

The feedback dataset is then read by our libraries. Let’s have a look at that.
INPUT:
data = pd.read_csv(‘feedback.csv’)

As you can see, the dataset you wish to look at is “feedback.csv”. And in this instance, we know we are utilising the Pandas library to read our dataset as we see “pd.read csv” as the prior function.
The isnull function, a sophisticated Python hack, will then be used to find our data. Actually a common function, “isnull” aids in locating missing items in our collection. This information is helpful since it shows what has to be fixed throughout the data cleaning process.
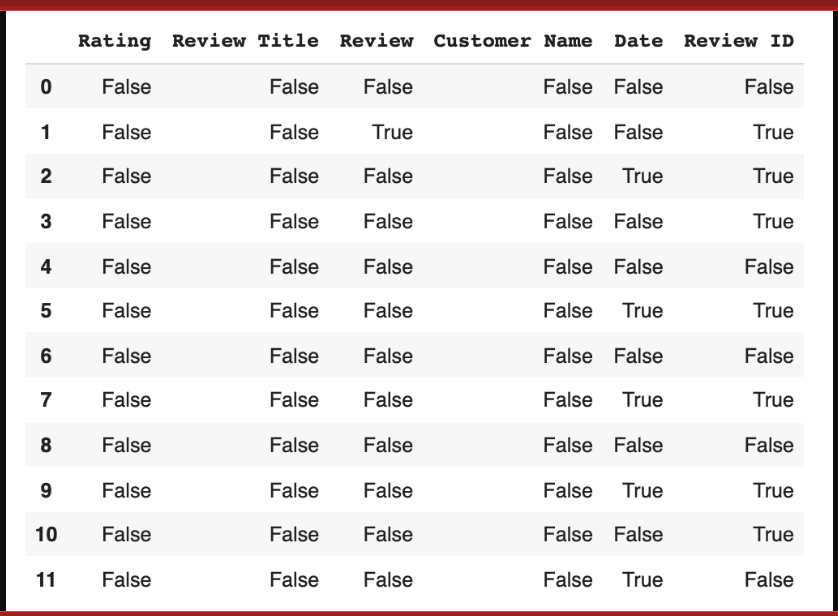
data.isnull()
We get a collection of boolean values as our output result.
The list can provide us with a variety of insights. The first thing to consider is where the missing data is; any column with a ‘True’ reading denotes that the data file’s category for that column contains missing data.
Datapoint 1 has missing information in its Review section and Review ID section, for instance (both are marked true).
Each feature’s missing data can be expanded further by coding:
Dropping the data
Another choice will need to be made: to maintain the data in the set while simply dropping the missing values, or to completely remove the feature (the entire column) because there are so many missing datapoints that it is unusable for analysis.
You must go in and label the missing values as void in accordance with Pandas or NumBy standards if you want to remove them (see section below). However, this is the code to remove the full column:
INPUT:
remove = [‘Review ID’,’Date’]
data.drop(remove, inplace =True, axis =1)
2. Input any missing data
Technically speaking, adding individual values using Pandas or NumBy standards is the same as adding missing data; we refer to it as adding “No Review.” When entering missing data, you have two options: manually enter the right information or add “No Review” using the code below.
INPUT:
data[‘Review’] = data[‘Review’].fillna(‘No review’)
Similar to missing data, duplicates are problematic and choke analytics tools. Let’s find them and get rid of them.
In order to find duplicates, we start with:
data.duplicated()

data.drop_duplicates()