
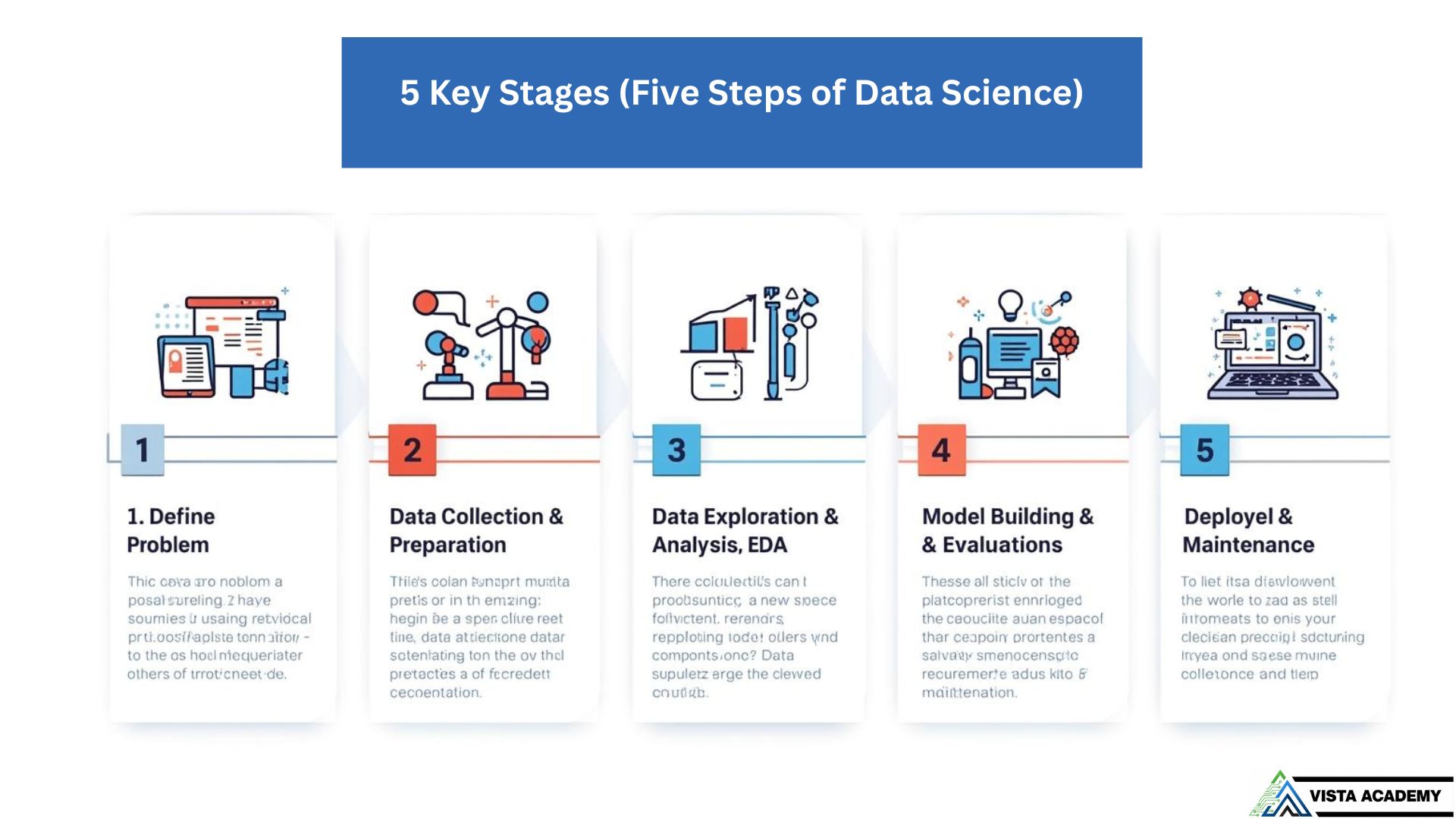
1. Define the Problem
Start with a clear business question. Identify stakeholders, success metrics (KPIs), constraints and the expected impact. A well-defined problem prevents wasted effort later.
- What decision must this model inform?
- Who will use the output and how will success be measured?
2. Data Collection & Preparation
Gather data from product logs, databases, APIs or external sources. Then clean, handle missing values, and document lineage. This phase is critical — many searchers ask where cognitive empathy matters, and it matters most here.
Tip: Add a data dictionary and note sources for reproducibility.
3. Data Exploration & Analysis (EDA)
Explore distributions, correlations and outliers. Visualize patterns and check for bias. EDA helps form better modeling strategies and uncovers data quality issues early.
4. Model Building & Evaluation
Choose algorithms, train with cross-validation, and evaluate using relevant metrics. Compare baseline models and include explainability checks before selecting the final model.
5. Deployment & Maintenance
Deploy to production, monitor performance, set up alerts, and retrain on new data. Consider rollback plans and user feedback loops to keep your solution effective.