
Table of Contents
Toggleडेटा साइंस की दुनिया में, डेटा क्लीनिंग को अक्सर सबसे महत्वपूर्ण कदम माना जाता है। आंकड़ों का विश्लेषण करते समय, आपके पास जो डेटा होता है, वह अक्सर अपूर्ण, गलत या अव्यवस्थित होता है। इसका मतलब यह है कि बिना साफ और सही डेटा के, किसी भी डेटा साइंस प्रोजेक्ट का परिणाम निष्कर्षकारी और सटीक नहीं हो सकता।
डेटा क्लीनिंग के कई तरीके होते हैं, जिनका उपयोग डेटा साइंटिस्ट द्वारा विश्लेषण से पहले किया जाता है। नीचे कुछ प्रमुख तरीके दिए गए हैं:
लापता मानों को दो मुख्य तरीकों से भर सकते हैं:
असामान्य मान (outliers) को पहचानने के लिए हम विभिन्न तरीकों का उपयोग करते हैं, जैसे:
अव्यवस्थित डेटा के लिए कुछ सामान्य सुधारों में शामिल हैं:
जब डेटा को सही तरीके से साफ किया जाता है, तो यह सुनिश्चित करता है कि डेटा साइंस मॉडल अधिक सटीक और विश्वसनीय होंगे। बिना सफाई के डेटा का उपयोग करने से अनुमान गलत हो सकते हैं, और इससे न केवल समय और संसाधनों की बर्बादी होती है बल्कि व्यापारिक फैसलों पर भी गलत प्रभाव पड़ता है।
डेटा क्लीनिंग को नजरअंदाज करना एक बडी गलती हो सकती है। डेटा साइंटिस्ट को हमेशा यह सुनिश्चित करना चाहिए कि डेटा साफ और सही है, ताकि उनके द्वारा बनाए गए मॉडल और एनालिसिस का परिणाम प्रभावी और सही हो। इसलिए डेटा क्लीनिंग को हमेशा अपने डेटा साइंस प्रोजेक्ट की पहली प्राथमिकता बनाएं।
Effective data cleaning is a critical step in preparing data for analysis and training machine learning models.
Understanding
सबसे पहले, आपको डेटा को समझना होगा। स्वास्थ्य डेटासेट में विभिन्न प्रकार के डेटा हो सकते हैं जैसे कि मरीजों के नाम, उम्र, लिंग, वजन, रक्तचाप, और अन्य स्वास्थ्य संबंधित आंकड़े। इस चरण में, आपको संभावित गलतियों और असंगतियों की पहचान करनी होगी। क्या डेटा में कोई मिसिंग वैल्यूज हैं? क्या कुछ डेटा आउट्लायर्स हैं (जैसे कि बहुत अधिक या बहुत कम मान)? क्या कुछ रिकॉर्ड डुप्लिकेट हैं?
डेटा में मिसिंग वैल्यूज को सही ढंग से संभालना बेहद जरूरी है। आप इसके लिए विभिन्न इम्पुटेशन तकनीकों का उपयोग कर सकते हैं:
आउट्लायर्स (अत्यधिक उच्च या निम्न मान) किसी डेटासेट में महत्वपूर्ण समस्या पैदा कर सकते हैं। ये डेटा की सामान्य प्रवृत्तियों से बहुत दूर होते हैं और विश्लेषण को विकृत कर सकते हैं। इन आउट्लायर्स को सही करने के लिए, आप z-score या IQR (Interquartile Range) का उपयोग कर सकते हैं। यदि कोई मान अत्यधिक ऊंचा या नीचे है, तो इसे हटाया या फिर सामान्यीकृत (normalize) किया जा सकता है।
डुप्लिकेट रिकॉर्ड्स का होना एक आम समस्या हो सकती है, खासकर जब डेटा कई स्रोतों से इकट्ठा किया जाता है। आप SQL के DISTINCT फंक्शन का उपयोग करके डुप्लिकेट रिकॉर्ड्स को पहचान सकते हैं और हटा सकते हैं। ऐसा करने से डेटा की गुणवत्ता में सुधार होता है और विश्लेषण अधिक प्रभावी होता है।
यदि आपके डेटा में कई प्रकार के विभिन्न आकार या इकाइयाँ (जैसे वजन किलो में और रक्तचाप मिमीHg में) हो सकती हैं, तो डेटा को समान पैमाने पर लाना आवश्यक है। इसके लिए आप min-max scaling या standardization का उपयोग कर सकते हैं। यह सुनिश्चित करता है कि सभी विशेषताएँ समान महत्व के साथ विश्लेषण में शामिल हों।
श्रेणीबद्ध डेटा को मशीन लर्निंग मॉडल के लिए उपयुक्त बनाना आवश्यक है। इसके लिए आप बाइनरी एन्कोडिंग जैसे तरीकों का उपयोग कर सकते हैं, जिससे श्रेणियाँ (जैसे ‘हां’ और ‘नहीं’) को संख्यात्मक रूप में बदल दिया जाता है। इससे मॉडल को डेटा को समझने में आसानी होती है।
आकस्मिक डेटा (imbalanced data) तब होता है जब एक वर्ग (जैसे एक बीमारी का लक्षण) का उदाहरण अन्य वर्गों से अधिक होते हैं। इस समस्या का समाधान करने के लिए आप synthetic data generation जैसे तकनीकों का उपयोग कर सकते हैं। इससे डेटा को संतुलित किया जा सकता है और विश्लेषण या मॉडलिंग में किसी एक वर्ग का पक्षपाती परिणाम आने की संभावना कम हो जाती है।
डेटा की सफाई के बाद, यह जरूरी है कि आप इसे परीक्षण करें और सत्यापित करें। इसके लिए आप डेटा को प्रशिक्षण (training) और परीक्षण (testing) सेटों में बाँट सकते हैं। आप विभिन्न सफाई विधियों के प्रभाव को hold-out validation के जरिए जाँच सकते हैं। यह सुनिश्चित करता है कि सफाई के बाद डेटा सही है और मॉडल अच्छे परिणाम दे रहे हैं।
डेटा की सफाई एक महत्वपूर्ण और निरंतर चलने वाली प्रक्रिया है। यह सुनिश्चित करती है कि आपका डेटा किसी भी प्रकार की त्रुटियों, आउट्लायर्स, या असंगतियों से मुक्त हो और विश्लेषण के लिए तैयार हो। इस प्रक्रिया के जरिए आप बेहतर मॉडल बना सकते हैं, जो भविष्य के निर्णयों में मददगार हो। इसलिए, हमेशा डेटा को अच्छे से साफ करें और फिर विश्लेषण करें।
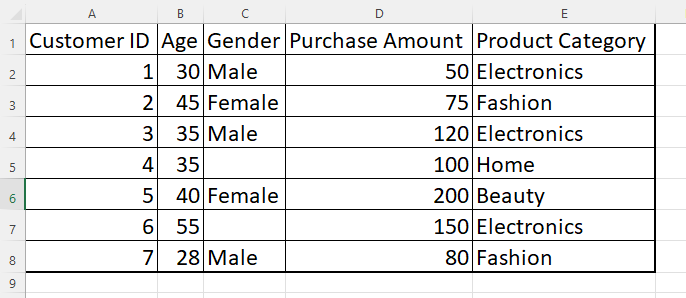
To perform data cleaning and analysis using Python, you can use various libraries such as Pandas, NumPy, and Matplotlib. Here’s an example of how you can apply the mentioned steps to the dataset using Python:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('dataset.csv') # Replace 'dataset.csv' with the actual file path # Replace missing values in 'Age' column with the median age
median_age = df['Age'].median()
df['Age'].fillna(median_age, inplace=True)
# Replace missing values in 'Purchase Amount' column with the mean purchase amount
mean_purchase = df['Purchase Amount'].mean()
df['Purchase Amount'].fillna(mean_purchase, inplace=True)
df.drop_duplicates(subset='Customer ID', inplace=True)
df = pd.get_dummies(df, columns=['Gender'])
# Standardize 'Purchase Amount' using z-score
df['Purchase Amount'] = (df['Purchase Amount'] - df['Purchase Amount'].mean()) / df['Purchase Amount'].std()
# Apply techniques like oversampling or undersampling to balance the data if necessary
# Example: Oversampling the minority class
from sklearn.utils import resample
df_majority = df[df['Product Category'] == 'Electronics']
df_minority = df[df['Product Category'] == 'Home']
df_minority_oversampled = resample(df_minority, replace=True, n_samples=len(df_majority), random_state=42)
df_balanced = pd.concat([df_majority, df_minority_oversampled])
# Split the dataset into training and testing subsets
from sklearn.model_selection import train_test_split
X = df.drop(['Product Category'], axis=1)
y = df['Product Category']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)