
क्वारटाइल्स (Quartiles) और परसेंटाइल्स (Percentiles) विविधता (variation) के माप हैं, जो यह बताते हैं कि डेटा कितना फैलाव (spread out) है।
क्वारटाइल्स और परसेंटाइल्स दोनों ही क्वांटाइल्स (Quantiles) के प्रकार हैं।
क्वारटाइल्स वे मान (values) होते हैं जो डेटा को चार समान भागों (equal parts) में विभाजित करते हैं।
क्वारटाइल्स के तीन प्रकार होते हैं:
यहाँ 2020 तक सभी 934 नोबेल पुरस्कार (Nobel Prize) विजेताओं की उम्र का एक हिस्टोग्राम (Histogram) है, जो क्वारटाइल्स को दर्शाता है:
क्वारटाइल्स हमें डेटा के फैलाव और वितरण (distribution) को समझने में मदद करते हैं। वे यह बताते हैं कि डेटा का कितना हिस्सा किसी विशेष सीमा (threshold) के नीचे या ऊपर है।
परसेंटाइल्स वे मान होते हैं जो डेटा को 100 समान भागों (equal parts) में विभाजित करते हैं।
उदाहरण के लिए:
क्वारटाइल्स और परसेंटाइल्स डेटा के फैलाव और विविधता को समझने में महत्वपूर्ण उपकरण हैं। ये सांख्यिकी में डेटा के वितरण को स्पष्ट करते हैं और हमें बेहतर निर्णय लेने में मदद करते हैं।
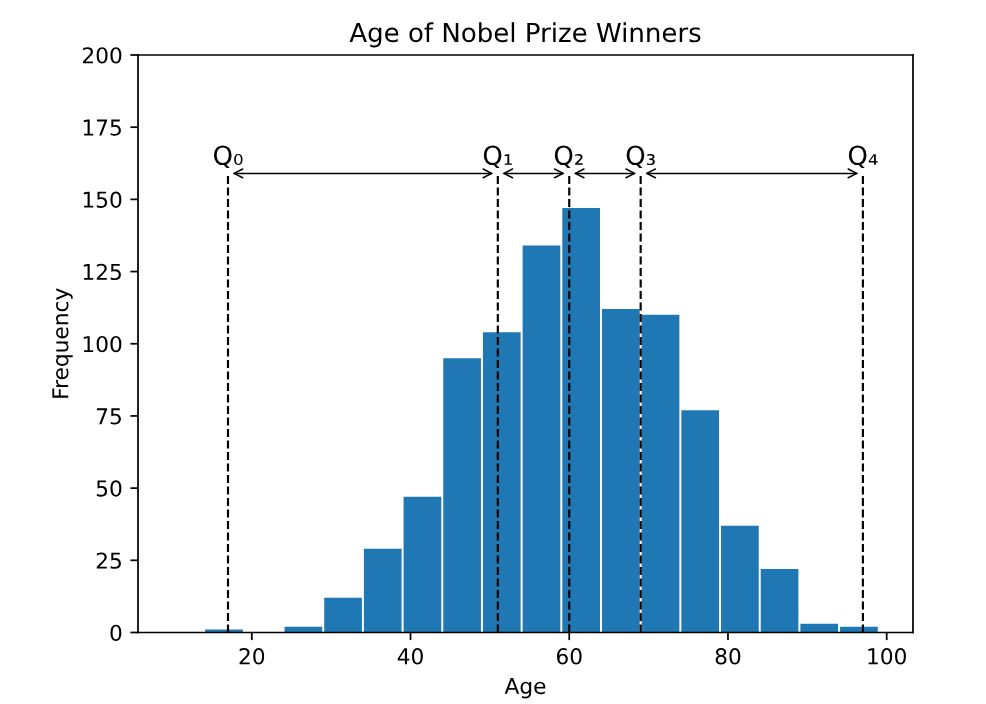
क्वारटाइल्स (Quartiles) वे मान (values) हैं जो डेटा को चार समान भागों (equal parts) में विभाजित करते हैं। इन्हें Q0, Q1, Q2, Q3, और Q4 के रूप में नामित किया जाता है।
क्वारटाइल्स डेटा के वितरण (distribution) को समझने में महत्वपूर्ण भूमिका निभाते हैं। वे यह स्पष्ट करते हैं कि डेटा किस प्रकार विभाजित है और किसी विशेष मान (value) के नीचे या ऊपर कितने डेटा पॉइंट्स हैं।
यदि आपके पास उम्र के डेटा सेट हैं, जैसे:
13, 21, 21, 40, 48, 55, 72
तो,
क्वारटाइल्स (Q0, Q1, Q2, Q3, Q4) डेटा के फैलाव और वितरण को समझने में मदद करते हैं। ये सांख्यिकी में एक महत्वपूर्ण उपकरण हैं, जो हमें डेटा के विभिन्न हिस्सों के बीच विभाजन को स्पष्ट रूप से दर्शाते हैं।
क्वारटाइल्स (Quartiles) को कई प्रोग्रामिंग भाषाओं (programming languages) में आसानी से खोजा जा सकता है। बड़े डेटा सेट्स (big data sets) के लिए सांख्यिकी की गणना (statistical calculation) करने के लिए सॉफ़्टवेयर और प्रोग्रामिंग का उपयोग अधिक सामान्य है, क्योंकि मैन्युअल रूप से गणना करना कठिन हो सकता है।
Python में, आप NumPy लाइब्रेरी का उपयोग करके क्वारटाइल्स की गणना कर सकते हैं। यहाँ एक उदाहरण है:
import numpy as np
# डेटा सेट
data = [13, 21, 21, 40, 48, 55, 72]
# क्वारटाइल्स की गणना
Q1 = np.percentile(data, 25) # 25वां परसेंटाइल (Q1)
Q2 = np.percentile(data, 50) # 50वां परसेंटाइल (Q2)
Q3 = np.percentile(data, 75) # 75वां परसेंटाइल (Q3)
print("Q1:", Q1)
print("Q2 (Median):", Q2)
print("Q3:", Q3)
परसेंटाइल्स वे मान (values) हैं जो डेटा को 100 समान भागों (equal parts) में विभाजित करते हैं।
परसेंटाइल्स को कई प्रोग्रामिंग भाषाओं में आसानी से खोजा जा सकता है। सॉफ़्टवेयर और प्रोग्रामिंग का उपयोग करके सांख्यिकी की गणना करना अधिक सामान्य है, खासकर जब आपके पास बड़े डेटा सेट्स (large data sets) हों, क्योंकि मैन्युअल रूप से गणना करना कठिन हो सकता है।
Python में, आप NumPy लाइब्रेरी का उपयोग करके परसेंटाइल्स की गणना कर सकते हैं। यहाँ 65वां परसेंटाइल (65th percentile) निकालने का एक उदाहरण है:
import numpy as np
# डेटा सेट
data = [13, 21, 21, 40, 42, 48, 55, 72]
# 65वां परसेंटाइल की गणना
P65 = np.percentile(data, 65)
print("65वां परसेंटाइल (P65):", P65)
np.percentile(data, 65) फंक्शन डेटा सेट में से 65वां परसेंटाइल निकालता है।परसेंटाइल्स डेटा के वितरण (distribution) को समझने में महत्वपूर्ण भूमिका निभाते हैं। ये आंकड़े दिखाते हैं कि किसी विशिष्ट मान के नीचे या ऊपर कितने डेटा पॉइंट्स हैं। प्रोग्रामिंग के माध्यम से परसेंटाइल्स की गणना करना एक सरल और प्रभावी तरीका है, जो आपको तेजी से और सटीक परिणाम देता है।