
Table of Contents
Toggleमशीन लर्निंग (Machine Learning) की दुनिया में दो सबसे महत्वपूर्ण प्रकार होते हैं — Supervised Learning और Unsupervised Learning। इन दोनों तकनीकों का उपयोग Artificial Intelligence (AI), Data Science, Customer Analytics, Recommendation Systems, Fraud Detection और Business Analytics में किया जाता है। यदि आप मशीन लर्निंग सीखना शुरू कर रहे हैं, तो इन दोनों के बीच का अंतर समझना बहुत जरूरी है।
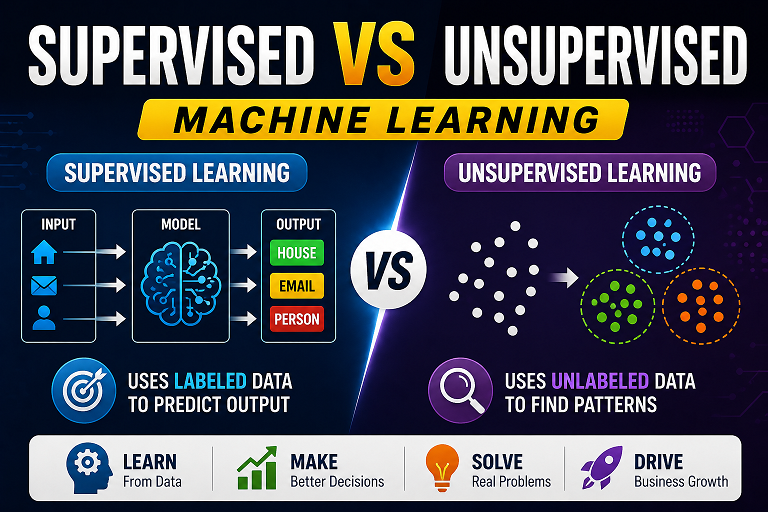
Supervised Learning में मशीन को सही उत्तर (Labelled Output) के साथ ट्रेन किया जाता है, जबकि Unsupervised Learning में मशीन बिना Label वाले डेटा से स्वयं Patterns खोजती है। आज के समय में Netflix, Amazon, Google, Spotify और Uber जैसी कंपनियाँ Machine Learning Algorithms का उपयोग Recommendation Systems, Fraud Detection, Customer Analytics और Predictive Analytics के लिए करती हैं।

Machine Learning में Supervised Learning और Unsupervised Learning दोनों का उपयोग अलग-अलग प्रकार की समस्याओं को हल करने के लिए किया जाता है। नीचे दी गई तुलना तालिका आपको दोनों तकनीकों के बीच का अंतर आसान हिंदी में समझने में मदद करेगी।
| फीचर | Supervised Learning | Unsupervised Learning |
|---|---|---|
| डेटा टाइप | Labelled Data | Unlabelled Data |
| मुख्य उद्देश्य | Prediction और Classification करना | Hidden Patterns और Groups खोजना |
| उदाहरण | Email Spam Detection, Stock Price Prediction | Customer Segmentation, Market Basket Analysis |
| मुख्य Algorithms | Linear Regression, Decision Tree, SVM | K-Means, Hierarchical Clustering, Apriori |
| डेटा आउटपुट | Known Output | Unknown Output |
| Business Use Cases | Fraud Detection, Medical Diagnosis | Customer Behavior Analysis, Recommendation Systems |
| Accuracy | ज्यादा Accurate Predictions | Pattern Discovery पर Focus |
| Real-Life Companies | Google, Netflix, Amazon | Spotify, Amazon, Ecommerce Platforms |
यदि आपके पास Labelled Data मौजूद है और आप Prediction करना चाहते हैं, तो Supervised Learning सबसे अच्छा विकल्प होता है। लेकिन यदि आप डेटा के अंदर छिपे Patterns, Customer Groups या Relationships खोजना चाहते हैं, तो Unsupervised Learning उपयोगी होता है। आज के समय में Amazon, Netflix, Google, Spotify और Uber जैसी कंपनियाँ दोनों प्रकार की Machine Learning तकनीकों का उपयोग Recommendation Systems, Customer Analytics, Fraud Detection और Predictive Analytics के लिए करती हैं।
आज के समय में Machine Learning का उपयोग Healthcare, Finance, Ecommerce, Cyber Security, Social Media और Artificial Intelligence जैसी industries में तेजी से बढ़ रहा है। Supervised और Unsupervised Learning दोनों का उपयोग अलग-अलग business problems को solve करने, customer behavior समझने, fraud detect करने और predictions करने के लिए किया जाता है।
Netflix personalized movie recommendations के लिए Machine Learning का उपयोग करता है, Amazon customer behavior और product recommendations analyze करता है, जबकि Google search ranking और ad targeting improve करने के लिए AI algorithms का उपयोग करता है। Spotify music recommendations, Uber dynamic pricing और PayPal fraud detection जैसे systems भी Machine Learning Models पर आधारित हैं।
Machine Learning में Supervised Learning और Unsupervised Learning दोनों अलग-अलग उद्देश्यों के लिए उपयोग किए जाते हैं। Supervised Learning मुख्य रूप से Prediction और Classification के लिए उपयोग होती है, जबकि Unsupervised Learning Data Patterns, Clustering और Customer Insights खोजने में मदद करती है। नीचे दी गई तुलना तालिका दोनों तकनीकों के बीच मुख्य अंतर को आसान हिंदी में समझाती है।
| मापदंड | Supervised Learning | Unsupervised Learning |
|---|---|---|
| डेटा लेबलिंग | Labelled Data का उपयोग करता है | Unlabelled Data का उपयोग करता है |
| मुख्य उद्देश्य | Prediction और Classification करना | Hidden Patterns और Clusters खोजना |
| प्रमुख उपयोग | Fraud Detection, Image Recognition, Spam Detection | Customer Segmentation, Recommendation Systems |
| कॉम्प्लेक्सिटी | कम Complex | अधिक Complex |
| Algorithm Examples | Linear Regression, Decision Trees, SVM | K-Means, Hierarchical Clustering, Apriori |
| Output Type | Known Output | Unknown Output |
| Real-Life Examples | Email Spam Detection, Face Recognition | Amazon Recommendations, Customer Clustering |
| Used By Companies | Google, Netflix, PayPal | Amazon, Spotify, Ecommerce Platforms |
यदि आपके पास Labelled Data मौजूद है और आप भविष्यवाणी (Prediction) करना चाहते हैं, तो Supervised Learning सबसे उपयुक्त विकल्प है। लेकिन यदि आप डेटा में छिपे Patterns, Customer Groups या Relationships खोजने चाहते हैं, तो Unsupervised Learning अधिक उपयोगी होती है। आज की दुनिया में Netflix, Amazon, Google, Spotify और Uber जैसी कंपनियाँ Machine Learning Algorithms का उपयोग Recommendation Systems, Predictive Analytics, Customer Analytics और Fraud Detection के लिए कर रही हैं।
Machine Learning में Supervised Learning और Unsupervised Learning दोनों की अपनी-अपनी strengths और limitations होती हैं। जहाँ Supervised Learning prediction और classification tasks में अत्यधिक प्रभावी होती है, वहीं Unsupervised Learning hidden patterns और customer behavior analysis खोजने में मदद करती है।
यदि आपका लक्ष्य Prediction करना है और आपके पास Labelled Data उपलब्ध है, तो Supervised Learning सबसे अच्छा विकल्प होता है। लेकिन यदि आप Data के अंदर छिपे Patterns, Customer Groups या Similarities खोजने चाहते हैं, तो Unsupervised Learning अधिक उपयोगी होती है। आज के समय में AI, Data Science, Ecommerce, Banking, Healthcare और Cyber Security जैसी industries दोनों प्रकार की Machine Learning techniques का उपयोग कर रही हैं।
नीचे दिए गए Machine Learning MCQs छात्रों, beginners, interview preparation और competitive exams के लिए उपयोगी हैं। ये प्रश्न Supervised Learning, Unsupervised Learning, Machine Learning Types, Classification, Clustering और Real-World Examples को आसान हिंदी में समझने में मदद करेंगे।
Machine Learning MCQs छात्रों, beginners और interview candidates के लिए अत्यंत उपयोगी हैं। ये प्रश्न Supervised Learning, Unsupervised Learning, Reinforcement Learning, Classification, Clustering और Predictive Analytics जैसी अवधारणाओं को जल्दी समझने में मदद करते हैं। आज के समय में AI, Data Science और Machine Learning skills की demand तेजी से बढ़ रही है।
Reinforcement Learning, Machine Learning का तीसरा प्रमुख प्रकार है जिसमें मशीन या AI Agent अपने Environment से Interaction करके सीखता है। इस तकनीक में मशीन को अच्छे कार्यों के लिए Reward और गलत कार्यों के लिए Penalty दी जाती है। धीरे-धीरे AI System यह सीख जाता है कि कौन-सा Action सबसे अच्छा परिणाम देता है।
Supervised Learning में मशीन Labelled Data से सीखती है, Unsupervised Learning बिना Label वाले Data में Patterns खोजती है, जबकि Reinforcement Learning Rewards और Penalties के आधार पर निर्णय लेना सीखती है। आज के समय में Google DeepMind, Tesla, OpenAI और Robotics कंपनियाँ Reinforcement Learning का उपयोग Self-Driving Cars, AI Games, Robotics और Automation Systems में कर रही हैं।
नीचे दिए गए Frequently Asked Questions (FAQs) छात्रों, beginners और interview preparation करने वालों के लिए उपयोगी हैं। ये FAQs Supervised Learning, Unsupervised Learning, Reinforcement Learning, Machine Learning Algorithms और Real-Life Applications को आसान हिंदी में समझाने के लिए तैयार किए गए हैं।
आज के समय में Artificial Intelligence, Data Science और Machine Learning की demand तेजी से बढ़ रही है। Healthcare, Banking, Ecommerce, Cyber Security, Finance और Automation जैसी industries Machine Learning का उपयोग business growth और smart decision-making के लिए कर रही हैं। यदि आप भविष्य में AI Engineer, Data Scientist या Machine Learning Engineer बनना चाहते हैं, तो Supervised, Unsupervised और Reinforcement Learning की समझ अत्यंत महत्वपूर्ण है।