
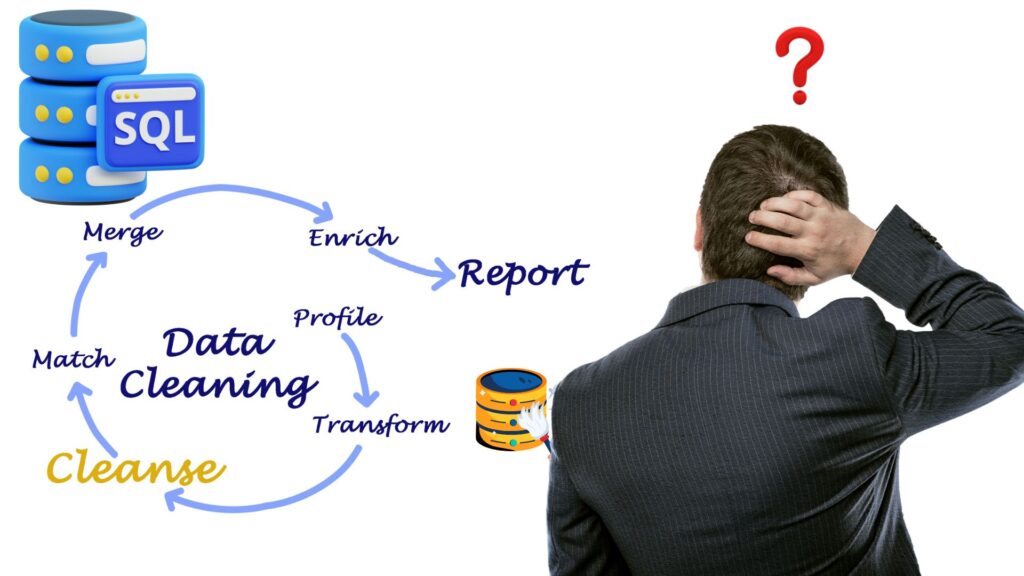
Data Cleaning के लिए 50 SQL Commands — हिंदी में Complete [2025 Guide]
Table of Contents
ToggleData cleaning किसी भी Data Analytics प्रोजेक्ट की नींव है। साफ़ और structured data के बिना advanced models भी सही नतीजे नहीं दे पाते। इस गाइड में हमने उन Top 50 SQL Commands को रखा है जिन्हें हर data analyst को जानना चाहिए — duplicates हटाना, NULL values संभालना, strings और numbers ठीक करना और और भी बहुत कुछ। 🚀 Updated for 2025 — यह आपका step-by-step SQL data cleaning handbook है।
SQL क्यों उपयोगी है Data Cleaning के लिए?
SQL (Structured Query Language) सिर्फ data पूछने के लिए नहीं है — यह datasets को clean और prepare करने का एक मजबूत टूल है। duplicates हटाना, NULL values संभालना, टेक्स्ट सुधारना, dates को सही format में लाना और tables री-स्ट्रक्चर करना — ये सभी काम SQL से तेज़ी और efficiency से किए जा सकते हैं। यह data analysts और BI professionals के लिए एक अनिवार्य skill है।
🔍 सटीकता (Accuracy)
Duplicates हटाकर और errors ठीक करके भरोसेमंद analysis सुनिश्चित करें।
⚡ तेज़ी (Efficiency)
Optimized SQL queries से लाखों rows को सेकंड में clean करें।
📊 स्टैण्डर्डाइज़ेशन (Standardization)
Text, dates और numbers को consistent format में बदलें।
Section 1 — Duplicate Records हटाना (Removing Duplicates)
Duplicate records (डुप्लिकेट रिकॉर्ड) datasets में आम हैं — खासकर जब data multiple sources से आता है। नीचे कुछ आम तरीक़े दिए गए हैं जो आप SQL में duplicates हटाने के लिए उपयोग कर सकते हैं।
Example — Duplicate rows हटाना (by email)
-- सबसे छोटा id रखने के लिए और बाकी हटाने के लिए
DELETE FROM customers
WHERE id NOT IN (
SELECT MIN(id)
FROM customers
GROUP BY email
);
यह query email field के आधार पर duplicates हटाती है और सबसे छोटी `id` वाली row बचाती है — production DB में execute करने से पहले हमेशा backup लें।
🏆 Section 1: Duplicate रिकॉर्ड्स हटाना (Removing Duplicates in SQL)
Data Analytics में duplicate रिकॉर्ड्स एक आम समस्या हैं। ये results को बिगाड़ सकते हैं, metrics को inflate कर सकते हैं और गलत निर्णयों की ओर ले जा सकते हैं. SQL में ऐसी बहुत सी commands हैं जो duplicates को आसानी से detect और remove कर देती हैं। चलिए एक sample Sales तालिका को clean करते हैं।
📊 Step 1: Table बनाना & डेटा डालना
CREATE TABLE Sales (
order_id INT,
customer_id INT,
order_date DATE
);
INSERT INTO Sales VALUES
(1, 101, '2025-01-10'),
(2, 101, '2025-01-10'), -- Duplicate
(3, 102, '2025-01-12'),
(4, 103, '2025-01-14'),
(5, 103, '2025-01-14'); -- Duplicate
✅ Original Sales table में कुछ duplicate customer_id हैं।
| order_id | customer_id | order_date |
|---|---|---|
| 1 | 101 | 2025-01-10 |
| 2 | 101 | 2025-01-10 |
| 3 | 102 | 2025-01-12 |
| 4 | 103 | 2025-01-14 |
| 5 | 103 | 2025-01-14 |
1️⃣ SELECT DISTINCT
SELECT DISTINCT customer_id
FROM Sales;
| customer_id |
|---|
| 101 |
| 102 |
| 103 |
2️⃣ GROUP BY + HAVING
SELECT customer_id, COUNT(*) AS duplicate_count
FROM Sales
GROUP BY customer_id
HAVING COUNT(*) > 1;
| customer_id | duplicate_count |
|---|---|
| 101 | 2 |
| 103 | 2 |
3️⃣ DELETE Duplicate Rows
DELETE FROM Sales
WHERE rowid NOT IN (
SELECT MIN(rowid)
FROM Sales
GROUP BY customer_id
);
| Remaining Rows |
|---|
| 1 | 101 | 2025-01-10 |
| 3 | 102 | 2025-01-12 |
| 4 | 103 | 2025-01-14 |
4️⃣ ROW_NUMBER() Window
SELECT customer_id,
ROW_NUMBER() OVER(
PARTITION BY customer_id
ORDER BY order_date
) AS row_num
FROM Sales;
| customer_id | row_num |
|---|---|
| 101 | 1 |
| 101 | 2 |
| 103 | 1 |
| 103 | 2 |
5️⃣ CTE + ROW_NUMBER()
WITH duplicates AS (
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY customer_id
ORDER BY order_date
) AS row_num
FROM Sales
)
DELETE FROM duplicates WHERE row_num > 1;
| Remaining Rows |
|---|
| 1 | 101 | 2025-01-10 |
| 3 | 102 | 2025-01-12 |
| 4 | 103 | 2025-01-14 |
✨ सेक्शन 2: डेटा को मानकीकृत करना (Formatting)
असंगठित डेटा में अक्सर अतिरिक्त स्पेस, असंगत कैपिटलाइज़ेशन और स्पेलिंग की गलतियाँ होती हैं। SQL हमें डेटा को साफ़ और समान प्रारूप में बदलने के लिए उपयोगी फ़ंक्शन देता है। चलिए, हम अपनी Products तालिका को चरण-दर-चरण साफ़ करते हैं।
📊 चरण 1: तालिका बनाएं और डेटा जोड़ें
CREATE TABLE Products (
product_id INT,
product_name VARCHAR(50),
category VARCHAR(50)
);
INSERT INTO Products VALUES
(1, ' Laptop', 'ELECTRONICS '),
(2, 'MOBILE ', 'electronics'),
(3, 'HeadPhones', ' Electronics'),
(4, 'tablet', 'ELECTRONICS'),
(5, ' CAMERA ', 'Electronics');
✅ Products तालिका में अतिरिक्त स्पेस, मिश्रित अक्षर और असंगत श्रेणी नाम हैं।
| product_id | product_name | category |
|---|---|---|
| 1 | Laptop | ELECTRONICS |
| 2 | MOBILE | electronics |
| 3 | HeadPhones | Electronics |
| 4 | tablet | ELECTRONICS |
| 5 | CAMERA | Electronics |
1️⃣ TRIM() – अतिरिक्त स्पेस हटाएं
SELECT product_id,
TRIM(product_name) AS clean_name
FROM Products;
| पहले | बाद में |
|---|---|
| ” Laptop” | “Laptop” |
| “MOBILE “ | “MOBILE” |
2️⃣ UPPER() – टेक्स्ट को अपरकेस में बदलें
SELECT product_id,
UPPER(category) AS clean_category
FROM Products;
| पहले | बाद में |
|---|---|
| “electronics” | “ELECTRONICS” |
| ” Electronics” | “ELECTRONICS” |
3️⃣ LOWER() – टेक्स्ट को लोअरकेस में बदलें
SELECT product_id,
LOWER(product_name) AS clean_name
FROM Products;
| पहले | बाद में |
|---|---|
| “HeadPhones” | “headphones” |
| ” CAMERA “ | ” camera “ |
4️⃣ INITCAP() – प्रत्येक शब्द का पहला अक्षर बड़ा करें
SELECT INITCAP(product_name) AS formatted_name
FROM Products;
| पहले | बाद में |
|---|---|
| “tablet” | “Tablet” |
| “mobile “ | “Mobile” |
5️⃣ REPLACE() – गलत टेक्स्ट को सही करें
SELECT product_id,
REPLACE(category, 'Electronics', 'ELECTRONICS') AS fixed_category
FROM Products;
| पहले | बाद में |
|---|---|
| “Electronics” | “ELECTRONICS” |
| ” Electronics” | “ELECTRONICS” |
📝 Section 4: String Cleaning और Manipulation
String data में अक्सर extra characters, inconsistent text, या गलत substrings होते हैं। SQL में कई शक्तिशाली string functions हैं जिनसे आप text values को clean, extract और format कर सकते हैं। अगर आपने पहले Pandas से data cleaning practice की है, तो आप देखेंगे कि कई functions SQL में भी मिलते-जुलते हैं। चलिए एक sample Customers table पर काम करते हैं।
📊 Step 1: Table बनाना & डेटा डालना
CREATE TABLE Customers (
cust_id INT,
cust_name VARCHAR(50),
phone VARCHAR(20),
email VARCHAR(50)
);
INSERT INTO Customers VALUES
(1, ' AMIT SHARMA ', ' 9876543210 ', 'amit.sharma@ gmail.com'),
(2, 'rohit KUMAR', '91-9998887777', 'rohit.kumar@@yahoo.com'),
(3, 'PRIYA ', '8887776666', ' priyaverma@gmail.com '),
(4, 'sneha', '999-111-222', 'sneha123@outlook. com');
| cust_id | cust_name | phone | |
|---|---|---|---|
| 1 | ” AMIT SHARMA “ | ” 9876543210 “ | “amit.sharma@ gmail.com” |
| 2 | “rohit KUMAR” | “91-9998887777” | “rohit.kumar@@yahoo.com” |
| 3 | “PRIYA “ | “8887776666” | ” priyaverma@gmail.com “ |
| 4 | “sneha” | “999-111-222” | “sneha123@outlook. com” |
1️⃣ TRIM() – Extra Spaces हटाना
SELECT cust_id, TRIM(cust_name) AS clean_name
FROM Customers;
| Before | After |
|---|---|
| ” AMIT SHARMA “ | “AMIT SHARMA” |
| “PRIYA “ | “PRIYA” |
2️⃣ UPPER() & LOWER() – Case सही करना
SELECT cust_id, UPPER(cust_name) AS upper_name,
LOWER(cust_name) AS lower_name
FROM Customers;
| Before | UPPER() | LOWER() |
|---|---|---|
| “rohit KUMAR” | “ROHIT KUMAR” | “rohit kumar” |
| “sneha” | “SNEHA” | “sneha” |
3️⃣ SUBSTRING() – Text निकालना
SELECT cust_id, SUBSTRING(phone, 1, 10) AS clean_phone
FROM Customers;
| Before | After |
|---|---|
| “91-9998887777” | “91-9998887” |
| “999-111-222” | “999-111-22” |
4️⃣ REPLACE() – गलत characters ठीक करना
SELECT cust_id, REPLACE(email, ' ', '') AS clean_email
FROM Customers;
| Before | After |
|---|---|
| “amit.sharma@ gmail.com” | “amit.sharma@gmail.com” |
| “sneha123@outlook. com” | “sneha123@outlook.com” |
5️⃣ CONCAT() – Fields जोड़ना (Merge)
SELECT cust_id, CONCAT(cust_name, ' - ', phone) AS full_contact
FROM Customers;
| Before | After |
|---|---|
| “AMIT SHARMA” + “9876543210” | “AMIT SHARMA – 9876543210” |
| “PRIYA” + “8887776666” | “PRIYA – 8887776666” |
इन string manipulation commands को mastery करना हर analyst के लिए ज़रूरी है। एक बार जब आप इन पर comfortable हो जाएँगे, तो आप वही principles Power BI या Python में भी apply कर सकते हैं ताकि data preparation seamless हो।
🔢 Section 5: Numeric Cleaning और Transformation
Numbers analytics की रीढ़ होते हैं — लेकिन raw data में अक्सर inconsistent decimal places, negative values, या rounding issues होते हैं। SQL में ऐसे functions हैं जिनसे आप numbers को round, convert और validate कर सकते हैं। अगर आपने हमारा linear regression गाइड देखा है, तो आप जानते हैं कि accurate predictions के लिए clean numbers कितने ज़रूरी हैं।
📊 Step 1: Table बनाना & डेटा डालना
CREATE TABLE SalesData (
sale_id INT,
amount DECIMAL(10,4),
discount DECIMAL(5,2)
);
INSERT INTO SalesData VALUES
(1, 2500.4567, 5.5),
(2, -300.9876, 10.0),
(3, 1999.9999, 0.0),
(4, 150.75, NULL),
(5, 100.1234, 2.25);
✅ SalesData table में extra decimal places, negative values और NULL discounts हैं।
| sale_id | amount | discount |
|---|---|---|
| 1 | 2500.4567 | 5.5 |
| 2 | -300.9876 | 10.0 |
| 3 | 1999.9999 | 0.0 |
| 4 | 150.75 | NULL |
| 5 | 100.1234 | 2.25 |
1️⃣ ROUND() – Decimal Places ठीक करना
SELECT sale_id,
ROUND(amount, 2) AS rounded_amount
FROM SalesData;
| Before | After |
|---|---|
| 2500.4567 | 2500.46 |
| 1999.9999 | 2000.00 |
2️⃣ ABS() – Negative Values संभालना
SELECT sale_id,
ABS(amount) AS positive_amount
FROM SalesData;
| Before | After |
|---|---|
| -300.9876 | 300.9876 |
3️⃣ CEIL() & FLOOR()
SELECT sale_id,
CEIL(amount) AS ceil_value,
FLOOR(amount) AS floor_value
FROM SalesData;
| Before | CEIL() | FLOOR() |
|---|---|---|
| 150.75 | 151 | 150 |
| 100.1234 | 101 | 100 |
4️⃣ NULLIF() – Divide-by-zero से बचना
SELECT sale_id,
amount / NULLIF(discount, 0) AS safe_division
FROM SalesData;
| Before | After |
|---|---|
| 1999.9999 ÷ 0.0 = Error | 1999.9999 ÷ NULL = NULL |
5️⃣ CAST() – Data Type बदलना (Convert)
SELECT sale_id,
CAST(amount AS INT) AS int_amount
FROM SalesData;
| Before | After |
|---|---|
| 2500.4567 | 2500 |
| 100.1234 | 100 |
इन functions से numeric columns analysis-ready बन जाते हैं। Clean numbers सिर्फ SQL queries के लिए ही नहीं बल्कि advanced models (जैसे neural networks) के लिए भी ज़रूरी हैं — जहाँ छोटी decimal inconsistencies भी prediction को प्रभावित कर सकती हैं।
⏰ Section 6: Date & Time Cleaning in SQL (दिनांक और समय की सफाई)
Dates data cleaning का सबसे tricky हिस्सा हो सकते हैं। अलग-अलग date formats time-series analysis, reporting और forecasting में problem पैदा कर देते हैं। SQL powerful functions देता है ताकि आप date और time values को clean, convert और extract कर सकें। अगर आपने हमारा time series analysis पढ़ा है, तो आप समझते हैं कि dates को सही तरीके से prepare करना कितना ज़रूरी है।
📊 Step 1: Table बनाएँ & डेटा डालें
CREATE TABLE Orders (
order_id INT,
order_date VARCHAR(20),
delivery_date VARCHAR(20)
);
INSERT INTO Orders VALUES
(1, '2025-01-10', '2025/01/15'),
(2, '10-02-2025', '2025-02-20'),
(3, '2025/03/05', '2025-03-10'),
(4, '15-04-2025', '2025/04/25'),
(5, '2025-05-12', NULL);
✅ Orders table में mixed date formats और missing delivery dates हैं।
| order_id | order_date | delivery_date |
|---|---|---|
| 1 | 2025-01-10 | 2025/01/15 |
| 2 | 10-02-2025 | 2025-02-20 |
| 3 | 2025/03/05 | 2025-03-10 |
| 4 | 15-04-2025 | 2025-04-25 |
| 5 | 2025-05-12 | NULL |
1️⃣ CAST() / CONVERT() – Dates को Standardize करें
SELECT order_id,
CAST(order_date AS DATE) AS clean_order_date
FROM Orders;
| Before | After |
|---|---|
| “10-02-2025” | “2025-02-10” |
| “2025/03/05” | “2025-03-05” |
2️⃣ DATEPART() – Date के components निकालना
SELECT order_id,
DATEPART(year, CAST(order_date AS DATE)) AS order_year,
DATEPART(month, CAST(order_date AS DATE)) AS order_month
FROM Orders;
| Before | After |
|---|---|
| “2025-01-10” | Year=2025, Month=01 |
3️⃣ DATEDIFF() – अवधि (Duration) निकालना
SELECT order_id,
DATEDIFF(day, CAST(order_date AS DATE), CAST(delivery_date AS DATE)) AS delivery_days
FROM Orders;
| order_date | delivery_date | Days |
|---|---|---|
| 2025-01-10 | 2025-01-15 | 5 |
| 2025-03-05 | 2025-03-10 | 5 |
4️⃣ GETDATE() / CURRENT_DATE – आज के साथ तुलना
SELECT order_id,
DATEDIFF(day, CAST(order_date AS DATE), GETDATE()) AS days_since_order
FROM Orders;
| order_date | Today | Days Since |
|---|---|---|
| 2025-01-10 | 2025-09-02 | 235 |
5️⃣ FORMAT() – Custom date format बनाना
SELECT order_id,
FORMAT(CAST(order_date AS DATE), 'dd-MMM-yyyy') AS formatted_date
FROM Orders;
| Before | After |
|---|---|
| “2025-01-10” | “10-Jan-2025” |
Dates को सही तरीके से clean करने के बाद आप accurate time-series forecasts, dashboards और reporting pipelines बना सकते हैं। यह advanced projects (जैसे Walmart का Inventory Prediction) में बेहद useful होता है।
🧠 Section 8: Advanced SQL Data Cleaning Techniques (Pro Level)
अब तक आपने basic SQL commands सीखी हैं, लेकिन professional data cleaning में हमें कभी-कभी complex logic, regex pattern matching और conditional cleaning की जरूरत होती है। चलिए कुछ advanced SQL tricks देखते हैं जो real-world analytics में बहुत useful हैं।
1️⃣ Using CTE (Common Table Expression)
WITH cleaned AS (
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY customer_id
ORDER BY order_date
) AS rn
FROM Sales
)
DELETE FROM cleaned WHERE rn > 1;
👉 बड़े datasets में duplicate हटाने का efficient तरीका।
2️⃣ CASE WHEN – Conditional Cleaning
SELECT emp_name,
CASE
WHEN salary IS NULL THEN 40000
WHEN salary < 0 THEN ABS(salary)
ELSE salary
END AS clean_salary
FROM Employee;
✅ Conditions के हिसाब से salary को normalize करने का तरीका।
3️⃣ REGEXP_REPLACE() – Pattern-Based Cleaning
SELECT email,
REGEXP_REPLACE(email, '\\s+', '') AS cleaned_email
FROM Customers;
🧹 Regex से unwanted spaces या symbols को हटाना आसान।
🧠 Section 8: Advanced SQL Data Cleaning Techniques (Pro Level)
अब तक आपने basic SQL commands सीखी हैं, लेकिन professional data cleaning में हमें कभी-कभी complex logic, regex pattern matching और conditional cleaning की जरूरत होती है। चलिए कुछ advanced SQL tricks देखते हैं जो real-world analytics में बहुत useful हैं।
1️⃣ Using CTE (Common Table Expression)
WITH cleaned AS (
SELECT *,
ROW_NUMBER() OVER(
PARTITION BY customer_id
ORDER BY order_date
) AS rn
FROM Sales
)
DELETE FROM cleaned WHERE rn > 1;
👉 बड़े datasets में duplicate हटाने का efficient तरीका।
2️⃣ CASE WHEN – Conditional Cleaning
SELECT emp_name,
CASE
WHEN salary IS NULL THEN 40000
WHEN salary < 0 THEN ABS(salary)
ELSE salary
END AS clean_salary
FROM Employee;
✅ Conditions के हिसाब से salary को normalize करने का तरीका।
3️⃣ REGEXP_REPLACE() – Pattern-Based Cleaning
SELECT email,
REGEXP_REPLACE(email, '\\s+', '') AS cleaned_email
FROM Customers;
🧹 Regex से unwanted spaces या symbols को हटाना आसान।
⚙️ Section 9: SQL Data Cleaning Best Practices
Data cleaning करते समय कुछ golden rules follow करने से आपका dataset ज्यादा consistent और analysis-ready बनता है। नीचे कुछ top best practices दिए गए हैं 👇
- ✅ Always backup your raw data before cleaning — ताकि गलती से data loss न हो।
- ✅ Use CTEs instead of multiple nested queries for better readability।
- ✅ Validate each column (NULLs, outliers, invalid types) before modeling।
- ✅ Automate repetitive cleaning tasks using stored procedures।
- ✅ Document every cleaning step for reproducibility and auditing।
🔍 Section 10: Text Search & Pattern Cleaning in SQL
Text fields में अक्सर typos, invalid formats, या hidden characters होते हैं। SQL में pattern-matching functions जैसे LIKE, REGEXP, PATINDEX होते हैं जिनसे आप text values को detect, validate और clean कर सकते हैं। ये techniques NLP में भी बहुत काम आती हैं, जहाँ string patterns का महत्व ज़्यादा होता है।
📊 Step 1: Table बनाएँ & Data डालें
CREATE TABLE Users (
user_id INT,
email VARCHAR(50),
phone VARCHAR(20)
);
INSERT INTO Users VALUES
(1, 'amit.sharma@gmail', '98765-43210'),
(2, 'priya@@yahoo.com', '91 99988 87777'),
(3, 'rohit.kumar@gmail.com', '999-111-2222'),
(4, 'sneha@outlook', '8887776666'),
(5, 'test_user#123.com', '99999');
✅ Users table में invalid emails, irregular phone formats और short numbers हैं।
| user_id | phone | |
|---|---|---|
| 1 | “amit.sharma@gmail” | “98765-43210” |
| 2 | “priya@@yahoo.com” | “91 99988 87777” |
| 3 | “rohit.kumar@gmail.com” | “999-111-2222” |
| 4 | “sneha@outlook” | “8887776666” |
| 5 | “test_user#123.com” | “99999” |
1️⃣ LIKE – Invalid Emails खोजें
SELECT * FROM Users
WHERE email NOT LIKE '%@%.%';
| Invalid Emails |
|---|
| amit.sharma@gmail |
| sneha@outlook |
2️⃣ PATINDEX() – Invalid Symbols detect करें
SELECT user_id, email
FROM Users
WHERE PATINDEX('%[^a-zA-Z0-9@._-]%', email) > 0;
| Emails with Invalid Characters |
|---|
| test_user#123.com |
3️⃣ REGEXP – Phone pattern validate करें
SELECT user_id, phone
FROM Users
WHERE phone NOT REGEXP '^[0-9]{10}$';
| Invalid Phones |
|---|
| 98765-43210 |
| 91 99988 87777 |
| 999-111-2222 |
| 99999 |
4️⃣ STUFF() – Phone numbers mask करें
SELECT user_id,
STUFF(phone, 4, 3, 'XXX') AS masked_phone
FROM Users;
| Before | After |
|---|---|
| 9876543210 | 987XXX210 |
5️⃣ REPLACE() – Formatting साफ़ करें
SELECT user_id,
REPLACE(REPLACE(phone, '-', ''), ' ', '') AS clean_phone
FROM Users;
| Before | After |
|---|---|
| 91 99988 87777 | 919998887777 |
| 999-111-2222 | 9991112222 |
Pattern-based text cleaning mastery data validation के लिए ज़रूरी है। ये SQL commands cybersecurity और fraud detection जैसी fields में भी काम आते हैं — जहां unusual patterns को detect करना critical होता है।
📊 Section 11: Data Aggregation & Summarization in SQL
Once data is cleaned, the next step is to aggregate and summarize it.
Aggregation helps analysts turn raw transactions into insights like totals, averages, and counts.
SQL provides functions like SUM(), COUNT(), GROUP BY, and HAVING to simplify this.
If you’ve read our blog on
steps of data analysis,
this is where insights really start to appear.
📊 Step 1: Create Table & Insert Data
CREATE TABLE Sales (
order_id INT,
customer_id INT,
region VARCHAR(20),
amount DECIMAL(10,2)
);
INSERT INTO Sales VALUES
(1, 101, 'North', 2500.00),
(2, 101, 'North', 3000.00),
(3, 102, 'South', 1500.00),
(4, 103, 'East', 2000.00),
(5, 104, 'East', 2200.00),
(6, 105, 'West', 1800.00),
(7, 106, 'South', 1700.00),
(8, 107, 'North', 5000.00);
✅ The Sales table contains multiple transactions per customer and region.
| order_id | customer_id | region | amount |
|---|---|---|---|
| 1 | 101 | North | 2500.00 |
| 2 | 101 | North | 3000.00 |
| 3 | 102 | South | 1500.00 |
| 4 | 103 | East | 2000.00 |
| 5 | 104 | East | 2200.00 |
| 6 | 105 | West | 1800.00 |
| 7 | 106 | South | 1700.00 |
| 8 | 107 | North | 5000.00 |
1️⃣ GROUP BY – Region-wise Totals
SELECT region, SUM(amount) AS total_sales
FROM Sales
GROUP BY region;
| Region | Total Sales |
|---|---|
| North | 10500.00 |
| South | 3200.00 |
| East | 4200.00 |
| West | 1800.00 |
2️⃣ HAVING – Filter Groups
SELECT region, SUM(amount) AS total_sales
FROM Sales
GROUP BY region
HAVING SUM(amount) > 3000;
| Region | Total Sales |
|---|---|
| North | 10500.00 |
| East | 4200.00 |
3️⃣ COUNT(DISTINCT) – Unique Customers
SELECT region, COUNT(DISTINCT customer_id) AS unique_customers
FROM Sales
GROUP BY region;
| Region | Unique Customers |
|---|---|
| North | 2 |
| South | 2 |
| East | 2 |
| West | 1 |
4️⃣ AVG() – Average Sales
SELECT region, AVG(amount) AS avg_sales
FROM Sales
GROUP BY region;
| Region | Avg Sales |
|---|---|
| North | 3500.00 |
| South | 1600.00 |
| East | 2100.00 |
| West | 1800.00 |
5️⃣ ROLLUP – Subtotals + Grand Total
SELECT region, SUM(amount) AS total_sales
FROM Sales
GROUP BY ROLLUP(region);
| Region | Total Sales |
|---|---|
| North | 10500.00 |
| South | 3200.00 |
| East | 4200.00 |
| West | 1800.00 |
| NULL (Grand Total) | 19700.00 |
Aggregation is where data becomes insight. By grouping, filtering, and summarizing, you create meaningful metrics for dashboards and reports. This process is core to data analyst careers where summarizing trends drives decision-making.
🔗 Section 12: Data Joins & Cleaning Across Tables in SQL
Most business data lives in multiple related tables. To prepare clean analytics datasets, we use joins to merge them. Joins not only connect data but also help detect missing records, mismatches, and duplicates. If you’ve practiced with our Pandas data cleaning guide, this section feels very similar — but with SQL.
📊 Step 1: Create Tables & Insert Data
CREATE TABLE Customers (
cust_id INT,
cust_name VARCHAR(50)
);
INSERT INTO Customers VALUES
(101, 'Amit'),
(102, 'Priya'),
(103, 'Rohit'),
(104, 'Sneha');
CREATE TABLE Orders (
order_id INT,
cust_id INT,
amount DECIMAL(10,2)
);
INSERT INTO Orders VALUES
(1, 101, 2500.00),
(2, 101, 3000.00),
(3, 102, 1500.00),
(4, 105, 2000.00); -- 105 not in Customers
✅ The Customers table and Orders table have one mismatch (cust_id 105 not in Customers).
| cust_id | cust_name |
|---|---|
| 101 | Amit |
| 102 | Priya |
| 103 | Rohit |
| 104 | Sneha |
| order_id | cust_id | amount |
|---|---|---|
| 1 | 101 | 2500.00 |
| 2 | 101 | 3000.00 |
| 3 | 102 | 1500.00 |
| 4 | 105 | 2000.00 |
1️⃣ INNER JOIN – Matching Records
SELECT o.order_id, c.cust_name, o.amount
FROM Orders o
INNER JOIN Customers c ON o.cust_id = c.cust_id;
| order_id | cust_name | amount |
|---|---|---|
| 1 | Amit | 2500.00 |
| 2 | Amit | 3000.00 |
| 3 | Priya | 1500.00 |
2️⃣ LEFT JOIN – Find Orders without Customers
SELECT o.order_id, c.cust_name, o.amount
FROM Orders o
LEFT JOIN Customers c ON o.cust_id = c.cust_id;
| order_id | cust_name | amount |
|---|---|---|
| 4 | NULL | 2000.00 |
✅ Detects mismatches like cust_id 105 not in Customers.
3️⃣ RIGHT JOIN – Customers without Orders
SELECT c.cust_name, o.order_id
FROM Customers c
RIGHT JOIN Orders o ON c.cust_id = o.cust_id;
✅ Shows customers missing in Orders table (if any).
4️⃣ FULL OUTER JOIN – All Data with NULLs
SELECT c.cust_name, o.order_id, o.amount
FROM Customers c
FULL OUTER JOIN Orders o ON c.cust_id = o.cust_id;
✅ Useful for audit reports – shows everything, even mismatches.
5️⃣ JOIN + IS NULL – Detect Missing Foreign Keys
SELECT o.order_id, o.cust_id
FROM Orders o
LEFT JOIN Customers c ON o.cust_id = c.cust_id
WHERE c.cust_id IS NULL;
| order_id | cust_id |
|---|---|
| 4 | 105 |
Joining and cleaning across tables ensures data consistency. Detecting mismatches helps prevent orphan records that can mislead reports. These join techniques are critical in data analytics workflows and in Python Pandas projects.
🛡️ Section 13: Data Integrity & Constraint-Based Cleaning in SQL
Instead of cleaning dirty data after it arrives, why not stop bad data at the source? SQL constraints enforce rules of integrity to prevent invalid, duplicate, or missing data. These techniques are crucial in data analyst workflows where quality assurance starts at the database design stage.
📊 Step 1: Create Products Table (with Issues)
CREATE TABLE Products (
product_id INT,
product_name VARCHAR(50),
price DECIMAL(10,2),
category VARCHAR(20)
);
INSERT INTO Products VALUES
(1, 'Laptop', 60000, 'Electronics'),
(1, 'Laptop', 60000, 'Electronics'), -- Duplicate ID
(2, NULL, 1200, 'Stationery'), -- Missing name
(3, 'Pen', -10, 'Stationery'), -- Negative price
(4, 'Shirt', 1500, 'InvalidCat'); -- Wrong category
✅ The Products table has duplicates, NULLs, negative values, and invalid categories.
1️⃣ PRIMARY KEY – Prevent Duplicates
ALTER TABLE Products
ADD CONSTRAINT pk_product PRIMARY KEY(product_id);
❌ Stops duplicate product IDs from being inserted.
2️⃣ UNIQUE – Enforce Uniqueness
ALTER TABLE Products
ADD CONSTRAINT unq_product_name UNIQUE(product_name);
❌ Prevents two products with the same name.
3️⃣ NOT NULL – No Missing Fields
ALTER TABLE Products
ALTER COLUMN product_name VARCHAR(50) NOT NULL;
❌ Ensures every product has a name.
4️⃣ CHECK – Validate Ranges
ALTER TABLE Products
ADD CONSTRAINT chk_price CHECK(price > 0);
❌ Blocks negative prices from being entered.
5️⃣ FOREIGN KEY – Maintain Relationships
ALTER TABLE Products
ADD CONSTRAINT fk_category FOREIGN KEY(category)
REFERENCES Categories(category_name);
❌ Ensures only valid categories (from Categories table) are allowed.
Constraints are like data bodyguards — they prevent invalid records before they even enter your system. Using them reduces manual cleaning effort and ensures reliable datasets. This approach is vital in business analytics where decisions rely on high-quality data.
⚡ Section 14: Indexing & Performance-Aware Cleaning in SQL
When datasets grow huge, even simple cleaning operations like
DELETE, DISTINCT, or UPDATE can become slow and expensive.
SQL indexing ensures faster lookups, duplicate detection, and cleaning operations.
Think of it as shortcuts for your database.
If you’ve read our
predictive analytics guide,
you already know performance and efficiency directly affect insights.
📊 Step 1: Create Table with Duplicates
CREATE TABLE LargeSales (
sale_id INT,
customer_id INT,
amount DECIMAL(10,2)
);
INSERT INTO LargeSales VALUES
(1, 101, 2500.00),
(2, 102, 3000.00),
(3, 103, 1800.00),
(4, 101, 2500.00), -- duplicate customer
(5, 104, 2200.00);
✅ The LargeSales table has duplicate customer_ids and needs optimization.
1️⃣ CREATE INDEX – Faster Lookups
CREATE INDEX idx_customer
ON LargeSales(customer_id);
✅ Speeds up duplicate detection queries like SELECT DISTINCT or GROUP BY customer_id.
2️⃣ UNIQUE INDEX – Prevent Duplicates
CREATE UNIQUE INDEX unq_customer
ON LargeSales(customer_id);
❌ Blocks insertion of duplicate customer IDs at the database level.
3️⃣ CLUSTERED INDEX – Organize Data
CREATE CLUSTERED INDEX cl_idx_sales
ON LargeSales(sale_id);
✅ Stores rows physically by sale_id, improving query speed for sequential cleaning tasks.
4️⃣ NONCLUSTERED INDEX – Flexible Filtering
CREATE NONCLUSTERED INDEX ncl_idx_amount
ON LargeSales(amount);
✅ Helps when cleaning unusual numeric values like outliers in amount.
5️⃣ DROP INDEX – Optimize Bulk Cleaning
DROP INDEX idx_customer ON LargeSales;
✅ Dropping indexes before bulk DELETE or UPDATE speeds up cleaning, then recreate them later.
Indexes are like shortcuts for your database. They enforce uniqueness, accelerate duplicate removal, and make cleaning large datasets practical. For data analysts working with big datasets, mastering indexing ensures both accuracy and speed.
🔄 Section 15: Data Normalization & Standardization in SQL
Raw datasets often contain inconsistent spellings, cases, and formats.
For example: India, india, IN may all appear in the same column.
SQL provides functions to normalize and standardize values,
ensuring data is clean, consistent, and ready for analysis.
These techniques are widely used in
data analytics projects.
📊 Step 1: Create Table & Insert Data
CREATE TABLE CustomersNorm (
cust_id INT,
country VARCHAR(50),
gender VARCHAR(10)
);
INSERT INTO CustomersNorm VALUES
(1, ' India ', 'M'),
(2, 'india', 'male'),
(3, 'INDIA', 'F'),
(4, 'USA', 'Female'),
(5, 'U.S.A', 'f');
✅ The CustomersNorm table has inconsistent cases, spaces, abbreviations, and gender formats.
1️⃣ TRIM() – Remove Extra Spaces
SELECT cust_id, TRIM(country) AS clean_country
FROM CustomersNorm;
| Before | After |
|---|---|
| ” India “ | “India” |
2️⃣ UPPER()/LOWER() – Fix Case
SELECT cust_id, UPPER(country) AS norm_country
FROM CustomersNorm;
| Before | After |
|---|---|
| “india” | “INDIA” |
3️⃣ REPLACE() – Standardize Abbreviations
SELECT cust_id,
REPLACE(country, 'U.S.A', 'USA') AS clean_country
FROM CustomersNorm;
| Before | After |
|---|---|
| “U.S.A” | “USA” |
4️⃣ CASE WHEN – Map Gender Values
SELECT cust_id,
CASE
WHEN gender IN ('M','male') THEN 'Male'
WHEN gender IN ('F','female') THEN 'Female'
END AS norm_gender
FROM CustomersNorm;
| Before | After |
|---|---|
| “M” | “Male” |
| “f” | “Female” |
5️⃣ JOIN Reference Table – Enforce Standards
-- Assuming we have a CountryReference table
SELECT c.cust_id, r.country_name
FROM CustomersNorm c
JOIN CountryReference r
ON UPPER(c.country) = UPPER(r.country_alias);
✅ Ensures only valid country names from a reference table are used.
Normalization ensures that different spellings and formats mean the same thing. By standardizing values, analysts prevent duplicate categories and improve data accuracy. This step is vital in data analytics workflows where consistent values lead to more reliable insights.
⏰ Section 16: Date & Time Cleaning in SQL
Dates in datasets often come in mixed formats, with NULLs or invalid values. Cleaning them ensures accurate time-series analysis, forecasting, and reporting. SQL provides built-in functions to standardize dates and extract useful parts. If you’ve read our linear regression guide, you know how important clean dates are for trend analysis.
📊 Step 1: Create Table & Insert Data
CREATE TABLE Transactions (
trans_id INT,
trans_date VARCHAR(20),
amount DECIMAL(10,2)
);
INSERT INTO Transactions VALUES
(1, '2025-01-05', 2500.00),
(2, '05/02/2025', 3000.00),
(3, 'March 10, 2025', 1800.00),
(4, NULL, 2200.00),
(5, 'invalid_date', 1500.00);
✅ The Transactions table has mixed date formats, NULLs, and invalid values.
1️⃣ CAST/CONVERT – Standardize Format
SELECT trans_id,
CONVERT(DATE, trans_date, 105) AS clean_date
FROM Transactions;
✅ Converts '05/02/2025' into '2025-02-05' (YYYY-MM-DD format).
2️⃣ TRY_CONVERT – Safe Conversion
SELECT trans_id,
TRY_CONVERT(DATE, trans_date) AS safe_date
FROM Transactions;
✅ Invalid dates (like 'invalid_date') return NULL instead of an error.
3️⃣ DATEPART() – Extract Components
SELECT trans_id,
DATEPART(YEAR, TRY_CONVERT(DATE, trans_date)) AS year,
DATEPART(MONTH, TRY_CONVERT(DATE, trans_date)) AS month
FROM Transactions;
✅ Extracts year and month for time-based grouping.
4️⃣ DATEDIFF() – Calculate Durations
SELECT trans_id,
DATEDIFF(DAY, TRY_CONVERT(DATE, trans_date), GETDATE()) AS days_old
FROM Transactions;
✅ Calculates how many days old each transaction is.
5️⃣ COALESCE – Replace NULL Dates
SELECT trans_id,
COALESCE(TRY_CONVERT(DATE, trans_date), '2025-01-01') AS final_date
FROM Transactions;
✅ Fills missing/invalid dates with a default date.
Cleaning dates and timestamps is essential for reliable time-series insights. These SQL techniques ensure consistent formats, safe conversions, and complete values. They are widely used in forecasting, reporting, and machine learning models where accurate dates drive predictions.
🚨 Section 17: Outlier Detection & Cleaning in SQL
Outliers can distort averages, create misleading insights, and break machine learning models. SQL offers multiple ways to detect and clean outliers using statistics and conditions. If you’ve read our data science guide, you know outlier handling is a must before model training.
📊 Step 1: Create Table with Outliers
CREATE TABLE SalesOutliers (
sale_id INT,
amount DECIMAL(10,2)
);
INSERT INTO SalesOutliers VALUES
(1, 2500.00),
(2, 2600.00),
(3, 2700.00),
(4, 100000.00), -- Extreme high outlier
(5, 150.00), -- Extreme low outlier
(6, 2800.00),
(7, 2900.00);
✅ The SalesOutliers table has one extremely high and one extremely low value.
1️⃣ AVG + STDEV – Z-Score Method
SELECT sale_id, amount
FROM SalesOutliers
WHERE ABS(amount - (SELECT AVG(amount) FROM SalesOutliers))
< 3 * (SELECT STDEV(amount) FROM SalesOutliers);
✅ Removes values outside 3 standard deviations.
2️⃣ IQR Filtering – Boxplot Method
WITH Quartiles AS (
SELECT
PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY amount) AS Q1,
PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY amount) AS Q3
FROM SalesOutliers
)
SELECT s.*
FROM SalesOutliers s, Quartiles q
WHERE s.amount BETWEEN (Q1 - 1.5*(Q3-Q1)) AND (Q3 + 1.5*(Q3-Q1));
✅ Filters out values beyond the IQR range.
3️⃣ PERCENTILE_CONT – Winsorization
SELECT PERCENTILE_CONT(0.05) WITHIN GROUP (ORDER BY amount) AS p05,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY amount) AS p95
FROM SalesOutliers;
✅ Identifies 5th–95th percentile cutoffs for capping extreme values.
4️⃣ CASE WHEN – Cap Outliers
SELECT sale_id,
CASE
WHEN amount > 5000 THEN 5000
WHEN amount < 500 THEN 500
ELSE amount
END AS capped_amount
FROM SalesOutliers;
✅ Caps outliers to a safe range (500–5000).
5️⃣ DELETE – Remove Outliers Permanently
DELETE FROM SalesOutliers
WHERE amount > 5000 OR amount < 500;
✅ Deletes extreme records completely (use with caution).
Handling outliers ensures more stable averages, cleaner visuals, and accurate models. Depending on the business case, you can remove, cap, or transform extreme values. This step is critical in data science workflows where outliers often make or break model performance.
🔁 Section 18: Data Deduplication Across Tables in SQL
When merging datasets from different sources, duplicate records across tables are very common. SQL provides set operations and joins to detect, remove, and consolidate duplicates. This ensures analysts work with unique, high-quality records. If you’ve read our 7 steps of data analysis, deduplication comes right after data collection.
📊 Step 1: Create Tables with Overlap
CREATE TABLE Customers_A (
cust_id INT,
cust_name VARCHAR(50)
);
INSERT INTO Customers_A VALUES
(1, 'Amit'),
(2, 'Priya'),
(3, 'Rohit');
CREATE TABLE Customers_B (
cust_id INT,
cust_name VARCHAR(50)
);
INSERT INTO Customers_B VALUES
(2, 'Priya'),
(3, 'Rohit'),
(4, 'Sneha');
✅ Both tables contain overlapping records for Priya and Rohit.
1️⃣ UNION – Remove Duplicates Across Tables
SELECT cust_id, cust_name FROM Customers_A
UNION
SELECT cust_id, cust_name FROM Customers_B;
✅ Combines both tables but keeps unique records only.
2️⃣ UNION ALL + GROUP BY – Find True Duplicates
SELECT cust_id, cust_name, COUNT(*) AS duplicate_count
FROM (
SELECT cust_id, cust_name FROM Customers_A
UNION ALL
SELECT cust_id, cust_name FROM Customers_B
) t
GROUP BY cust_id, cust_name
HAVING COUNT(*) > 1;
✅ Identifies which records appear in both tables.
3️⃣ EXCEPT/MINUS – Find Non-Matching Records
SELECT cust_id, cust_name FROM Customers_A
EXCEPT
SELECT cust_id, cust_name FROM Customers_B;
✅ Shows records that exist in Customers_A only.
4️⃣ LEFT JOIN + IS NULL – Detect Missing Matches
SELECT a.cust_id, a.cust_name
FROM Customers_A a
LEFT JOIN Customers_B b
ON a.cust_id = b.cust_id
WHERE b.cust_id IS NULL;
✅ Finds records in A but not in B (non-overlaps).
5️⃣ INSERT DISTINCT – Merge Clean Data
INSERT INTO MasterCustomers (cust_id, cust_name)
SELECT DISTINCT cust_id, cust_name
FROM (
SELECT * FROM Customers_A
UNION
SELECT * FROM Customers_B
) t;
✅ Inserts only unique records into the master table.
Deduplication ensures one record = one entity, even if data comes from multiple sources. It prevents double-counting and improves the accuracy of reports and dashboards. This step is a must in data analysis pipelines before joining data with other business tables.
🔤 Section 19: Data Type Conversion & Cleaning in SQL
Datasets often have values stored in the wrong data type: numbers saved as text, or dates written as strings. This causes errors in calculations and reporting. SQL provides conversion functions to clean and standardize data. If you’ve read our neural network blog, you’ll know that even advanced models require correct data types to function properly.
📊 Step 1: Create Table with Mixed Types
CREATE TABLE MixedData (
record_id INT,
amount_text VARCHAR(20),
date_text VARCHAR(20)
);
INSERT INTO MixedData VALUES
(1, '2500.50', '2025-01-05'),
(2, '3000', '05/02/2025'),
(3, 'invalid_num', 'March 10, 2025'),
(4, NULL, 'invalid_date');
✅ The MixedData table has numbers stored as text and inconsistent date formats.
1️⃣ CAST – Basic Conversion
SELECT record_id,
CAST(amount_text AS DECIMAL(10,2)) AS clean_amount
FROM MixedData;
✅ Converts '2500.50' (text) into 2500.50 (decimal).
2️⃣ CONVERT – Date Conversion
SELECT record_id,
CONVERT(DATE, date_text, 105) AS clean_date
FROM MixedData;
✅ Converts '05/02/2025' into '2025-02-05' (standard format).
3️⃣ TRY_CAST – Safe Conversion
SELECT record_id,
TRY_CAST(amount_text AS DECIMAL(10,2)) AS safe_amount
FROM MixedData;
✅ Invalid numbers ('invalid_num') become NULL instead of causing errors.
4️⃣ TRY_CONVERT – Safe Date Conversion
SELECT record_id,
TRY_CONVERT(DATE, date_text) AS safe_date
FROM MixedData;
✅ Invalid dates ('invalid_date') safely return NULL.
5️⃣ PARSE – Complex Conversions
SELECT record_id,
PARSE(date_text AS DATE USING 'en-US') AS parsed_date
FROM MixedData;
✅ Converts 'March 10, 2025' into a proper DATE field.
With correct data types, analysts can perform calculations, joins, and models reliably. Type conversion is a critical step before analytics or machine learning, where incorrect formats can cause errors or wrong predictions.
✅ Section 20: Data Validation Queries in SQL
Data validation ensures that records follow business rules before they are used for analytics. Using SQL, analysts can easily detect invalid, missing, or inconsistent values. This step is critical in business analysis, where data quality directly impacts decision-making.
📊 Step 1: Create Table with Invalid Records
CREATE TABLE SalesValidation (
sale_id INT,
product_name VARCHAR(50),
amount DECIMAL(10,2),
category VARCHAR(20),
sale_date DATE
);
INSERT INTO SalesValidation VALUES
(1, 'Laptop', 50000, 'Electronics', '2025-01-15'),
(2, NULL, 1500, 'Stationery', '2025-02-05'), -- Missing product name
(3, 'Pen', -10, 'Stationery', '2025-02-10'), -- Negative amount
(4, 'Shirt', 2000, 'InvalidCat', '2025-03-01'),-- Wrong category
(5, 'Book', 800, 'Stationery', '2030-01-01'); -- Future date
✅ The SalesValidation table has NULLs, negatives, wrong categories, and future dates.
1️⃣ IS NULL – Detect Missing Fields
SELECT * FROM SalesValidation
WHERE product_name IS NULL;
✅ Finds records where product_name is missing.
2️⃣ CASE WHEN – Check for Negative Values
SELECT sale_id, amount,
CASE WHEN amount < 0 THEN 'Invalid' ELSE 'Valid' END AS status
FROM SalesValidation;
✅ Flags sales with negative amounts.
3️⃣ NOT IN – Validate Allowed Categories
SELECT * FROM SalesValidation
WHERE category NOT IN ('Electronics', 'Stationery', 'Clothing');
✅ Finds products with invalid categories.
4️⃣ BETWEEN – Detect Out-of-Range Values
SELECT * FROM SalesValidation
WHERE amount NOT BETWEEN 1 AND 100000;
✅ Ensures amount is within expected range.
5️⃣ Date Validation – No Future Dates
SELECT * FROM SalesValidation
WHERE sale_date > GETDATE();
✅ Detects future transaction dates.
Validation queries act like data quality checkpoints. They ensure values match business expectations before being used in reports. For business analysts, mastering these checks is key to delivering trustworthy insights.
📢 Master SQL & Data Analytics with Vista Academy
You’ve just explored 100+ SQL commands for data cleaning. Ready to take your skills further? Join Vista Academy, Dehradun for hands-on Data Analytics & SQL Training with real-world projects. Build a job-ready portfolio and become an in-demand analyst in 2025. 🚀
👉 Enroll Now – Start Your Data Analytics Journey