
t-distribution का उपयोग जनसंख्या के औसत (mean) का अनुमान लगाने और परिकल्पना परीक्षण (hypothesis testing) के लिए किया जाता है।
अनुमान में अनिश्चितता: t-distribution को औसत का अनुमान लगाने में होने वाली अतिरिक्त अनिश्चितता को ध्यान में रखते हुए समायोजित किया गया है।
छोटे नमूनों के लिए चौड़ा: अगर नमूना (sample) छोटा है, तो t-distribution चौड़ा होता है। इसका मतलब है कि छोटे नमूनों से औसत का अनुमान लगाने में ज्यादा अनिश्चितता होती है।
बड़े नमूनों के लिए संकीर्ण: यदि नमूना बड़ा है, तो t-distribution संकीर्ण हो जाता है। यह दिखाता है कि बड़े नमूनों के साथ हम जनसंख्या के औसत का अधिक सटीक अनुमान लगा सकते हैं।
सामान्य वितरण के करीब: जैसे-जैसे नमूने का आकार बढ़ता है, t-distribution सामान्य वितरण (standard normal distribution) के और करीब पहुँचता है। जब नमूना बहुत बड़ा हो जाता है, तो t-distribution लगभग सामान्य वितरण के समान हो जाता है।
नीचे कुछ विभिन्न t-distributions का ग्राफ़ है, जिसमें आप देख सकते हैं कि कैसे हर एक वितरण का आकार उसके डिग्री ऑफ़ फ़्रीडम (degrees of freedom) के अनुसार बदलता है। यह ग्राफ़ दिखाता है कि जैसे-जैसे नमूना बड़ा होता है, t-distribution संकीर्ण और अधिक स्पष्ट होता जाता है।
यह t-distribution की विशेषताएँ इसे सांख्यिकी में एक महत्वपूर्ण उपकरण बनाती हैं, जो हमें जनसंख्या के औसत का अनुमान लगाने में मदद करती हैं, खासकर जब नमूना छोटा हो।
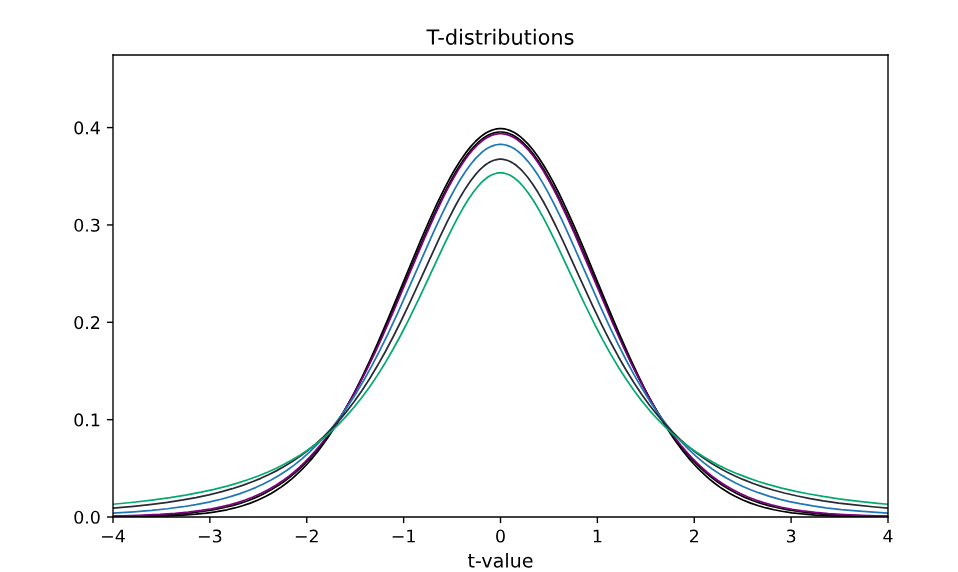
ध्यान दें कि कुछ ग्राफ़ की धारियाँ (curves) के तले बड़े होते हैं। यह छोटे sample के size से होने वाली अनिश्चितता (uncertainty) के कारण होता है।
t-distribution में, इसे ‘डिग्री ऑफ़ फ़्रीडम’ (degrees of freedom, df) के रूप में व्यक्त किया जाता है, जिसे sample size (n) से 1 घटाकर निकाला जाता है।
उदाहरण के लिए, यदि sample size 30 है, तो t-distribution के लिए degrees of freedom 29 होगा।
t-distribution का उपयोग महत्वपूर्ण t-values (critical t-values) और p-values (probabilities) खोजने के लिए किया जाता है, जो estimation और hypothesis testing के लिए जरूरी होते हैं।
नोट: t-distribution के महत्वपूर्ण t-values और p-values को खोजना सामान्य distribution (standard normal distribution) के z-values और p-values खोजने के समान है। लेकिन ध्यान रखें कि सही degrees of freedom का उपयोग करें।
t-distribution आपको डेटा के आधार पर बेहतर और सटीक निर्णय (decisions) लेने में मदद करता है, खासकर जब आपके पास छोटा sample हो।
आप t-value के p-values को एक t-table का उपयोग करके या प्रोग्रामिंग के जरिए निकाल सकते हैं।
Python में, आप Scipy Stats लाइब्रेरी के t.cdf() फ़ंक्शन का उपयोग कर सकते हैं ताकि यह पता लगाया जा सके कि 29 degrees of freedom के साथ t-value 2.1 से कम होने की संभावना (probability) क्या है।
यहाँ एक कोड का उदाहरण है:
import scipy.stats as stats # t-value और degrees of freedom के लिए p-value निकालें p_value = stats.t.cdf(2.1, 29) print(p_value)
आप p-value के t-values को एक t-table का उपयोग करके या प्रोग्रामिंग के जरिए निकाल सकते हैं।
Python में, आप Scipy Stats लाइब्रेरी के t.ppf() फ़ंक्शन का उपयोग कर सकते हैं ताकि यह पता लगाया जा सके कि 29 degrees of freedom के साथ 75% (या 0.75) पर t-value क्या है।
यहाँ एक कोड का उदाहरण है:
import scipy.stats as stats # p-value के लिए t-value निकालें t_value = stats.t.ppf(0.75, 29) print(t_value)
import scipy.stats as stats: यह लाइन SciPy के stats module को इंपोर्ट करती है।stats.t.ppf(0.75, 29): यह फ़ंक्शन 0.75 (75%) के लिए t-value को निकालता है, जो कि 29 degrees of freedom के साथ है। इसका मतलब है कि यह t-value उस बिंदु को दर्शाता है जो शीर्ष 25% (top 25%) और नीचे 75% (bottom 75%) के बीच का विभाजन करता है।print(t_value): यह t-value को कंसोल पर प्रिंट करता है।यह कोड आपको p-value 0.75 के लिए t-value प्रदान करेगा, जो आपको सांख्यिकीय विश्लेषण में मदद करेगा।