
डेटा साइंस क्या है? Data Scientist क्या करता है (Hindi 2026)

📊 डेटा साइंस क्या है? (Data Science in Hindi 2026) 📍 आसान परिभाषा (Simple Definition) डेटा साइंस एक ऐसा क्षेत्र […]
Python Interview Questions and Answers for Data Analytics Jobs
What are the built-in types of python? Python’s built-in types are as follows: Integers Floating-point complex numbers strings booleans built-in […]
Web Scraping Made Easy with Python and BeautifulSoup Guide
In today’s data-driven world, the internet is an invaluable treasure trove of information. From news articles to product prices and […]
Power BI vs. Tableau: Choosing the Right Data Visualization

Power BI vs Tableau – Which is Better in 2025? A Beginner-Friendly Guide to Choosing the Right Data Visualization Tool […]
Step by Step Guide for Sentiment Analysis for Analytics
What is Sentiment Analysis? Sentiment analysis, also known as opinion mining, is a natural language processing (NLP) technique used to […]
Supervised vs Unsupervised Learning in Hindi with Examples [2026]
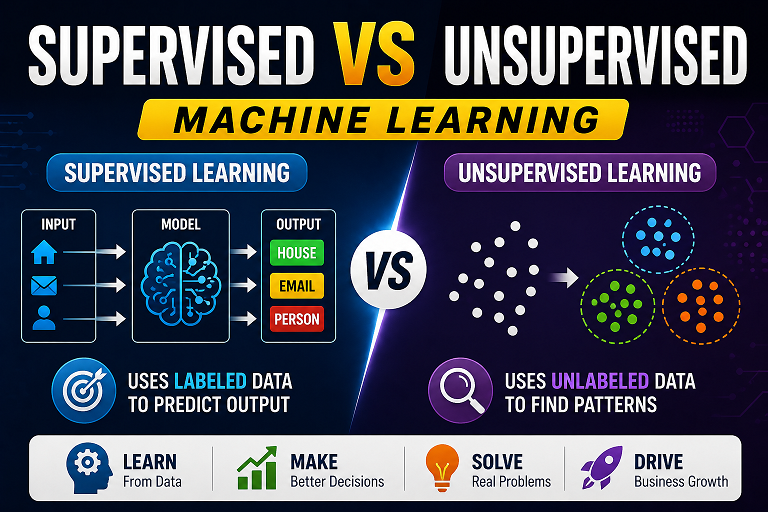
🤖 Machine Learning Basics in Hindi Supervised और Unsupervised Learning क्या है? आसान हिंदी में समझें मशीन लर्निंग (Machine Learning) […]
Exploring the Easy World of Artificial Intelligence’s Future Hindi

What is Ai in Hindi AI (कृत्रिम बुद्धिमत्ता) एक तकनीकी शब्द है जो हमें बताता है कि कंप्यूटर और मशीनें […]
Step by Step Guide to Know Machine Learning for Data Analytics
Machine learning is like teaching computers to learn from data and use that learning to make smart decisions or predictions. […]
Best Data Analytics Course in Dehradun Uttarakhand in Hindi
क्या आप अपने करियर को आगे बढ़ाने और डेटा विश्लेषण कौशलों में सुधार करने की तलाश में हैं? हमारा डेटा […]
How Data science Transforming agriculture sector in Hindi.

कैसे डेटा साइंस कृषि क्षेत्र में बदलाव ला रहा है? डेटा साइंस ने कृषि क्षेत्र में क्रांतिकारी बदलाव लाया है। […]
Comprehensive Analysis of Airline Passenger Satisfaction in python

In today’s ever-connected world, air travel serves as a vital conduit, linking people and places across the globe. Delving into […]
Data Analytics Insights Predictive Power in Excel

Student Exam Scores Student Hours Studied Exam Score John 2 75 Emily 3 85 David 1 60 Sarah 4 90 […]