
Random Variable → Possible Values
Probability Distribution → Values + Probability
Distribution हमें Data का व्यवहार समझने में मदद करता है।
Section Summary
Probability Distribution एक Mathematical Model है जो Random Variable की प्रत्येक संभावित Value के साथ उसकी Probability को दर्शाता है। यह Statistics, Machine Learning, Data Science और Predictive Analytics की मूल नींव है।
अगले Section में
अब हम Statistics की सबसे महत्वपूर्ण Distribution — Normal Distribution (Bell Curve) को समझेंगे, जिसे Data Science की रीढ़ माना जाता है।
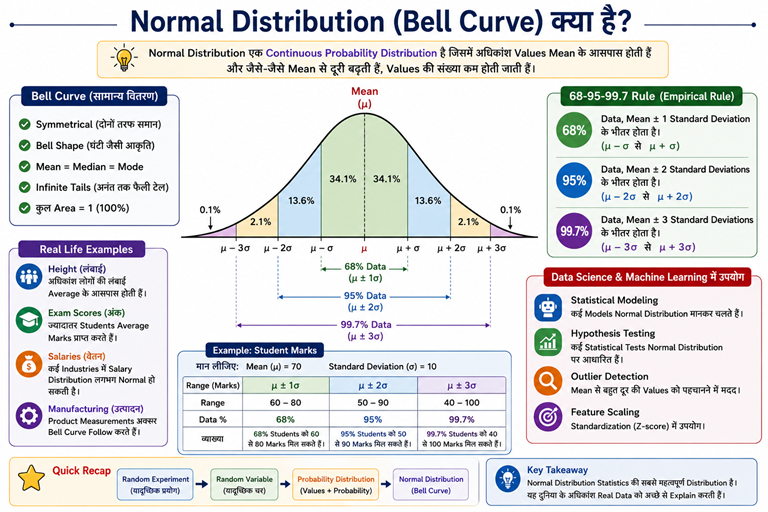
Normal Distribution (Bell Curve) क्या है?
यदि Statistics की दुनिया में केवल एक Distribution को सबसे महत्वपूर्ण कहा जाए, तो वह Normal Distribution है। Data Science, Machine Learning, Hypothesis Testing, Confidence Intervals और Statistical Modeling के अधिकांश Concepts इसी पर आधारित हैं।
Normal Distribution को अक्सर Bell Curve भी कहा जाता है क्योंकि इसका Graph घंटी (Bell) के आकार का दिखाई देता है।
Normal Distribution की सरल परिभाषा
Normal Distribution एक Continuous Probability Distribution है जिसमें अधिकांश Values Mean के आसपास होती हैं और जैसे-जैसे Mean से दूरी बढ़ती है, Values की संख्या कम होती जाती है।
Real Life में Normal Distribution
हमारे आसपास बहुत से Data Sets लगभग Normal Distribution को Follow करते हैं।
Bell Curve को समझें
Normal Distribution में Graph बीच में सबसे ऊँचा होता है क्योंकि अधिकांश Values Mean के आसपास होती हैं।
जैसे-जैसे हम Mean से दूर जाते हैं, Values की संख्या कम होती जाती है।
Bell Curve Characteristics
Center = Mean
Left Side = Lower Values
Right Side = Higher Values
Normal Distribution की मुख्य विशेषताएँ
💡 Perfect Normal Distribution में Mean, Median और Mode की Value समान होती है।
68-95-99.7 Rule
Normal Distribution की सबसे प्रसिद्ध विशेषता Empirical Rule या 68-95-99.7 Rule है।
यही कारण है कि Standard Deviation Statistics में इतना महत्वपूर्ण माना जाता है।
Student Marks Example
मान लीजिए किसी परीक्षा में:
Mean = 70
Standard Deviation = 10
Data Analytics में Normal Distribution
Machine Learning में Normal Distribution
Machine Learning के कई Algorithms यह मानकर चलते हैं कि Data लगभग Normal Distribution Follow करता है।
Normal Distribution क्यों महत्वपूर्ण है?
💡 यदि आप Statistics में केवल एक Distribution अच्छी तरह सीखते हैं, तो Normal Distribution सबसे पहले सीखनी चाहिए।
Quick Recap 🚀
Bell Curve = Normal Distribution
Mean = Median = Mode
68% – 95% – 99.7% Rule
Most Important Distribution in Statistics
Section Summary
Normal Distribution Statistics की सबसे महत्वपूर्ण Probability Distribution है। इसका Graph Bell Shape का होता है और अधिकांश वास्तविक दुनिया के Data Sets इसी Pattern को Follow करते हैं। Hypothesis Testing, Machine Learning, Data Analytics और Statistical Modeling में इसका व्यापक उपयोग किया जाता है।
अगले Section में
अब हम Binomial Distribution को समझेंगे, जो Success/Failure प्रकार की घटनाओं की Probability को Model करने के लिए उपयोग की जाती है।

Binomial Distribution क्या है?
Probability Distribution सीखते समय Normal Distribution के बाद सबसे महत्वपूर्ण Distribution Binomial Distribution होती है। यह उन परिस्थितियों में उपयोग की जाती है जहाँ किसी घटना के केवल दो संभावित परिणाम होते हैं।
Data Analytics, Machine Learning, Marketing Campaign Analysis, Quality Testing और A/B Testing में Binomial Distribution का व्यापक उपयोग किया जाता है।
Binomial Distribution की सरल परिभाषा
जब किसी Experiment के केवल दो परिणाम हों — Success या Failure — और Experiment को कई बार दोहराया जाए, तब Probability को Model करने के लिए Binomial Distribution का उपयोग किया जाता है।
दो संभावित परिणाम
Binomial Distribution केवल इन दो Outcomes पर आधारित होती है।
Coin Toss Example
मान लीजिए एक Coin को 5 बार उछाला गया।
Success = Head
Failure = Tail
अब प्रश्न यह हो सकता है:
5 Toss में Exactly 3 Heads आने की Probability क्या है?
ऐसी समस्याओं को Binomial Distribution द्वारा हल किया जाता है।
Binomial Distribution की Conditions
किसी Experiment को Binomial Distribution Follow करने के लिए चार Conditions पूरी होनी चाहिए।
💡 यदि ये चारों Conditions पूरी होती हैं, तो Binomial Distribution लागू की जा सकती है।
Real Life Example
मान लीजिए एक Marketing Campaign में Email भेजे गए हैं।
Email Open = Success
Email Not Open = Failure
अब यदि 100 Emails भेजे जाएँ, तो कितने Users Email Open करेंगे इसकी Probability Binomial Distribution द्वारा Estimate की जा सकती है।
Business Examples
Machine Learning में Binomial Distribution
Classification Problems में अक्सर केवल दो Classes होती हैं।
इसी कारण Binomial Distribution Machine Learning की Classification Problems में महत्वपूर्ण भूमिका निभाती है।
Binomial Distribution के Parameters
पूरी Distribution मुख्य रूप से n और p पर आधारित होती है।
Python में Binomial Distribution
from scipy.stats import binom
binom.pmf(3, 5, 0.5)
यह Code 5 Coin Toss में ठीक 3 Heads आने की Probability निकालता है।
Binomial Distribution कब उपयोग करें?
💡 Logistic Regression, Naive Bayes और कई Classification Algorithms अप्रत्यक्ष रूप से Binomial Concepts से जुड़े होते हैं।
Quick Recap 🚀
Two Outcomes → Success / Failure
Fixed Trials → n
Constant Probability → p
Used for Binary Events
Section Summary
Binomial Distribution एक Discrete Probability Distribution है जो Success/Failure प्रकार की घटनाओं को Model करती है। Marketing, Healthcare, Finance, Quality Control और Machine Learning की Binary Classification Problems में इसका व्यापक उपयोग किया जाता है।
अगले Section में
अब हम Uniform Distribution को समझेंगे, जहाँ सभी Outcomes की Probability समान होती है।
Uniform Distribution (समान वितरण) क्या है?
Probability Distribution के विभिन्न प्रकारों में Uniform Distribution सबसे सरल Distribution मानी जाती है। इसका मुख्य विचार बहुत आसान है — किसी निश्चित Range के भीतर सभी Values के आने की संभावना समान (Equal) होती है।
यदि किसी Random Variable की सभी संभावित Values के लिए Probability समान हो, तो उसे Uniform Distribution कहा जाता है।
Uniform Distribution की सरल परिभाषा
जब किसी निश्चित Range के भीतर हर Value के आने की संभावना बराबर हो, तब उस Distribution को Uniform Distribution कहते हैं।
एक सरल उदाहरण
मान लीजिए आप 1 से 6 तक की संख्या वाले एक Fair Dice को Roll करते हैं।
क्योंकि सभी Numbers की Probability समान है, इसलिए Dice Roll Uniform Distribution का एक अच्छा उदाहरण है।
Uniform Distribution की मुख्य विशेषताएँ
Real Life Examples
Continuous Uniform Distribution
यदि कोई Value किसी Range के भीतर किसी भी Point पर आ सकती है और सभी Points समान रूप से संभावित हों, तो उसे Continuous Uniform Distribution कहा जाता है।
Example
0 और 10 के बीच कोई भी संख्या आने की संभावना समान है।
उदाहरण के लिए:
Data Science में उपयोग
Python Example
Generate Uniform Random Numbers
import numpy as np
numbers = np.random.uniform(0,10,5)
print(numbers)
यह Code 0 और 10 के बीच 5 Random Numbers Generate करेगा जिनकी Probability समान होगी।
💡 Uniform Distribution में किसी भी Value को विशेष Advantage नहीं मिलता। सभी Values समान रूप से संभावित होती हैं।
Quick Recap 🚀
Equal Probability
Fixed Range
Rectangle Shape Graph
Used in Simulations & Random Number Generation
Section Summary
Uniform Distribution एक ऐसी Probability Distribution है जिसमें सभी Values के आने की संभावना समान होती है। Dice Roll, Random Number Generation और Simulation Models इसके सबसे सामान्य उदाहरण हैं। Data Science और Machine Learning में इसका उपयोग Random Sampling और Model Initialization के लिए किया जाता है।
अगले Section में
अब हम Poisson Distribution को समझेंगे, जिसका उपयोग Rare Events जैसे Website Errors, Call Center Calls, Traffic Accidents और Customer Arrivals को Model करने के लिए किया जाता है।
Poisson Distribution क्या है?
अब तक हमने Normal Distribution, Binomial Distribution और Uniform Distribution को समझा। लेकिन वास्तविक जीवन में कई घटनाएँ ऐसी होती हैं जो बहुत कम (Rare) होती हैं, फिर भी उनका विश्लेषण करना महत्वपूर्ण होता है।
ऐसी Rare Events की Probability को Model करने के लिए Poisson Distribution का उपयोग किया जाता है।
Poisson Distribution की सरल परिभाषा
Poisson Distribution एक Discrete Probability Distribution है जो किसी निश्चित समय, क्षेत्र या स्थान में किसी घटना के होने की संख्या को Model करती है।
Poisson Distribution को सरल उदाहरण से समझें
मान लीजिए किसी Website पर औसतन 5 Errors प्रति दिन आते हैं।
अब प्रश्न यह हो सकता है:
ऐसे प्रश्नों का उत्तर Poisson Distribution देती है।
Poisson Distribution कब उपयोग करें?
Poisson Distribution का उपयोग तब किया जाता है जब:
💡 Rare Events + Fixed Time Interval = Poisson Distribution
Real Life Examples
Poisson Distribution का मुख्य Parameter
Poisson Distribution में सबसे महत्वपूर्ण Parameter होता है:
λ (Lambda)
Average Number of Events
औसतन कितनी बार घटना होती है।
उदाहरण:
Binomial vs Poisson Distribution
Example: Email Open या Not Open
Example: प्रति दिन कितनी Calls आएंगी
Business Analytics में उपयोग
Machine Learning में उपयोग
Poisson Distribution का उपयोग Count Data Modeling में किया जाता है।
Python Example
Poisson Probability in Python
from scipy.stats import poisson
poisson.pmf(3, mu=5)
यह Code λ = 5 होने पर ठीक 3 Events होने की Probability निकालता है।
💡 Call Centers, Hospitals, Traffic Analysis और Web Analytics में Poisson Distribution सबसे अधिक उपयोग की जाने वाली Distributions में से एक है।
Quick Recap 🚀
Rare Events
Event Counts
Fixed Time Period
Average Rate = λ (Lambda)
Section Summary
Poisson Distribution एक Discrete Probability Distribution है जो किसी निश्चित समय या क्षेत्र में होने वाली Rare Events की संख्या को Model करती है। Customer Arrivals, Website Errors, Call Center Calls, Traffic Accidents और Hospital Emergencies इसके प्रमुख उपयोग हैं।
अगले Section में
अब हम Population vs Sample को समझेंगे। यह Inferential Statistics का पहला और सबसे महत्वपूर्ण Concept है, जिसके आधार पर Hypothesis Testing और Machine Learning Models विकसित किए जाते हैं।
Sampling Techniques क्या हैं?
पिछले Section में हमने Population और Sample के बारे में सीखा। लेकिन एक महत्वपूर्ण प्रश्न आता है —
यदि Population बहुत बड़ी है, तो Sample कैसे चुना जाए?
इसी प्रश्न का उत्तर Sampling Techniques देती हैं। Sampling Techniques वे तरीके हैं जिनकी सहायता से Population में से एक Representative Sample चुना जाता है।
Sampling की सरल परिभाषा
Population में से कुछ Observations चुनने की प्रक्रिया को Sampling कहते हैं।
Sampling क्यों आवश्यक है?
Sampling Techniques के प्रकार
Sampling Techniques को मुख्य रूप से दो भागों में विभाजित किया जाता है।
1. Simple Random Sampling
इस Technique में Population के प्रत्येक सदस्य के चुने जाने की संभावना समान होती है।
Example
1000 Students में से Randomly 100 Students चुनना।
💡 Lottery System Simple Random Sampling का सबसे अच्छा उदाहरण है।
2. Systematic Sampling
इस Technique में एक निश्चित अंतराल (Interval) पर Sample चुना जाता है।
Example
हर 10वें Customer को Survey में शामिल करना।
3. Stratified Sampling
जब Population अलग-अलग Groups में बंटी हो, तब प्रत्येक Group से Sample लिया जाता है।
फिर दोनों Groups से Proportion के अनुसार Sample लिया जाता है।
💡 Survey Research में Stratified Sampling सबसे अधिक उपयोग की जाती है।
4. Cluster Sampling
इस Technique में Population को Clusters में बाँटा जाता है और कुछ Clusters को Randomly चुना जाता है।
Example
पूरे राज्य के सभी Schools की जगह 20 Schools चुनकर Survey करना।
Non-Probability Sampling
इन Techniques में Selection पूरी तरह Random नहीं होता।
Business Analytics Example
मान लीजिए किसी E-Commerce Company के 1 लाख Customers हैं।
Survey Example
Population = 100,000 Customers
Sample = 2,000 Customers
यदि Sample सही तरीके से चुना गया हो, तो पूरी Customer Population के Behaviour का अनुमान लगाया जा सकता है।
Machine Learning में Sampling
💡 गलत Sampling Technique पूरे Analysis को गलत बना सकती है, चाहे आपका Model कितना भी Advanced क्यों न हो।
Quick Recap 🚀
Simple Random Sampling
Systematic Sampling
Stratified Sampling
Cluster Sampling
Section Summary
Sampling Techniques Population से Representative Sample चुनने के तरीके हैं। Simple Random, Systematic, Stratified और Cluster Sampling सबसे लोकप्रिय Probability Sampling Methods हैं। Data Analytics, Surveys और Machine Learning में सही Sampling Technique का चयन Accurate Results प्राप्त करने के लिए अत्यंत महत्वपूर्ण है।
अगले Section में
अब हम Sampling Bias को समझेंगे और जानेंगे कि गलत Sample चयन किस प्रकार पूरे Analysis को प्रभावित कर सकता है।
Sampling Bias क्या है?
पिछले Section में हमने Sampling Techniques के बारे में सीखा। लेकिन यदि Sample सही तरीके से नहीं चुना जाए, तो Analysis के परिणाम गलत हो सकते हैं। इसी समस्या को Sampling Bias कहा जाता है।
Sampling Bias Inferential Statistics की सबसे सामान्य और खतरनाक समस्याओं में से एक है क्योंकि यह पूरे Research, Survey या Machine Learning Model को गलत दिशा में ले जा सकता है।
Sampling Bias की सरल परिभाषा
जब Sample पूरी Population का सही प्रतिनिधित्व नहीं करता, तब Sampling Bias उत्पन्न होता है।
एक सरल उदाहरण
मान लीजिए आप किसी शहर के लोगों की Income का अध्ययन करना चाहते हैं।
लेकिन Survey केवल एक Luxury Mall में किया जाता है।
क्या समस्या होगी?
Survey में अधिकांश High Income लोग शामिल होंगे।
Low Income Groups शामिल नहीं होंगे।
ऐसे में Sample पूरी Population को Represent नहीं करेगा और निष्कर्ष गलत हो जाएंगे।
💡 Biased Sample = Misleading Results
Sampling Bias क्यों होता है?
Types of Sampling Bias
1. Selection Bias
जब Sample चुनने की प्रक्रिया ही पक्षपाती हो।
Example
Online Survey केवल Internet Users तक सीमित हो।
2. Undercoverage Bias
जब Population का कोई महत्वपूर्ण हिस्सा Sample में शामिल ही न हो।
Example
Student Survey में Rural Students को शामिल न करना।
3. Non-Response Bias
जब कुछ लोग Survey का उत्तर नहीं देते और केवल कुछ विशेष प्रकार के लोग Respond करते हैं।
Example
Customer Satisfaction Survey में केवल Happy Customers जवाब दें।
4. Voluntary Response Bias
जब लोग स्वयं Survey में भाग लेने का निर्णय लेते हैं।
Example
Social Media Polls
अक्सर केवल Strong Opinions वाले लोग भाग लेते हैं।
Business Example
मान लीजिए एक E-Commerce Company Customer Satisfaction Measure करना चाहती है।
यदि Survey केवल Premium Customers को भेजा जाए, तो Results पूरी Customer Population का प्रतिनिधित्व नहीं करेंगे।
Machine Learning में Sampling Bias
Machine Learning Models उतने ही अच्छे होते हैं जितना अच्छा उनका Training Data होता है।
Sampling Bias को कैसे कम करें?
💡 Garbage In, Garbage Out — यदि Sample Biased है, तो Analysis और Machine Learning Model दोनों गलत परिणाम देंगे।
Quick Recap 🚀
Biased Sample
Wrong Representation
Misleading Results
Poor Decision Making
Section Summary
Sampling Bias तब उत्पन्न होता है जब Sample पूरी Population का सही प्रतिनिधित्व नहीं करता। Selection Bias, Undercoverage Bias, Non-Response Bias और Voluntary Response Bias इसके प्रमुख प्रकार हैं। Accurate Statistical Analysis और Machine Learning Models के लिए Bias को कम करना अत्यंत आवश्यक है।
अगले Section में
अब हम Central Limit Theorem (CLT) को समझेंगे, जिसे Statistics का सबसे महत्वपूर्ण Theorem माना जाता है और जो Hypothesis Testing की नींव है।
Central Limit Theorem (CLT) क्या है?
Statistics की दुनिया में यदि किसी एक Theorem को सबसे महत्वपूर्ण कहा जाए, तो वह Central Limit Theorem (CLT) है। Hypothesis Testing, Confidence Interval, Machine Learning और Data Analytics की कई Techniques इसी सिद्धांत पर आधारित हैं।
Central Limit Theorem हमें यह समझने में मदद करता है कि Sample Data का व्यवहार कैसे होता है और हम Sample की मदद से पूरी Population के बारे में भरोसेमंद निष्कर्ष कैसे निकाल सकते हैं।
CLT की सरल परिभाषा
यदि Population कैसी भी हो, लेकिन Sample Size पर्याप्त बड़ा हो, तो Sample Means का Distribution लगभग Normal Distribution का अनुसरण करेगा।
सरल भाषा में समझें
मान लीजिए किसी Population का Data Normal नहीं है।
अब यदि हम बार-बार Random Samples लें और प्रत्येक Sample का Mean निकालें, तो उन Means का Distribution धीरे-धीरे Bell Curve (Normal Distribution) जैसा दिखने लगेगा।
💡 Population Normal हो या न हो, बड़े Sample Size पर Sample Means लगभग Normal Distribution Follow करते हैं।
CLT को उदाहरण से समझें
मान लीजिए किसी Online Store में Customer Purchase Amount का Data बहुत Uneven है।
यह Population Data Normal Distribution Follow नहीं करता।
लेकिन यदि हम 100 Customers के कई Random Samples लें और हर Sample का Mean निकालें, तो उन Means का Distribution लगभग Normal हो जाएगा।
CLT क्यों महत्वपूर्ण है?
Sample Size कितना होना चाहिए?
सामान्यतः Statistics में माना जाता है कि:
Rule of Thumb
Sample Size ≥ 30
यदि Sample Size 30 या उससे अधिक हो, तो CLT अक्सर अच्छी तरह कार्य करता है।
Population Distribution vs Sampling Distribution
CLT मुख्य रूप से Sampling Distribution के बारे में बात करता है।
Business Analytics Example
मान लीजिए एक कंपनी के 5 लाख Customers हैं।
कंपनी सभी Customers का Analysis नहीं कर सकती, इसलिए वह Random Samples का उपयोग करती है।
Business Scenario
Population = 500,000 Customers
Sample = 1,000 Customers
CLT के कारण कंपनी Sample Data के आधार पर पूरी Population के बारे में निर्णय ले सकती है।
Machine Learning में CLT
CLT के मुख्य बिंदु
💡 Central Limit Theorem के बिना Hypothesis Testing, Confidence Intervals और अधिकांश Statistical Inference संभव नहीं होती।
Quick Recap 🚀
Large Sample Size
Sample Means
Normal Distribution
Foundation of Inferential Statistics
Section Summary
Central Limit Theorem बताता है कि बड़े Sample Size पर Sample Means का Distribution लगभग Normal Distribution का अनुसरण करता है, चाहे Population Distribution कैसी भी हो। यही सिद्धांत Hypothesis Testing, Confidence Intervals और आधुनिक Data Analytics की नींव है।
अगले Section में
अब हम Hypothesis Testing क्या है? को समझेंगे, जो Inferential Statistics का सबसे महत्वपूर्ण Practical Application है।
Hypothesis Testing क्या है?
अब तक हमने Population, Sample, Sampling Techniques, Sampling Bias और Central Limit Theorem को समझा। अब हम Inferential Statistics के सबसे महत्वपूर्ण Practical Concept Hypothesis Testing पर पहुँचते हैं।
Business, Research, Data Analytics और Machine Learning में अक्सर हमें यह निर्णय लेना होता है कि कोई परिवर्तन वास्तव में प्रभावी है या केवल संयोग (Chance) से दिखाई दे रहा है।
यही निर्णय लेने में Hypothesis Testing हमारी सहायता करती है।
Hypothesis Testing की सरल परिभाषा
Hypothesis Testing एक Statistical Method है जिसका उपयोग Sample Data के आधार पर Population के बारे में निर्णय लेने के लिए किया जाता है।
Hypothesis का अर्थ क्या है?
Hypothesis का अर्थ है एक ऐसा दावा (Claim) या अनुमान जिसे हम Data की सहायता से सत्य या असत्य साबित करने का प्रयास करते हैं।
Hypothesis Testing इन दावों की Statistical Validity को जांचती है।
एक सरल उदाहरण
मान लीजिए एक Company दावा करती है कि उसकी नई Advertisement Campaign Sales बढ़ा रही है।
Business Question
क्या Sales वास्तव में बढ़ी हैं?
या यह केवल Random Variation है?
Hypothesis Testing इसी प्रश्न का उत्तर खोजती है।
Hypothesis Testing का उद्देश्य
Hypothesis Testing कैसे काम करती है?
Hypothesis Testing आमतौर पर निम्न चरणों में की जाती है:
Real World Examples
Machine Learning में Hypothesis Testing
Machine Learning Projects में Hypothesis Testing का उपयोग Models की Performance Compare करने के लिए किया जाता है।
💡 Hypothesis Testing हमें अनुमान नहीं बल्कि Statistical Evidence के आधार पर निर्णय लेने में मदद करती है।
Hypothesis Testing के मुख्य Components
अगले कुछ Sections में हम इन सभी Components को विस्तार से समझेंगे।
Quick Recap 🚀
Claim
Sample Data
Statistical Test
Decision Making
Section Summary
Hypothesis Testing एक Statistical Framework है जिसका उपयोग Sample Data की सहायता से Population के बारे में निर्णय लेने के लिए किया जाता है। Business Analytics, Data Science, Machine Learning और Scientific Research में यह सबसे महत्वपूर्ण Decision-Making Tools में से एक है।
अगले Section में
अब हम Null Hypothesis (H₀) को समझेंगे, जो Hypothesis Testing का प्रारंभिक और सबसे महत्वपूर्ण आधार है।
Null Hypothesis (H₀) क्या है?
Hypothesis Testing की शुरुआत हमेशा Null Hypothesis (H₀) से होती है। यह वह Hypothesis होती है जिसे हम प्रारंभिक रूप से सत्य (True) मानते हैं और फिर Data के आधार पर उसे जांचते हैं।
Statistics में Null Hypothesis को Default Assumption माना जाता है। जब तक हमारे पास इसके विरुद्ध पर्याप्त Evidence न हो, हम इसे सही मानते हैं।
Null Hypothesis की सरल परिभाषा
Null Hypothesis (H₀) यह मानती है कि कोई महत्वपूर्ण अंतर, प्रभाव या संबंध मौजूद नहीं है।
Null Hypothesis को सरल भाषा में समझें
जब भी कोई नया दावा किया जाता है, Statistics पहले यह मानकर चलती है कि उस दावे का कोई प्रभाव नहीं है।
फिर Sample Data की सहायता से जांच की जाती है कि क्या उस दावे को समर्थन देने के लिए पर्याप्त प्रमाण मौजूद हैं।
💡 Statistics का सिद्धांत है: “पहले संदेह करो, फिर प्रमाण मिलने पर विश्वास करो।”
Example 1: New Teaching Method
मान लीजिए एक Coaching Institute दावा करता है कि उसकी नई Teaching Method Students के Marks बढ़ा देती है।
Null Hypothesis (H₀)
नई Teaching Method का Marks पर कोई प्रभाव नहीं है।
यानी शुरुआत में हम यही मानेंगे कि नई Method और पुरानी Method में कोई अंतर नहीं है।
Example 2: Marketing Campaign
एक Company दावा करती है कि नई Marketing Campaign Sales बढ़ा रही है।
Null Hypothesis (H₀)
नई Campaign का Sales पर कोई प्रभाव नहीं है।
अब Sample Data की सहायता से इस दावे की जांच की जाएगी।
Example 3: Medicine Trial
एक नई Medicine को पुराने Treatment से बेहतर बताया जा रहा है।
Null Hypothesis (H₀)
नई Medicine और पुराने Treatment में कोई अंतर नहीं है।
Null Hypothesis की मुख्य विशेषताएँ
Hypothesis Testing में H₀ की भूमिका
Hypothesis Testing का मुख्य उद्देश्य Null Hypothesis को साबित करना नहीं होता।
बल्कि हम यह जांचते हैं कि क्या H₀ को Reject करने के लिए पर्याप्त Statistical Evidence मौजूद है।
💡 Statistics में हम Null Hypothesis को Accept नहीं करते, बल्कि Reject या Fail to Reject करते हैं।
Business Analytics Example
Machine Learning में उपयोग
Machine Learning Projects में Hypothesis Testing का उपयोग यह जांचने के लिए किया जाता है कि नया Model वास्तव में पुराने Model से बेहतर है या नहीं।
Quick Recap 🚀
H₀ = No Difference
H₀ = No Effect
H₀ = Default Assumption
Evidence मिलने पर Reject किया जाता है।
Section Summary
Null Hypothesis (H₀) Hypothesis Testing का प्रारंभिक आधार है। यह मानती है कि Population में कोई महत्वपूर्ण अंतर, प्रभाव या संबंध मौजूद नहीं है। Statistical Tests का उद्देश्य यह जांचना होता है कि क्या H₀ को Reject करने के लिए पर्याप्त Evidence मौजूद है।
अगले Section में
अब हम Alternative Hypothesis (H₁) को समझेंगे, जो Null Hypothesis का विपरीत दावा प्रस्तुत करती है।
Alternative Hypothesis (H₁) क्या है?
पिछले Section में हमने Null Hypothesis (H₀) को समझा, जो यह मानती है कि कोई अंतर, प्रभाव या संबंध मौजूद नहीं है।
लेकिन वास्तविक दुनिया में हम अक्सर यह जांचना चाहते हैं कि क्या वास्तव में कोई बदलाव हुआ है, कोई प्रभाव मौजूद है या कोई संबंध पाया जाता है। यही विचार Alternative Hypothesis (H₁) में व्यक्त किया जाता है।
Alternative Hypothesis की सरल परिभाषा
Alternative Hypothesis (H₁) यह दावा करती है कि Population में वास्तव में कोई अंतर, प्रभाव या संबंध मौजूद है।
Null और Alternative Hypothesis का संबंध
Hypothesis Testing में हमेशा दो Hypotheses होती हैं:
यदि Data पर्याप्त Evidence प्रदान करता है, तो हम H₀ को Reject करके H₁ का समर्थन करते हैं।
Example 1: Teaching Method
एक Coaching Institute दावा करता है कि उसकी नई Teaching Method Students के Marks बढ़ाती है।
Example 2: Marketing Campaign
एक Company ने नई Marketing Campaign शुरू की है।
Example 3: Medicine Trial
एक नई Medicine की Effectiveness को Test किया जा रहा है।
💡 Alternative Hypothesis आमतौर पर वही दावा होती है जिसे Researcher सिद्ध करना चाहता है।
Alternative Hypothesis के प्रकार
Alternative Hypothesis तीन प्रकार की हो सकती है।
Two-Tailed Example
Example
H₀ : Average Salary = ₹50,000
H₁ : Average Salary ≠ ₹50,000
यहाँ केवल यह जांचा जा रहा है कि Salary बदली है या नहीं।
Right-Tailed Example
Example
H₀ : Conversion Rate ≤ 10%
H₁ : Conversion Rate > 10%
यहाँ विशेष रूप से वृद्धि (Increase) की जांच की जा रही है।
Left-Tailed Example
Example
H₀ : Delivery Time ≥ 2 Days
H₁ : Delivery Time < 2 Days
यहाँ कमी (Decrease) की जांच की जा रही है।
Business Analytics Example
Machine Learning में उपयोग
Machine Learning Projects में अक्सर यह जांचा जाता है कि नया Model पुराने Model से बेहतर है या नहीं।
💡 Hypothesis Testing में हमारा अंतिम निर्णय H₀ और H₁ के बीच Statistical Evidence के आधार पर लिया जाता है।
Quick Recap 🚀
H₀ = No Difference
H₁ = Difference Exists
H₁ = Research Claim
Evidence मिलने पर H₀ Reject होती है।
Section Summary
Alternative Hypothesis (H₁) यह दावा करती है कि Population में वास्तव में कोई अंतर, प्रभाव या संबंध मौजूद है। Hypothesis Testing का उद्देश्य Sample Data के आधार पर यह निर्धारित करना होता है कि H₀ को Reject करके H₁ का समर्थन किया जा सकता है या नहीं।
अगले Section में
अब हम P-Value क्या है? को समझेंगे, जो Hypothesis Testing में Decision लेने का सबसे महत्वपूर्ण आधार है।
P-Value क्या है?
Hypothesis Testing में सबसे अधिक उपयोग होने वाला और सबसे अधिक Confusing Concept P-Value है। Null Hypothesis (H₀) और Alternative Hypothesis (H₁) बनाने के बाद हमें निर्णय लेना होता है कि H₀ को Reject करना चाहिए या नहीं।
यही निर्णय लेने में P-Value हमारी सहायता करती है।
P-Value की सरल परिभाषा
P-Value वह Probability है कि यदि Null Hypothesis (H₀) वास्तव में सही हो, तो हमें वर्तमान Data जैसा या उससे भी अधिक Extreme Result देखने को मिले।
सरल भाषा में समझें
P-Value हमें बताती है कि हमारा Result केवल संयोग (Chance) से आया है या वास्तव में कोई महत्वपूर्ण प्रभाव मौजूद है।
💡 P-Value जितनी छोटी होगी, H₀ के खिलाफ Evidence उतना मजबूत होगा।
P-Value कैसे Interpret करें?
Statistics में सामान्यतः Significance Level (α) = 0.05 उपयोग किया जाता है।
Result Statistically Significant है।
पर्याप्त Evidence नहीं है।
Example 1: Marketing Campaign
एक Company नई Marketing Campaign की Effectiveness Test कर रही है।
Hypothesis
H₀ : Campaign का कोई प्रभाव नहीं है
H₁ : Campaign प्रभावी है
Analysis के बाद:
Result
P-Value = 0.02
क्योंकि 0.02 < 0.05 है, इसलिए H₀ Reject की जाएगी।
निष्कर्ष: Campaign वास्तव में प्रभावी हो सकती है।
Example 2: New Teaching Method
Result
P-Value = 0.28
क्योंकि 0.28 > 0.05 है, इसलिए H₀ Reject नहीं की जाएगी।
निष्कर्ष: पर्याप्त Evidence नहीं है कि नई Teaching Method बेहतर है।
P-Value क्या नहीं बताती?
कई Beginners P-Value को गलत तरीके से समझते हैं।
💡 Statistical Significance और Business Significance अलग-अलग Concepts हैं।
Business Analytics Example
Machine Learning में P-Value
Machine Learning और Predictive Analytics में P-Value का उपयोग Features की Importance और Statistical Significance जांचने के लिए किया जाता है।
Quick Decision Rule
Quick Recap 🚀
Small P-Value → Strong Evidence
Large P-Value → Weak Evidence
P ≤ 0.05 → Reject H₀
P > 0.05 → Fail to Reject H₀
Section Summary
P-Value Hypothesis Testing में निर्णय लेने का सबसे महत्वपूर्ण Metric है। यह बताती है कि प्राप्त Result केवल Chance से आया है या वास्तव में कोई महत्वपूर्ण प्रभाव मौजूद है। P-Value जितनी छोटी होती है, Null Hypothesis के विरुद्ध Evidence उतना मजबूत माना जाता है।
अगले Section में
अब हम Confidence Interval (विश्वास अंतराल) को समझेंगे, जो Population Parameter के संभावित Range का अनुमान लगाने में मदद करता है।
Confidence Interval (विश्वास अंतराल) क्या है?
Hypothesis Testing में P-Value हमें यह बताती है कि कोई परिणाम Statistically Significant है या नहीं। लेकिन अक्सर हमें यह भी जानना होता है कि Population Parameter की संभावित Value किस Range में हो सकती है।
यहीं पर Confidence Interval (CI) का उपयोग किया जाता है। यह Statistics और Data Analytics में सबसे महत्वपूर्ण Concepts में से एक है।
Confidence Interval की सरल परिभाषा
Confidence Interval एक संभावित Range है जिसके भीतर वास्तविक Population Parameter होने की संभावना होती है।
सरल भाषा में समझें
मान लीजिए आपने 500 Students का Sample लिया और उनका Average Marks 70 निकला।
क्या पूरी Population का Average भी ठीक 70 होगा?
जरूरी नहीं।
Statistics हमें एक Range देती है, जैसे:
Example
68 से 72 Marks
इसी Range को Confidence Interval कहा जाता है।
💡 Confidence Interval एक Single Value नहीं बल्कि संभावित Values की Range होती है।
Confidence Level क्या होता है?
Confidence Interval हमेशा एक Confidence Level के साथ दिया जाता है।
अधिकांश Statistical Analysis में 95% Confidence Interval का उपयोग किया जाता है।
95% Confidence Interval का अर्थ
यदि हम बार-बार Sample लें और हर बार Confidence Interval निकालें, तो लगभग 95% Intervals वास्तविक Population Parameter को Cover करेंगे।
💡 95% Confidence का मतलब यह नहीं है कि Population Mean के Range में होने की Probability 95% है।
Student Marks Example
Sample Result
Sample Mean = 70
95% Confidence Interval = 68 से 72
इसका अर्थ है कि Population Mean संभवतः 68 और 72 के बीच हो सकता है।
Business Analytics Example
मान लीजिए एक E-Commerce Company Customer Satisfaction Survey करती है।
Survey Result
Average Rating = 4.2
95% CI = 4.0 से 4.4
यह Range Management को अधिक विश्वसनीय जानकारी प्रदान करती है।
Confidence Interval क्यों महत्वपूर्ण है?
Narrow vs Wide Confidence Interval
जितना Narrow Confidence Interval होगा, Estimate उतना अधिक Precise माना जाएगा।
Confidence Interval को प्रभावित करने वाले Factors
Machine Learning में उपयोग
💡 P-Value हमें Significance बताती है जबकि Confidence Interval हमें संभावित Range बताता है। दोनों को साथ में उपयोग करना सबसे अच्छा माना जाता है।
Quick Recap 🚀
Confidence Interval = Range
95% CI सबसे लोकप्रिय
Narrow CI = High Precision
Wide CI = Low Precision
Section Summary
Confidence Interval Population Parameter की संभावित Range को दर्शाता है। यह Sample Data के आधार पर अनिश्चितता को मापने और अधिक विश्वसनीय निर्णय लेने में मदद करता है। Data Analytics, Machine Learning, Business Research और Scientific Studies में इसका व्यापक उपयोग होता है।
अगले Section में
अब हम Type I Error और Type II Error को समझेंगे, जो Hypothesis Testing में होने वाली दो सबसे महत्वपूर्ण Decision Errors हैं।
Type I Error और Type II Error क्या हैं?
Hypothesis Testing में हमारा लक्ष्य सही निर्णय लेना होता है। लेकिन वास्तविक दुनिया में Data हमेशा Perfect नहीं होता। इसलिए कभी-कभी हम गलत निर्णय भी ले सकते हैं।
Statistics में ऐसे गलत निर्णयों को Type I Error और Type II Error कहा जाता है।
सरल परिभाषा
Type I Error = सही H₀ को गलती से Reject करना
Type II Error = गलत H₀ को गलती से Accept (Fail to Reject) करना
Hypothesis Testing Recap
याद रखें:
Testing के बाद हमें H₀ को Reject या Fail to Reject करना होता है।
Type I Error क्या है?
Type I Error तब होता है जब वास्तव में H₀ सही होती है, लेकिन हम उसे Reject कर देते हैं।
False Positive
कोई प्रभाव नहीं था
लेकिन हमने मान लिया कि प्रभाव मौजूद है।
Medical Example
Example
स्वस्थ व्यक्ति को बीमारी घोषित कर देना।
यह Type I Error है क्योंकि वास्तव में बीमारी नहीं थी।
💡 Type I Error = False Alarm
Business Example
Company सोचती है कि नई Marketing Campaign सफल है।
लेकिन वास्तव में Campaign का कोई प्रभाव नहीं था।
फिर भी Data देखकर H₀ Reject कर दी गई।
यह Type I Error है।
Type II Error क्या है?
Type II Error तब होता है जब वास्तव में H₀ गलत होती है, लेकिन हम उसे Reject नहीं करते।
False Negative
प्रभाव मौजूद था
लेकिन हमने मान लिया कि प्रभाव नहीं है।
Medical Example
Example
बीमार व्यक्ति को स्वस्थ घोषित कर देना।
यह Type II Error है क्योंकि बीमारी वास्तव में मौजूद थी।
💡 Type II Error = Missed Detection
Business Example
नई Marketing Campaign वास्तव में Sales बढ़ा रही थी।
लेकिन Sample Data में पर्याप्त Evidence नहीं मिला।
Company ने H₀ Reject नहीं की।
यह Type II Error है।
Type I vs Type II Error
गलत Alarm
सही Signal को Miss करना
याद रखने की आसान Trick
Alpha (α) और Type I Error
Type I Error की Probability को α (Alpha) कहते हैं।
Common Value
α = 0.05
5% Risk of Type I Error
यही कारण है कि अधिकांश Statistical Tests में 0.05 Significance Level उपयोग किया जाता है।
Beta (β) और Type II Error
Type II Error की Probability को β (Beta) कहा जाता है।
Machine Learning में उदाहरण
💡 Fraud Detection, Healthcare और Cyber Security में Type II Error अक्सर अधिक खतरनाक मानी जाती है।
Quick Recap 🚀
Type I Error = False Positive
Type II Error = False Negative
Alpha (α) = Type I Error Probability
Beta (β) = Type II Error Probability
Section Summary
Hypothesis Testing में दो प्रकार की गलतियाँ हो सकती हैं। Type I Error तब होती है जब हम सही Null Hypothesis को Reject कर देते हैं, जबकि Type II Error तब होती है जब हम गलत Null Hypothesis को Reject नहीं कर पाते। Statistical Testing का उद्देश्य इन दोनों Errors को यथासंभव कम करना होता है।
अगले Section में
अब हम Z-Test क्या है? को समझेंगे, जो Hypothesis Testing में सबसे लोकप्रिय Statistical Tests में से एक है।
Z-Test क्या है?
Hypothesis Testing में सबसे अधिक उपयोग किए जाने वाले Statistical Tests में से एक Z-Test है। इसका उपयोग यह जांचने के लिए किया जाता है कि Sample Mean और Population Mean के बीच का अंतर वास्तव में महत्वपूर्ण है या केवल Chance के कारण दिखाई दे रहा है।
Z-Test विशेष रूप से तब उपयोग किया जाता है जब Sample Size बड़ा हो और Population Standard Deviation ज्ञात हो।
Z-Test की सरल परिभाषा
Z-Test एक Statistical Test है जो यह जांचता है कि Sample Mean और Population Mean के बीच का अंतर Statistically Significant है या नहीं।
Z-Test कब उपयोग किया जाता है?
💡 यदि Population Standard Deviation ज्ञात नहीं है और Sample छोटा है, तो सामान्यतः T-Test उपयोग किया जाता है।
Z-Test का उद्देश्य
Z-Test हमें यह पता लगाने में मदद करता है कि Sample Data में दिखाई देने वाला अंतर वास्तविक है या केवल Random Variation का परिणाम है।
Student Marks Example
मान लीजिए किसी School का दावा है कि Students का Average Score 70 है।
Sample Data
Population Mean = 70
Sample Mean = 74
Sample Size = 100
अब प्रश्न यह है कि 74 और 70 का अंतर वास्तविक है या केवल Chance की वजह से दिखाई दे रहा है?
इस प्रश्न का उत्तर Z-Test देता है।
Hypothesis Setup
फिर Z-Test Calculate किया जाता है और P-Value निकाली जाती है।
Z-Score क्या होता है?
Z-Test का परिणाम Z-Score के रूप में प्राप्त होता है।
Z-Score बताता है कि Sample Mean Population Mean से कितने Standard Deviations दूर है।
Z-Test Decision Rule
Z-Test के बाद P-Value निकाली जाती है।
💡 Z-Test का अंतिम निर्णय P-Value के आधार पर लिया जाता है।
Business Analytics Example
एक Company दावा करती है कि उसकी Average Daily Sales ₹50,000 है।
100 दिनों का Sample लेने पर Average Sales ₹55,000 निकलती है।
Z-Test की सहायता से जांचा जा सकता है कि यह अंतर वास्तव में महत्वपूर्ण है या नहीं।
A/B Testing Example
Z-Test यह जांच सकता है कि Conversion Rate में दिखाई देने वाला अंतर वास्तविक है या केवल Random Variation है।
Machine Learning में उपयोग
Python Example
Z-Test Example
from statsmodels.stats.weightstats import ztest
z_stat, p_value = ztest(data)
print(p_value)
यह Code Sample Data के लिए Z-Test और P-Value निकालता है।
Quick Recap 🚀
Large Sample Size
Known Population SD
Mean Comparison
P-Value Based Decision
Section Summary
Z-Test एक Statistical Test है जिसका उपयोग Sample Mean और Population Mean के बीच अंतर की Significance जांचने के लिए किया जाता है। यह बड़े Samples और ज्ञात Population Standard Deviation की स्थिति में सबसे अधिक उपयोग किया जाता है। Business Analytics, A/B Testing और Data Science में इसका व्यापक उपयोग होता है।
अगले Section में
अब हम T-Test क्या है? को समझेंगे, जो तब उपयोग किया जाता है जब Population Standard Deviation ज्ञात न हो या Sample Size छोटा हो।
T-Test क्या है?
पिछले Section में हमने Z-Test को समझा। लेकिन वास्तविक दुनिया में अक्सर Population Standard Deviation (σ) ज्ञात नहीं होती और Sample Size भी छोटा होता है। ऐसी स्थिति में T-Test का उपयोग किया जाता है।
T-Test Hypothesis Testing का एक महत्वपूर्ण Statistical Test है जो यह जांचता है कि दो Means के बीच का अंतर वास्तव में महत्वपूर्ण है या केवल Chance की वजह से दिखाई दे रहा है।
T-Test की सरल परिभाषा
जब Population Standard Deviation ज्ञात न हो और Sample Size छोटा हो, तब Mean की तुलना करने के लिए T-Test का उपयोग किया जाता है।
T-Test कब उपयोग किया जाता है?
💡 यदि Population Standard Deviation ज्ञात है और Sample बड़ा है, तो सामान्यतः Z-Test उपयोग किया जाता है।
T-Test क्यों आवश्यक है?
छोटे Samples में Uncertainty अधिक होती है। इसलिए T-Test, Z-Test की तुलना में अधिक Conservative Approach अपनाता है।
इसी कारण T-Distribution के Tails Normal Distribution से अधिक चौड़े होते हैं।
T-Distribution क्या है?
T-Test, Normal Distribution की बजाय T-Distribution का उपयोग करता है।
T-Test के प्रकार
One Sample T-Test Example
एक College दावा करता है कि Students का Average Score 70 है।
Sample Data
Population Mean = 70
Sample Mean = 75
Sample Size = 20
T-Test की सहायता से जांचा जाएगा कि 75 और 70 का अंतर महत्वपूर्ण है या नहीं।
Independent T-Test Example
Training Program Analysis
Group A = पुरानी Training
Group B = नई Training
T-Test बताएगा कि दोनों Groups के Average Scores में वास्तविक अंतर है या नहीं।
Paired T-Test Example
Before vs After
Weight Before Diet
Weight After Diet
यह जांचने के लिए कि Diet Program वास्तव में प्रभावी था या नहीं।
Business Analytics Example
Machine Learning में उपयोग
Z-Test vs T-Test
Known Population SD
Unknown Population SD
💡 Interview में सबसे ज्यादा पूछा जाने वाला प्रश्न: “Z-Test और T-Test में क्या अंतर है?”
Python Example
T-Test Example
from scipy.stats import ttest_ind
t_stat, p_value = ttest_ind(group1, group2)
print(p_value)
यह Code दो Independent Groups के बीच T-Test करता है।
Quick Recap 🚀
Small Sample Size
Unknown Population SD
T-Distribution
Mean Comparison
Section Summary
T-Test एक Statistical Test है जिसका उपयोग छोटे Sample Size और Unknown Population Standard Deviation की स्थिति में Means की तुलना करने के लिए किया जाता है। One Sample, Independent और Paired T-Test इसके प्रमुख प्रकार हैं। Data Analytics, Machine Learning और Business Research में इसका व्यापक उपयोग होता है।
अगले Section में
अब हम Chi-Square Test क्या है? को समझेंगे, जिसका उपयोग Categorical Data के बीच संबंध (Association) की जांच करने के लिए किया जाता है।
Chi-Square Test क्या है?
अब तक हमने Z-Test और T-Test सीखे जो Numerical Data के Means की तुलना करते हैं। लेकिन कई बार Data Numbers की बजाय Categories में होता है, जैसे Gender, Education, Product Preference या Customer Type।
ऐसी स्थिति में Chi-Square Test (χ² Test) का उपयोग किया जाता है। यह Statistics में सबसे लोकप्रिय Tests में से एक है।
Chi-Square Test की सरल परिभाषा
Chi-Square Test का उपयोग यह जांचने के लिए किया जाता है कि दो Categorical Variables के बीच कोई महत्वपूर्ण संबंध (Association) है या नहीं।
Chi-Square Test कब उपयोग किया जाता है?
💡 Chi-Square Test Means की तुलना नहीं करता, बल्कि Categories के बीच संबंध जांचता है।
एक सरल उदाहरण
मान लीजिए हम यह जानना चाहते हैं कि Gender और Product Preference के बीच कोई संबंध है या नहीं।
Research Question
क्या Gender Product Choice को प्रभावित करता है?
ऐसे प्रश्नों के उत्तर के लिए Chi-Square Test उपयोग किया जाता है।
Hypothesis Setup
Example Data
Product B = 20
Product B = 60
यदि Distribution में बड़ा अंतर दिखाई देता है, तो Chi-Square Test यह बताएगा कि यह अंतर वास्तविक है या केवल Chance की वजह से है।
Chi-Square Test के प्रकार
Chi-Square Test of Independence
यह सबसे अधिक उपयोग होने वाला Chi-Square Test है।
Example
Gender ↔ Product Preference
Education ↔ Employment Status
City ↔ Brand Choice
Goodness of Fit Test
यह Test जांचता है कि Observed Data किसी Expected Distribution को Follow करता है या नहीं।
Example
क्या Dice वास्तव में Fair है?
यदि Dice Fair है, तो 1 से 6 तक सभी Numbers लगभग समान बार आने चाहिए।
Business Analytics Example
Healthcare Example
Machine Learning में उपयोग
Decision Rule
Significant Relationship है।
Relationship सिद्ध नहीं हुआ।
💡 Chi-Square Test का सबसे बड़ा उपयोग Survey Analysis और Categorical Data Analysis में होता है।
Python Example
Chi-Square Test in Python
from scipy.stats import chi2_contingency
chi2, p, dof, expected = chi2_contingency(table)
print(p)
यह Code दो Categorical Variables के बीच Association की जांच करता है।
Quick Recap 🚀
Categorical Data
Relationship Testing
Independence Analysis
P-Value Decision
Section Summary
Chi-Square Test एक Statistical Test है जिसका उपयोग Categorical Variables के बीच संबंध (Association) की जांच करने के लिए किया जाता है। Survey Research, Customer Analytics, Healthcare Studies और Machine Learning Feature Selection में इसका व्यापक उपयोग होता है।
अगले Section में
अब हम ANOVA (Analysis of Variance) को समझेंगे, जिसका उपयोग तीन या अधिक Groups के Means की तुलना करने के लिए किया जाता है।
ANOVA (Analysis of Variance) क्या है?
पिछले Sections में हमने Z-Test और T-Test सीखे। लेकिन एक महत्वपूर्ण प्रश्न आता है —
यदि हमें 3 या उससे अधिक Groups के Means की तुलना करनी हो तो क्या करेंगे?
यहीं पर ANOVA (Analysis of Variance) का उपयोग किया जाता है। ANOVA Hypothesis Testing का एक शक्तिशाली Statistical Test है जो कई Groups के Mean के बीच अंतर की जांच करता है।
ANOVA की सरल परिभाषा
ANOVA एक Statistical Test है जिसका उपयोग तीन या अधिक Groups के Means की तुलना करने के लिए किया जाता है।
ANOVA की आवश्यकता क्यों है?
मान लीजिए आपके पास तीन Training Programs हैं:
अब प्रश्न है कि क्या ये अंतर वास्तव में महत्वपूर्ण हैं या केवल Random Variation का परिणाम हैं?
ANOVA इसी प्रश्न का उत्तर देती है।
💡 T-Test केवल दो Groups की तुलना करता है जबकि ANOVA तीन या अधिक Groups की तुलना करती है।
ANOVA का Full Form
Analysis of Variance
Groups के बीच Variability का विश्लेषण
ANOVA Mean की तुलना करती है लेकिन इसका आधार Variance होता है।
Hypothesis Setup
Student Performance Example
एक School तीन अलग-अलग Teaching Methods का परीक्षण करता है।
Research Question
क्या तीनों Teaching Methods समान परिणाम देती हैं?
ANOVA यह निर्धारित करेगी कि Scores में दिखाई देने वाला अंतर महत्वपूर्ण है या नहीं।
ANOVA कैसे काम करती है?
ANOVA दो प्रकार की Variance की तुलना करती है:
यदि Between Group Variance बहुत अधिक है, तो Groups के बीच वास्तविक अंतर होने की संभावना बढ़ जाती है।
F-Statistic क्या है?
ANOVA का मुख्य Output F-Statistic होता है।
इसके बाद P-Value के आधार पर अंतिम निर्णय लिया जाता है।
Decision Rule
Business Analytics Example
Healthcare Example
ANOVA यह जांच सकती है कि कौन-सी Medicine अधिक प्रभावी है।
Machine Learning में उपयोग
Python Example
ANOVA in Python
from scipy.stats import f_oneway
f_stat, p_value = f_oneway(group1, group2, group3)
print(p_value)
यह Code तीन Groups के बीच One-Way ANOVA करता है।
💡 यदि ANOVA Significant Result देती है, तो आगे Post Hoc Tests (जैसे Tukey Test) का उपयोग करके पता लगाया जाता है कि कौन-से Groups अलग हैं।
Quick Recap 🚀
3+ Groups
Mean Comparison
F-Statistic
P-Value Based Decision
Section Summary
ANOVA (Analysis of Variance) एक Statistical Test है जिसका उपयोग तीन या अधिक Groups के Means की तुलना करने के लिए किया जाता है। यह Business Analytics, Healthcare Research, Data Science और Machine Learning में Multiple Group Comparisons के लिए व्यापक रूप से उपयोग की जाती है।
अगले Section में
अब हम Correlation क्या है? को समझेंगे और जानेंगे कि दो Variables के बीच संबंध की ताकत और दिशा कैसे मापी जाती है।
Correlation क्या है?
Statistics और Data Analytics में अक्सर हमें यह जानने की आवश्यकता होती है कि दो Variables के बीच कोई संबंध (Relationship) है या नहीं।
उदाहरण के लिए:
- क्या Study Hours बढ़ने से Marks बढ़ते हैं?
- क्या Advertising Budget बढ़ने से Sales बढ़ती है?
- क्या Temperature बढ़ने से Ice Cream Sales बढ़ती है?
ऐसे प्रश्नों का उत्तर Correlation देता है।
Correlation की सरल परिभाषा
Correlation एक Statistical Measure है जो दो Variables के बीच संबंध की दिशा (Direction) और ताकत (Strength) को मापता है।
Correlation को सरल भाषा में समझें
यदि एक Variable बदलने पर दूसरा Variable भी बदलता है, तो दोनों Variables के बीच Correlation हो सकता है।
Positive Correlation
जब एक Variable बढ़ता है और दूसरा भी बढ़ता है, तो उसे Positive Correlation कहते हैं।
सामान्यतः Study Hours और Marks के बीच Positive Correlation पाया जाता है।
Negative Correlation
जब एक Variable बढ़ता है और दूसरा घटता है, तो उसे Negative Correlation कहते हैं।
Speed और Travel Time के बीच सामान्यतः Negative Correlation होता है।
No Correlation
कुछ Variables के बीच कोई संबंध नहीं होता।
इन दोनों Variables के बीच सामान्यतः कोई Correlation नहीं होता।
Correlation Coefficient (r)
Correlation की Strength को Correlation Coefficient द्वारा मापा जाता है।
Range of Correlation
-1 ≤ r ≤ +1
Correlation Strength Guide
Business Analytics Example
यदि Correlation = 0.85 है, तो Advertising Spend और Sales के बीच Strong Positive Correlation माना जाएगा।
Data Science में उपयोग
Correlation की सीमाएँ
💡 Correlation का अर्थ Cause और Effect नहीं होता।
यदि दो Variables Correlated हैं, तो इसका अर्थ यह नहीं कि एक Variable दूसरे का कारण है।
उदाहरण:
दोनों Correlated हो सकते हैं लेकिन Ice Cream Sales Swimming Accidents का कारण नहीं हैं।
Quick Recap 🚀
Positive Correlation
Negative Correlation
No Correlation
-1 ≤ r ≤ +1
Section Summary
Correlation दो Variables के बीच संबंध की दिशा और ताकत को मापता है। Correlation Coefficient (r) -1 से +1 के बीच होता है। Data Analytics, Business Intelligence और Machine Learning में Correlation का उपयोग Variables के बीच संबंध समझने और महत्वपूर्ण Features पहचानने के लिए किया जाता है।
अगले Section में
अब हम Pearson Correlation को समझेंगे, जो Correlation को मापने की सबसे लोकप्रिय Statistical Method है।
Pearson Correlation क्या है?
Correlation के पिछले Section में हमने सीखा कि दो Variables के बीच संबंध की दिशा (Direction) और ताकत (Strength) को कैसे मापा जाता है। अब हम Correlation को मापने की सबसे लोकप्रिय और सबसे अधिक उपयोग की जाने वाली Technique Pearson Correlation को समझेंगे।
Data Analytics, Machine Learning, Statistics और Research Projects में Pearson Correlation सबसे अधिक उपयोग होने वाला Correlation Measure है।
Pearson Correlation की सरल परिभाषा
Pearson Correlation दो Numerical Variables के बीच Linear Relationship की Strength और Direction को मापता है।
Linear Relationship क्या होता है?
जब एक Variable बढ़ता है और दूसरा Variable भी लगभग एक निश्चित Pattern में बढ़ता या घटता है, तो उसे Linear Relationship कहते हैं।
यह Pearson Correlation का एक क्लासिक उदाहरण है।
Pearson Correlation Coefficient (r)
Pearson Correlation का परिणाम Correlation Coefficient (r) के रूप में प्राप्त होता है।
Range
-1 ≤ r ≤ +1
Positive Pearson Correlation
यदि एक Variable बढ़ने पर दूसरा Variable भी बढ़ता है, तो Positive Correlation होता है।
यदि r = 0.90 हो तो Strong Positive Correlation माना जाएगा।
Negative Pearson Correlation
यदि एक Variable बढ़ने पर दूसरा Variable घटता है, तो Negative Correlation होता है।
यदि r = -0.85 हो तो Strong Negative Correlation माना जाएगा।
No Correlation
यदि Variables के बीच कोई संबंध नहीं है, तो Correlation Coefficient लगभग 0 होता है।
इन दोनों Variables में सामान्यतः Pearson Correlation लगभग 0 होती है।
Correlation Strength Guide
Student Performance Example
Example Data
Study Hours ↔ Marks
r = 0.82
इसका अर्थ है कि Study Hours और Marks के बीच Strong Positive Correlation मौजूद है।
Business Analytics Example
Sales Analysis
Advertising Budget ↔ Sales
r = 0.88
यह दर्शाता है कि Marketing Spend और Sales के बीच मजबूत सकारात्मक संबंध है।
Pearson Correlation की Assumptions
💡 Pearson Correlation केवल Linear Relationship को मापती है। Non-Linear Relationship होने पर Result गलत हो सकता है।
Machine Learning में उपयोग
Python Example
Pearson Correlation in Python
from scipy.stats import pearsonr
corr, p = pearsonr(x, y)
print(corr)
यह Code दो Variables के बीच Pearson Correlation Coefficient निकालता है।
Quick Recap 🚀
Numerical Variables
Linear Relationship
-1 ≤ r ≤ +1
Most Popular Correlation Method
Section Summary
Pearson Correlation दो Numerical Variables के बीच Linear Relationship की दिशा और ताकत को मापती है। इसका Correlation Coefficient (r) -1 से +1 के बीच होता है। Data Analytics, Business Intelligence और Machine Learning में Feature Analysis तथा Relationship Discovery के लिए इसका व्यापक उपयोग किया जाता है।
अगले Section में
अब हम Spearman Correlation क्या है? को समझेंगे, जो Non-Normal Data और Ranked Data के लिए उपयोग की जाती है।
Spearman Correlation क्या है?
पिछले Section में हमने Pearson Correlation को समझा, जो दो Numerical Variables के बीच Linear Relationship को मापती है। लेकिन वास्तविक दुनिया में Data हमेशा Normal या Linear नहीं होता।
कई बार Data Ranking के रूप में होता है या Variables के बीच Relationship Linear नहीं होती। ऐसी स्थिति में Spearman Correlation का उपयोग किया जाता है।
Spearman Correlation की सरल परिभाषा
Spearman Correlation दो Variables के बीच Monotonic Relationship को मापती है और यह Data की Actual Values की बजाय Ranks का उपयोग करती है।
Ranks क्या होते हैं?
मान लीजिए 5 Students के Marks हैं:
Spearman Correlation इन Actual Marks की बजाय इन Ranks का उपयोग करती है।
Spearman Correlation कब उपयोग करें?
💡 Spearman Correlation Outliers से Pearson Correlation की तुलना में कम प्रभावित होती है।
Spearman Correlation Coefficient (ρ)
Spearman Correlation का Coefficient सामान्यतः Greek Symbol ρ (Rho) से दर्शाया जाता है।
Range
-1 ≤ ρ ≤ +1
Student Ranking Example
मान लीजिए दो Teachers ने Students की Performance Ranking दी है।
Research Question
क्या दोनों Teachers की Ranking एक जैसी है?
Spearman Correlation यह माप सकती है कि दोनों Rankings कितनी समान हैं।
Business Analytics Example
यदि Highly Rated Products अधिक बिकते हैं, तो Spearman Correlation सकारात्मक हो सकती है।
Pearson vs Spearman Correlation
Linear Relationship
Monotonic Relationship
Monotonic Relationship क्या है?
Monotonic Relationship में एक Variable बढ़ने पर दूसरा Variable लगातार बढ़ता या घटता है, लेकिन जरूरी नहीं कि Relationship Linear हो।
ऐसी परिस्थितियों में Spearman Correlation बेहतर Result देती है।
Machine Learning में उपयोग
Python Example
Spearman Correlation in Python
from scipy.stats import spearmanr
corr, p = spearmanr(x, y)
print(corr)
यह Code दो Variables के बीच Spearman Correlation Coefficient निकालता है।
💡 यदि Data Ranked हो, Outliers मौजूद हों या Relationship Linear न हो, तो Spearman Correlation अक्सर Pearson Correlation से बेहतर विकल्प होती है।
Quick Recap 🚀
Ranked Data
Monotonic Relationship
Outlier Resistant
-1 ≤ ρ ≤ +1
Section Summary
Spearman Correlation दो Variables के बीच Monotonic Relationship को मापती है और Ranks का उपयोग करती है। यह Non-Normal Data, Ranked Data और Outliers वाले Data के लिए विशेष रूप से उपयोगी है। Data Analytics और Machine Learning में Relationship Analysis के लिए इसका व्यापक उपयोग किया जाता है।
अगले Section में
अब हम Correlation vs Causation को समझेंगे और जानेंगे कि Correlation होने का अर्थ Cause-and-Effect क्यों नहीं होता।
Correlation vs Causation क्या है?
Statistics और Data Analytics सीखते समय सबसे महत्वपूर्ण Concept में से एक है:
Correlation ≠ Causation
Correlation का अर्थ Cause-and-Effect नहीं होता।
बहुत से Beginners यह गलती करते हैं कि यदि दो Variables के बीच Strong Correlation दिखाई दे, तो वे मान लेते हैं कि एक Variable दूसरे का कारण है।
लेकिन वास्तविक दुनिया में ऐसा हमेशा सही नहीं होता।
Correlation क्या बताता है?
Correlation केवल यह बताता है कि दो Variables साथ-साथ बदल रहे हैं या नहीं।
लेकिन Correlation यह नहीं बताता कि कौन किसका कारण है।
Causation क्या है?
Causation का अर्थ है कि एक Variable वास्तव में दूसरे Variable को प्रभावित कर रहा है।
यह Cause-and-Effect Relationship का उदाहरण है।
Classic Example
इन दोनों के बीच Strong Positive Correlation हो सकती है।
लेकिन क्या Ice Cream खाने से Swimming Accident होते हैं?
बिल्कुल नहीं।
दोनों के पीछे एक तीसरा Factor है:
Hidden Variable
Summer Season ☀️
Hidden Variables (Confounding Variables)
कई बार दो Variables Correlated दिखाई देते हैं क्योंकि दोनों किसी तीसरे Variable से प्रभावित होते हैं।
यही कारण है कि Correlation को सीधे Causation नहीं माना जा सकता।
💡 Correlation Relationship दिखाता है, जबकि Causation कारण बताता है।
Business Analytics Example
एक कंपनी देखती है कि Advertising Budget और Sales के बीच Correlation = 0.85 है।
क्या इसका मतलब है कि केवल Advertising ही Sales बढ़ा रही है?
जरूरी नहीं।
Sales पर अन्य Factors भी प्रभाव डाल सकते हैं:
Machine Learning Example
Machine Learning में कई Features Target Variable के साथ Highly Correlated हो सकती हैं।
लेकिन इसका अर्थ यह नहीं कि वे वास्तव में Target को Cause कर रही हैं।
Correlation कब उपयोगी है?
Causation कैसे साबित की जाती है?
Causation साबित करने के लिए केवल Correlation पर्याप्त नहीं होती।
💡 Data Scientist का काम केवल Correlation ढूँढना नहीं बल्कि यह समझना भी है कि Relationship वास्तव में Meaningful है या नहीं।
Quick Recap 🚀
Correlation = Relationship
Causation = Cause + Effect
Correlation ≠ Causation
Hidden Variables महत्वपूर्ण हैं।
Section Summary
Correlation दो Variables के बीच संबंध को दर्शाती है, जबकि Causation यह साबित करती है कि एक Variable वास्तव में दूसरे को प्रभावित कर रहा है। Data Analytics और Machine Learning में Correlation उपयोगी है, लेकिन Decision लेने से पहले Causation की जांच करना आवश्यक होता है।
अगले Section में
अब हम Linear Regression क्या है? को समझेंगे और सीखेंगे कि एक Variable की सहायता से दूसरे Variable की भविष्यवाणी (Prediction) कैसे की जाती है।
Linear Regression क्या है?
Correlation हमें यह बताती है कि दो Variables के बीच संबंध है या नहीं। लेकिन यदि हम एक Variable की सहायता से दूसरे Variable का अनुमान (Prediction) लगाना चाहते हैं, तो हमें Linear Regression की आवश्यकता होती है।
Linear Regression Data Analytics, Machine Learning और Business Forecasting में सबसे अधिक उपयोग होने वाले Algorithms में से एक है।
Linear Regression की सरल परिभाषा
Linear Regression एक Statistical Technique है जो एक Independent Variable की सहायता से Dependent Variable का अनुमान लगाती है।
सरल भाषा में समझें
मान लीजिए आप जानना चाहते हैं कि कोई Student कितने Marks प्राप्त करेगा यदि वह 8 घंटे पढ़ाई करता है।
यदि हमारे पास Study Hours और Marks का पुराना Data है, तो Linear Regression एक Mathematical Relationship बनाकर भविष्यवाणी कर सकती है।
Regression Line क्या होती है?
Linear Regression Data Points के बीच सबसे उपयुक्त सीधी रेखा (Best Fit Line) बनाती है।
यह रेखा Data के Trend को दर्शाती है और भविष्य की Values का अनुमान लगाने में मदद करती है।
Regression Equation
Y = a + bX
Equation को समझें
मान लीजिए Regression Equation है:
Example
Marks = 20 + 5 × Study Hours
यदि Student 8 घंटे पढ़ाई करता है:
Prediction
Marks = 20 + (5 × 8)
Marks = 60
इस प्रकार Regression भविष्यवाणी करने में सहायता करती है।
Independent और Dependent Variable
Business Analytics Example
Regression की सहायता से Company यह अनुमान लगा सकती है कि Advertising Budget बढ़ाने पर Sales कितनी बढ़ सकती है।
Real World Applications
Regression Line का Slope
Slope (b) बताता है कि X में 1 Unit परिवर्तन होने पर Y में कितना परिवर्तन होगा।
R² (R-Squared) क्या है?
Regression Model की Quality को मापने के लिए R² Score उपयोग किया जाता है।
जितना अधिक R² होगा, Model उतना बेहतर माना जाएगा।
💡 R² बताता है कि Dependent Variable की Variability का कितना प्रतिशत Regression Model द्वारा Explain किया जा रहा है।
Machine Learning में उपयोग
Python Example
Linear Regression in Python
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X, y)
prediction = model.predict([[8]])
यह Code Study Hours के आधार पर Marks की Prediction कर सकता है।
Quick Recap 🚀
Prediction Model
Best Fit Line
Y = a + bX
Future Forecasting
Section Summary
Linear Regression एक Statistical और Machine Learning Technique है जिसका उपयोग एक Variable की सहायता से दूसरे Variable की Prediction करने के लिए किया जाता है। Business Forecasting, Data Analytics, Machine Learning और Research में इसका व्यापक उपयोग होता है।
अगले Section में
अब हम Multiple Linear Regression क्या है? को समझेंगे, जहाँ एक नहीं बल्कि कई Independent Variables का उपयोग करके Prediction की जाती है।
Multiple Linear Regression क्या है?
पिछले Section में हमने Linear Regression सीखी, जहाँ केवल एक Independent Variable का उपयोग करके Prediction की जाती है।
लेकिन वास्तविक दुनिया में अधिकांश समस्याओं पर एक से अधिक Factors का प्रभाव पड़ता है। ऐसे मामलों में Multiple Linear Regression का उपयोग किया जाता है।
Multiple Linear Regression की सरल परिभाषा
Multiple Linear Regression एक Statistical Technique है जो कई Independent Variables की सहायता से एक Dependent Variable की Prediction करती है।
सरल उदाहरण
मान लीजिए हम किसी Student के Marks Predict करना चाहते हैं।
क्या केवल Study Hours पर्याप्त हैं?
नहीं। Marks पर कई Factors प्रभाव डाल सकते हैं।
इन सभी Factors को Model में शामिल करने के लिए Multiple Linear Regression का उपयोग किया जाता है।
Regression Equation
Multiple Regression Formula
Y = a + b₁X₁ + b₂X₂ + b₃X₃ + … + bₙXₙ
House Price Prediction Example
किसी घर की कीमत केवल Area पर निर्भर नहीं करती।
इन सभी Factors को मिलाकर House Price की अधिक Accurate Prediction की जा सकती है।
Business Analytics Example
Sales को Predict करने के लिए कई Variables उपयोग हो सकते हैं।
Multiple Regression इन सभी Variables का संयुक्त प्रभाव माप सकती है।
Regression Coefficients का अर्थ
Regression Coefficients बताते हैं कि किसी Variable में 1 Unit परिवर्तन होने पर Target Variable कितना बदलता है।
Example
Marks = 10 + 4(Study Hours) + 2(Attendance)
यहाँ:
Advantages of Multiple Regression
Multicollinearity क्या है?
यदि Independent Variables आपस में बहुत अधिक Correlated हों, तो समस्या उत्पन्न हो सकती है।
Example
Monthly Salary
Annual Salary
दोनों लगभग एक ही जानकारी देते हैं, इसलिए Model भ्रमित हो सकता है।
💡 Multiple Regression में Highly Correlated Features को हटाना अच्छा Practice माना जाता है।
R² और Adjusted R²
Multiple Regression में Adjusted R² अक्सर R² से अधिक उपयोगी माना जाता है।
Machine Learning में उपयोग
Python Example
Multiple Regression in Python
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X, y)
prediction = model.predict(new_data)
यह Code कई Independent Variables का उपयोग करके Prediction करता है।
Quick Recap 🚀
Multiple Inputs
Single Prediction
Better Accuracy
Real World Applications
Section Summary
Multiple Linear Regression एक शक्तिशाली Statistical Technique है जो कई Independent Variables की सहायता से Prediction करती है। Business Analytics, Data Science, Machine Learning और Forecasting Projects में इसका व्यापक उपयोग होता है। यह Single Variable Regression की तुलना में अधिक Accurate और Practical होती है।
अगले Section में
अब हम Statistics Libraries in Python को समझेंगे और जानेंगे कि Python में Statistical Analysis करने के लिए कौन-कौन सी Libraries उपयोग की जाती हैं।
Statistics Libraries in Python
Statistics सीखने के बाद अगला महत्वपूर्ण कदम है Python में Statistical Analysis करना। Python आज Data Analytics, Data Science, Machine Learning और Artificial Intelligence की सबसे लोकप्रिय Programming Language बन चुकी है।
Python की सबसे बड़ी ताकत इसकी Libraries हैं। Statistics के लिए Python में कई Powerful Libraries उपलब्ध हैं जो Complex Calculations को आसान बना देती हैं।
Statistics Libraries क्यों जरूरी हैं?
Manual Calculation की बजाय Fast, Accurate और Scalable Statistical Analysis करने के लिए।
Python Statistics Ecosystem
Python में Statistics और Data Analysis का पूरा Ecosystem कई Libraries पर आधारित है।
💡 Data Analyst Interview में सबसे ज्यादा पूछी जाने वाली Libraries यही चार हैं।
1. NumPy Library
NumPy (Numerical Python) Python की सबसे महत्वपूर्ण Numerical Library है।
Mean, Median, Standard Deviation, Variance जैसी Basic Statistics Calculations NumPy से की जा सकती हैं।
NumPy Example
import numpy as np
data = [10,20,30,40,50]
np.mean(data)
2. Pandas Library
Pandas Data Analysis की सबसे लोकप्रिय Library है।
CSV Files, Excel Files, SQL Data और Large Datasets के साथ काम करने के लिए Pandas उपयोग की जाती है।
Pandas Example
import pandas as pd
df[“salary”].mean()
Pandas में Summary Statistics निकालना बहुत आसान होता है।
3. SciPy Library
SciPy Python की Advanced Scientific Computing Library है।
Hypothesis Testing, Probability Distributions और Statistical Tests के लिए SciPy का उपयोग किया जाता है।
SciPy Example
from scipy.stats import ttest_ind
ttest_ind(group1, group2)
T-Test, Chi-Square Test, ANOVA और Correlation जैसी Calculations SciPy से की जाती हैं।
4. Statsmodels Library
Statsmodels एक Professional Statistical Modeling Library है।
Regression Analysis, Time Series Analysis और Statistical Modeling के लिए इसका उपयोग किया जाता है।
Statsmodels Example
import statsmodels.api as sm
model = sm.OLS(y, X)
इन Libraries का उपयोग कहाँ होता है?
Most Common Statistical Functions
Data Analyst के लिए सबसे महत्वपूर्ण Libraries
💡 यदि आप Data Analyst बनना चाहते हैं तो Pandas और NumPy से शुरुआत करें, फिर SciPy और Statsmodels सीखें।
Quick Recap 🚀
NumPy → Numerical Statistics
Pandas → Data Analysis
SciPy → Statistical Tests
Statsmodels → Regression & Modeling
Section Summary
Python में Statistical Analysis के लिए NumPy, Pandas, SciPy और Statsmodels सबसे महत्वपूर्ण Libraries हैं। ये Libraries Basic Statistics से लेकर Advanced Regression Modeling तक सभी प्रकार के Statistical Analysis को आसान बनाती हैं।
अगले Section में
अब हम NumPy for Statistics को विस्तार से सीखेंगे और Mean, Median, Mode, Variance तथा Standard Deviation को Python में Calculate करेंगे।
NumPy for Statistics in Python
Statistics सीखने के बाद अगला कदम है Python में Statistical Calculations करना। Python में Statistics के लिए सबसे पहली और सबसे महत्वपूर्ण Library NumPy (Numerical Python) है।
NumPy Fast Numerical Computation के लिए बनाई गई Library है। Mean, Median, Variance, Standard Deviation और Probability Calculations जैसे अधिकांश Statistical Operations NumPy की सहायता से किए जाते हैं।
NumPy क्या है?
NumPy Python की एक Powerful Numerical Computing Library है जो Arrays और Mathematical Operations को बहुत तेज़ बनाती है।
NumPy Install कैसे करें?
यदि NumPy आपके सिस्टम में Install नहीं है, तो Command Prompt या Terminal में निम्न Command चलाएँ:
Installation Command
pip install numpy
NumPy Import करना
NumPy को सामान्यतः np नाम से Import किया जाता है।
Import NumPy
import numpy as np
Sample Dataset बनाना
आइए एक Simple Dataset बनाते हैं जिस पर सभी Statistical Functions लागू करेंगे।
Dataset
import numpy as np
data = np.array([10,20,30,40,50])
Mean (Average) निकालना
Mean Data का Average होता है।
Mean Example
np.mean(data)
Output:
Result
30.0
Median निकालना
Median Data की Middle Value होती है।
Median Example
np.median(data)
Output:
Result
30.0
Minimum और Maximum Value
Dataset की सबसे छोटी और सबसे बड़ी Value आसानी से निकाली जा सकती है।
Range निकालना
Range = Maximum Value − Minimum Value
Range Example
np.max(data) – np.min(data)
Output:
Result
40
Variance निकालना
Variance Data की Variability को मापता है।
Variance Example
np.var(data)
Standard Deviation निकालना
Standard Deviation बताता है कि Data Mean से कितना फैला हुआ है।
Standard Deviation Example
np.std(data)
Percentile निकालना
Percentiles Data Distribution को समझने में सहायता करते हैं।
90th Percentile
np.percentile(data,90)
Quartiles निकालना
Quartiles Data को चार बराबर भागों में विभाजित करते हैं।
Quartiles Example
Q1 = np.percentile(data,25)
Q2 = np.percentile(data,50)
Q3 = np.percentile(data,75)
Correlation निकालना
NumPy दो Variables के बीच Correlation भी निकाल सकता है।
Correlation Example
x = [1,2,3,4,5]
y = [2,4,6,8,10]
np.corrcoef(x,y)
Output लगभग +1 आएगा क्योंकि दोनों Variables Perfect Positive Correlation रखते हैं।
Random Data Generate करना
Statistics सीखते समय अक्सर Dummy Data की आवश्यकता होती है।
Random Numbers
np.random.randint(1,100,50)
यह 1 से 100 के बीच 50 Random Numbers Generate करेगा।
Business Analytics Example
💡 Data Analytics Projects में लगभग हर Statistical Calculation के पीछे NumPy Library उपयोग होती है।
Quick Recap 🚀
np.mean()
np.median()
np.var()
np.std()
np.percentile()
np.corrcoef()
Section Summary
NumPy Python की सबसे महत्वपूर्ण Numerical Library है। Mean, Median, Variance, Standard Deviation, Percentiles और Correlation जैसी Statistical Calculations को NumPy की सहायता से आसानी और तेजी से किया जा सकता है। Data Analytics, Data Science और Machine Learning की नींव NumPy पर आधारित है।
अगले Section में
अब हम Pandas for Statistics सीखेंगे और जानेंगे कि वास्तविक CSV एवं Excel Data पर Statistical Analysis कैसे किया जाता है।
Pandas for Statistics in Python
NumPy Statistical Calculations के लिए बहुत उपयोगी है, लेकिन वास्तविक दुनिया में Data अक्सर CSV, Excel, SQL Database और API से आता है। ऐसे Data को Handle और Analyze करने के लिए Pandas सबसे लोकप्रिय Python Library है।
Data Analyst और Data Scientist अपने अधिकांश समय Pandas के साथ Data Cleaning, Data Exploration और Statistical Analysis में बिताते हैं।
Pandas क्या है?
Pandas Python की एक Powerful Data Analysis Library है जो Tables और Structured Data के साथ काम करने के लिए उपयोग की जाती है।
Pandas क्यों सीखें?
💡 Data Analyst Job में Pandas सबसे अधिक उपयोग होने वाली Python Library है।
Pandas Install करना
Installation Command
pip install pandas
Pandas Import करना
Import Pandas
import pandas as pd
DataFrame क्या है?
DataFrame Pandas का सबसे महत्वपूर्ण Data Structure है।
यह Excel Sheet की तरह Rows और Columns में Data Store करता है।
DataFrame Example
import pandas as pd
data = {
‘Name’:[‘Ram’,’Shyam’,’Mohan’],
‘Marks’:[75,82,90]
}
df = pd.DataFrame(data)
Mean निकालना
किसी Column का Average निकालने के लिए:
Mean Example
df[‘Marks’].mean()
Median निकालना
Median Example
df[‘Marks’].median()
Mode निकालना
Mode Example
df[‘Marks’].mode()
Maximum और Minimum Value
Variance और Standard Deviation
Variance
df[‘Marks’].var()
Standard Deviation
df[‘Marks’].std()
Summary Statistics
एक ही Command से पूरा Statistical Summary प्राप्त किया जा सकता है।
describe()
df.describe()
यह निम्न Statistics दिखाता है:
CSV File पढ़ना
Data Analyst का अधिकांश कार्य CSV Files पर होता है।
Read CSV
df = pd.read_csv(“students.csv”)
Excel File पढ़ना
Read Excel
df = pd.read_excel(“students.xlsx”)
Missing Values Analysis
Real World Data में Missing Values होना सामान्य बात है।
Check Missing Values
df.isnull().sum()
Correlation निकालना
Pandas DataFrame में Correlation Matrix आसानी से बनाई जा सकती है।
Correlation Matrix
df.corr()
Group-wise Statistics
मान लीजिए Class के अनुसार Average Marks निकालने हैं।
GroupBy Example
df.groupby(‘Class’)[‘Marks’].mean()
Business Analytics Example
💡 Excel में जो कार्य कई मिनट लेते हैं, Pandas उन्हें कुछ सेकंड में कर सकता है।
Quick Recap 🚀
DataFrame
describe()
groupby()
corr()
read_csv()
read_excel()
Section Summary
Pandas Python की सबसे लोकप्रिय Data Analysis Library है। इसकी सहायता से CSV, Excel और Database Data को Analyze किया जा सकता है। Mean, Median, Standard Deviation, Correlation, Group Analysis और Summary Statistics जैसे अधिकांश Data Analytics Tasks Pandas द्वारा किए जाते हैं।
अगले Section में
अब हम SciPy Stats Module को सीखेंगे और T-Test, Chi-Square Test, ANOVA तथा Correlation जैसी Advanced Statistical Testing करेंगे।
SciPy Stats Module in Python
NumPy और Pandas हमें Data Analysis और Basic Statistics करने में मदद करते हैं। लेकिन जब हमें Hypothesis Testing, Probability Distributions और Advanced Statistical Analysis करना होता है, तब SciPy Stats Module का उपयोग किया जाता है।
SciPy Data Science और Statistical Research में सबसे अधिक उपयोग की जाने वाली Libraries में से एक है।
SciPy Stats Module क्या है?
SciPy का stats Module Statistical Tests, Probability Distributions और Advanced Statistical Analysis करने के लिए उपयोग किया जाता है।
SciPy Install कैसे करें?
Installation Command
pip install scipy
SciPy Import करना
Import Stats Module
from scipy import stats
SciPy क्यों महत्वपूर्ण है?
💡 Data Analyst और Data Scientist Interview में SciPy अक्सर पूछा जाता है।
T-Test in SciPy
दो Groups के Mean की तुलना करने के लिए T-Test उपयोग किया जाता है।
T-Test Example
from scipy.stats import ttest_ind
t_stat, p = ttest_ind(group1, group2)
print(p)
यदि p-value 0.05 से कम हो तो दोनों Groups में Significant Difference माना जाता है।
ANOVA Test
तीन या अधिक Groups की तुलना के लिए ANOVA उपयोग किया जाता है।
ANOVA Example
from scipy.stats import f_oneway
f_stat, p = f_oneway(group1, group2, group3)
Chi-Square Test
Categorical Variables के बीच संबंध जांचने के लिए।
Chi-Square Example
from scipy.stats import chi2_contingency
chi2, p, dof, expected =
chi2_contingency(table)
Pearson Correlation
दो Numerical Variables के बीच Linear Relationship मापने के लिए।
Pearson Example
from scipy.stats import pearsonr
corr, p = pearsonr(x, y)
Spearman Correlation
Ranked या Non-Normal Data के लिए।
Spearman Example
from scipy.stats import spearmanr
corr, p = spearmanr(x, y)
Normal Distribution
SciPy Probability Distributions के साथ भी कार्य कर सकता है।
Normal Distribution Example
from scipy.stats import norm
norm.cdf(1.96)
यह Standard Normal Distribution की Cumulative Probability लौटाता है।
Random Data Generate करना
Random Normal Data
from scipy.stats import norm
data = norm.rvs(size=100)
P-Value को समझना
SciPy के अधिकांश Statistical Tests P-Value लौटाते हैं।
Business Analytics Example
Machine Learning में उपयोग
💡 SciPy Stats Module Statistics, Data Analytics और Machine Learning Projects में Advanced Statistical Analysis का मुख्य Tool है।
Quick Recap 🚀
T-Test
ANOVA
Chi-Square
Pearson Correlation
Spearman Correlation
Probability Distributions
Section Summary
SciPy Stats Module Python में Advanced Statistical Analysis के लिए सबसे महत्वपूर्ण Library है। इसकी सहायता से Hypothesis Testing, Correlation Analysis, Probability Distribution और Research-Based Statistical Calculations आसानी से की जा सकती हैं।
अगले Section में
अब हम Statsmodels Library को सीखेंगे और Regression Analysis, Statistical Modeling तथा Time Series Analysis को समझेंगे।
Statsmodels Library in Python
NumPy और Pandas हमें Data Analysis करने में मदद करते हैं तथा SciPy Statistical Tests प्रदान करता है। लेकिन जब हमें Professional Statistical Modeling, Regression Analysis और Econometrics करना होता है, तब Statsmodels Library का उपयोग किया जाता है।
Statsmodels Data Scientists, Researchers और Business Analysts के लिए एक Powerful Statistical Modeling Library है।
Statsmodels क्या है?
Statsmodels Python की एक Advanced Statistical Modeling Library है जो Regression, Hypothesis Testing और Time Series Analysis के लिए उपयोग की जाती है।
Statsmodels क्यों सीखें?
💡 Statsmodels Industry और Research दोनों में व्यापक रूप से उपयोग की जाती है।
Statsmodels Install करना
Installation Command
pip install statsmodels
Library Import करना
Import Statsmodels
import statsmodels.api as sm
Linear Regression Example
Statsmodels की सबसे लोकप्रिय Application Regression Analysis है।
Regression Model
import statsmodels.api as sm
X = sm.add_constant(X)
model = sm.OLS(y, X)
results = model.fit()
यह Ordinary Least Squares (OLS) Regression Model बनाता है।
Regression Summary
Statsmodels का सबसे बड़ा फायदा इसका Detailed Statistical Report है।
Summary Report
print(results.summary())
यह निम्न जानकारी प्रदान करता है:
R-Squared को समझें
R² बताता है कि Model Target Variable की Variability का कितना प्रतिशत Explain कर रहा है।
P-Value का उपयोग
Statsmodels प्रत्येक Feature की Statistical Significance भी बताता है।
Multiple Regression Example
House Price Prediction में कई Variables शामिल हो सकते हैं।
Statsmodels यह निर्धारित कर सकता है कि इनमें से कौन-सा Factor सबसे अधिक प्रभाव डालता है।
Time Series Analysis
Statsmodels का उपयोग Time Series Forecasting के लिए भी किया जाता है।
Business Analytics Example
Statsmodels vs Scikit-Learn
यदि आपका लक्ष्य Statistical Understanding है तो Statsmodels बेहतर विकल्प है। यदि Prediction Accuracy प्राथमिकता है तो Scikit-Learn अधिक उपयोगी है।
💡 Data Analyst के लिए Statsmodels और Data Scientist के लिए Scikit-Learn दोनों महत्वपूर्ण हैं।
Quick Recap 🚀
OLS Regression
R-Squared
P-Values
Feature Importance
Time Series Analysis
Section Summary
Statsmodels Python की Advanced Statistical Modeling Library है। इसकी सहायता से Regression Analysis, Hypothesis Testing, Time Series Forecasting और Statistical Interpretation की जा सकती है। यह Research, Data Analytics और Business Intelligence Projects में अत्यंत उपयोगी है।
अगले Section में
अब हम Histogram क्या है? को समझेंगे और सीखेंगे कि Data Distribution को Visual रूप में कैसे प्रदर्शित किया जाता है।
Histogram क्या है?
जब हमारे पास बहुत सारा Numerical Data होता है, तब केवल Numbers देखकर Data को समझना मुश्किल हो सकता है। ऐसे में Data Visualization हमारी मदद करती है।
Histogram Statistics और Data Analytics में सबसे अधिक उपयोग किए जाने वाले Charts में से एक है। यह Data Distribution को Visual रूप में दिखाता है।
Histogram की सरल परिभाषा
Histogram एक Graph है जो Data Values की Frequency Distribution को Bars के माध्यम से दर्शाता है।
Histogram को सरल भाषा में समझें
मान लीजिए किसी Class के 100 Students के Marks हैं।
हम जानना चाहते हैं:
Histogram इन सभी Groups (Bins) की Frequency दिखाता है।
Histogram के Components
Bins क्या होते हैं?
Histogram में Data को छोटे-छोटे Groups में बांटा जाता है जिन्हें Bins कहा जाता है।
Example Bins
0 – 20
21 – 40
41 – 60
61 – 80
81 – 100
हर Bin में कितनी Values हैं, Histogram वही दिखाता है।
Histogram हमें क्या बताता है?
Histogram के प्रकार
Student Marks Example
यदि Histogram में अधिकांश Students 60-80 Marks Range में दिखाई दें, तो इसका अर्थ है कि Class का प्रदर्शन अच्छा है।
Insight
Histogram देखकर Distribution को तुरंत समझा जा सकता है।
Business Analytics Example
Histogram vs Bar Chart
Continuous Values
Discrete Categories
💡 Histogram और Bar Chart देखने में समान लगते हैं लेकिन दोनों का उपयोग अलग-अलग प्रकार के Data के लिए किया जाता है।
Python Example
Histogram in Python
import matplotlib.pyplot as plt
plt.hist(data, bins=10)
plt.show()
यह Code Data Distribution का Histogram बनाता है।
Machine Learning में उपयोग
Quick Recap 🚀
Frequency Distribution
Bins
Data Spread
Distribution Shape
Outlier Detection
Section Summary
Histogram एक महत्वपूर्ण Statistical Visualization है जो Numerical Data की Frequency Distribution को दिखाता है। इसकी सहायता से Data का Shape, Spread, Center और Outliers आसानी से समझे जा सकते हैं। Data Analytics और Machine Learning में यह सबसे अधिक उपयोग किए जाने वाले Visualization Tools में से एक है।
अगले Section में
अब हम Box Plot क्या है? को समझेंगे और सीखेंगे कि Quartiles, Median तथा Outliers को Visual रूप में कैसे प्रदर्शित किया जाता है।
Box Plot क्या है?
Histogram Data Distribution दिखाने के लिए उपयोगी है, लेकिन यदि हमें Data का Spread, Median, Quartiles और Outliers एक ही Chart में देखने हों, तो Box Plot सबसे अच्छा Visualization Tool माना जाता है।
Box Plot को Box-and-Whisker Plot भी कहा जाता है। यह Descriptive Statistics को Visual रूप में प्रस्तुत करता है।
Box Plot की सरल परिभाषा
Box Plot एक Statistical Chart है जो Data के Median, Quartiles, Spread और Outliers को एक ही Visualization में दिखाता है।
Box Plot क्यों महत्वपूर्ण है?
Box Plot के Components
Box Plot कैसे पढ़ें?
Box का निचला भाग Q1 दर्शाता है और ऊपरी भाग Q3 दर्शाता है। Box के बीच की रेखा Median को दर्शाती है।
Simple Interpretation
Box = Middle 50% Data
Line = Median
Whiskers = Data Range
IQR और Box Plot
Box Plot सीधे Interquartile Range (IQR) पर आधारित होता है।
IQR Formula
IQR = Q3 – Q1
IQR जितना बड़ा होगा, Data उतना अधिक फैला हुआ होगा।
Outliers कैसे पहचानें?
Box Plot का सबसे बड़ा लाभ Outliers को पहचानना है।
💡 Outliers अक्सर Data Entry Errors, Fraud Detection या Rare Events को दर्शाते हैं।
Student Marks Example
यदि Class के अधिकांश Students के Marks 60–80 के बीच हैं लेकिन कुछ Students के Marks 10 या 100 हैं, तो Box Plot उन्हें Outliers के रूप में दिखा सकता है।
Insight
Box Plot Median और Outliers दोनों को तुरंत दिखा देता है।
Salary Analysis Example
HR Analytics में Box Plot का उपयोग Salary Distribution समझने के लिए किया जाता है।
Business Analytics Example
Histogram vs Box Plot
दोनों Charts Data Exploration में एक-दूसरे के पूरक होते हैं।
Python Example
Box Plot in Python
import matplotlib.pyplot as plt
plt.boxplot(data)
plt.show()
यह Code Dataset का Box Plot बनाता है।
Machine Learning में उपयोग
💡 Data Scientist अक्सर सबसे पहले Histogram और Box Plot बनाकर Data को समझते हैं।
Quick Recap 🚀
Median
Quartiles
IQR
Outliers
Data Spread
Section Summary
Box Plot एक Powerful Statistical Visualization है जो Median, Quartiles, IQR, Spread और Outliers को एक ही Chart में दिखाता है। Data Analytics, Business Intelligence और Machine Learning में Outlier Detection और Data Exploration के लिए इसका व्यापक उपयोग किया जाता है।
अगले Section में
अब हम Scatter Plot क्या है? को समझेंगे और सीखेंगे कि दो Variables के बीच Correlation को Visual रूप में कैसे प्रदर्शित किया जाता है।