
Predictive Analytics Meaning in Hindi | एनालिटिक्स का मतलब क्या होता है?
Predictive Analytics Meaning in Hindi | प्रेडिक्टिव एनालिटिक्स क्या है? Predictive Analytics का अर्थ है भविष्य के परिणामों का अनुमान—ऐतिहासिक […]
Machine Learning के Top 10 Algorithms – आसान हिंदी में समझें
🧠 Machine Learning के Top 10 Algorithms – आसान हिंदी में समझें अगर आप Machine Learning सीखना चाहते हैं, तो […]
Merging Restaurant Order Datasets and Mastering Data Visualization with Python Charts
Restaurant order DataSets dataset Link This dataset have two table menu_items Table: menu_item_id: Unique identifier for each menu item. This […]
Beginner’s Guide: FAQs on Data Science and Machine Learning

Machine learning and data science are related fields, but they have distinct focuses and objectives: Machine Learning (ML): Definition: Machine […]
Supervised vs Unsupervised Learning in Hindi with Examples [2026]
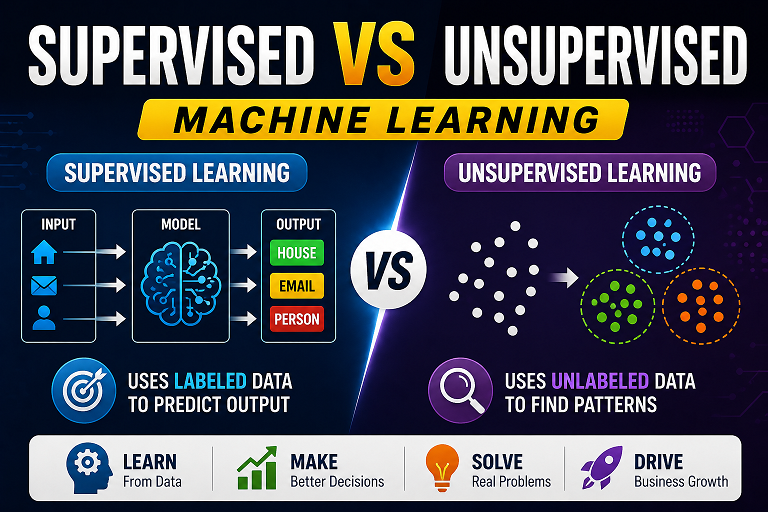
🤖 Machine Learning Basics in Hindi Supervised और Unsupervised Learning क्या है? आसान हिंदी में समझें मशीन लर्निंग (Machine Learning) […]
Comprehensive Analysis of Airline Passenger Satisfaction in python

In today’s ever-connected world, air travel serves as a vital conduit, linking people and places across the globe. Delving into […]
Data Analytics Insights Predictive Power in Excel

Student Exam Scores Student Hours Studied Exam Score John 2 75 Emily 3 85 David 1 60 Sarah 4 90 […]
Data Cleaning in Python with Libraries + Visualization using Matplotlib & Seaborn
🔍 Master Data Cleaning in Python and Charting with Matplotlib & Seaborn Learn data cleaning in Python using powerful libraries […]
Top 10 Example of machine learning for Data Analytics
Machine learning is important for data analytics because it enables businesses to gain insightful data and make well-informed choices. Machine […]
9 आसान तरीके: Data Analytics Job के लिए Digital Presence कैसे Strong बनाएं
डेटा एनालिटिक्स जॉब के लिए अपनी डिजिटल उपस्थिति बढ़ाने के 9 आसान तरीके अगर आप डेटा एनालिटिक्स फील्ड में करियर […]
Critical Thinking in Data Analysis: Importance, Tips & Examples [2025]
Section 1 Introduction to Critical Thinking in Data Analysis In a truly data-driven world, critical thinking in data analysis (often […]
SQL: Why it’s Essential for Data Analytics in 2025

A language SQL (Structured Query Language) is used to manage and analyse relational databases. SQL can be used to retrieve, manipulate, and consolidate data for data analytics in order to get valuable insights. SQL has become a crucial tool in the field of data analytics in 2023. It is essential due […]