
सामान्य विचलन (σ) यह बताता है कि किसी डेटा का एक सामान्य हिस्सा औसत (average) से कितना दूर है। इसका मतलब है कि यह मापता है कि डेटा की कितनी एंट्रीज़ औसत के करीब हैं या उससे कितनी दूर हैं।
सामान्य विचलन कई सांख्यिकी (statistics) में महत्वपूर्ण होता है, खासकर जब हमें यह जानना हो कि डेटा एक जगह पर इकट्ठा है या बहुत फैला हुआ है।
यहाँ 2020 तक के सभी 934 नोबेल पुरस्कार विजेताओं की उम्र का हिस्टोग्राम दिया गया है, जिसमें दिखाया गया है कि उनकी उम्र औसत से कितनी अलग है:
इस हिस्टोग्राम से आप देख सकते हैं कि ज़्यादातर नोबेल पुरस्कार विजेताओं की उम्र औसत उम्र के आस-पास है, और कितने लोग औसत से कम या ज़्यादा उम्र के हैं। अगर सामान्य विचलन कम है, तो इसका मतलब है कि ज़्यादातर लोग औसत उम्र के करीब हैं।
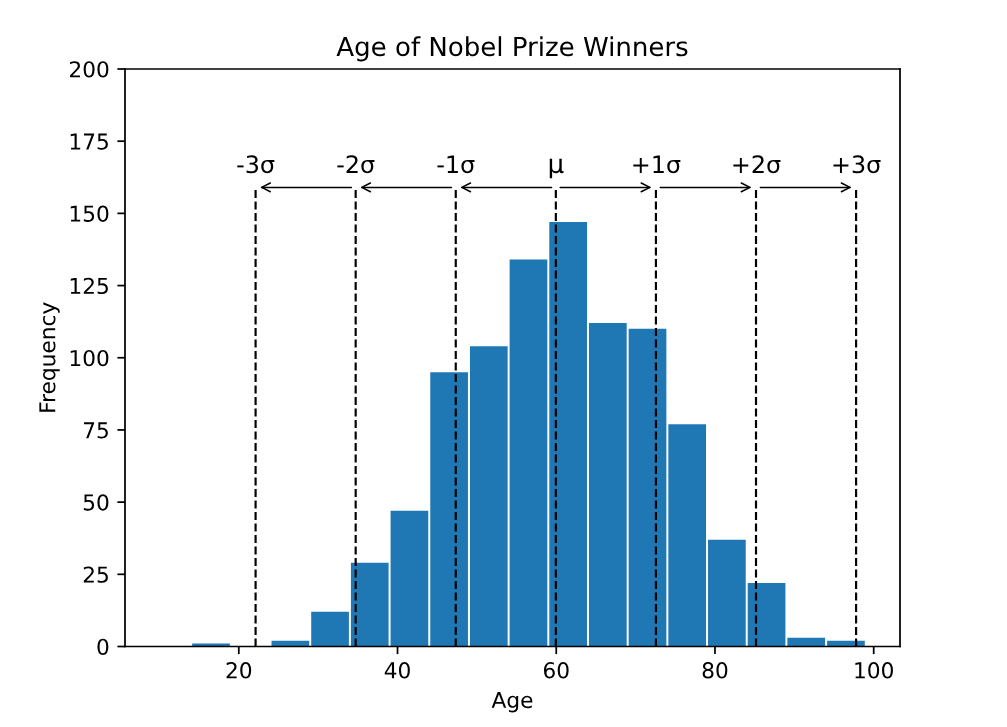
हिस्टोग्राम में हर डॉटेड लाइन एक अतिरिक्त सामान्य विचलन (standard deviation) की शिफ्ट को दिखाती है।
अगर डेटा सामान्य वितरण (normally distributed) में है, तो:
नोट: सामान्य वितरण (normal distribution) का आकार “घंटी” जैसा (bell-shaped) होता है और यह दोनों तरफ बराबर फैलता है।
σ = √(Σ(Xᵢ - μ)² / N)
नमूने के लिए सामान्य विचलन का फॉर्मूला:
s = √(Σ(Xᵢ - X̄)² / (n - 1))
उदाहरण के लिए 4 मान: 4, 11, 7, 14
μ = (4 + 11 + 7 + 14) / 4 = 9
अंतर निकालें (Differences):
4 - 9 = -5 11 - 9 = 2 7 - 9 = -2 14 - 9 = 5
स्क्वेयर (Squares):
(-5)² = 25 2² = 4 (-2)² = 4 5² = 25
जोड़ें (Sum):
25 + 4 + 4 + 25 = 58
N से विभाजित करें (Divide by N):
58 / 4 = 14.5
वर्गमूल (Square root):
√14.5 ≈ 3.81
सामान्य विचलन (Standard Deviation) कई प्रोग्रामिंग भाषाओं से आसानी से निकाला जा सकता है। बड़े डेटा सेट के लिए, हाथ से गणना करना मुश्किल हो जाता है, इसलिए सॉफ्टवेयर और प्रोग्रामिंग का उपयोग अधिक सामान्य होता है।
Python में, आप NumPy लाइब्रेरी के std() मेथड का उपयोग करके सामान्य विचलन आसानी से निकाल सकते हैं। उदाहरण के लिए, अगर आपके पास 4, 11, 7, और 14 मान (values) हैं, तो आप इसे इस तरह कर सकते हैं:
import numpy values = [4, 11, 7, 14] x = numpy.std(values) print(x)
| Symbol (सिंबल) | Description (विवरण) |
|---|
| σ | जनसंख्या का सामान्य विचलन (Population standard deviation). इसे ‘sigma’ कहते हैं। |
| s | नमूने का सामान्य विचलन (Sample standard deviation). |
| μ | जनसंख्या का औसत (Population mean). इसे ‘mu’ कहते हैं। |
| X̄ | नमूने का औसत (Sample mean). इसे ‘x-bar’ कहते हैं। |
| Σ | योग संचालक (Summation operator), इसे ‘capital sigma’ कहते हैं। |
| x | वह वैरिएबल जिसके लिए औसत निकाला जा रहा है (The variable ‘x’ for calculating average). |
| i | वैरिएबल ‘x’ का इंडेक्स, जो हर अवलोकन की पहचान करता है (The index ‘i’ of the variable ‘x’). |
| N | अवलोकनों की संख्या (Number of observations). |